Python提取Excel行数据
用余生去守护 人气:10一、需求描述
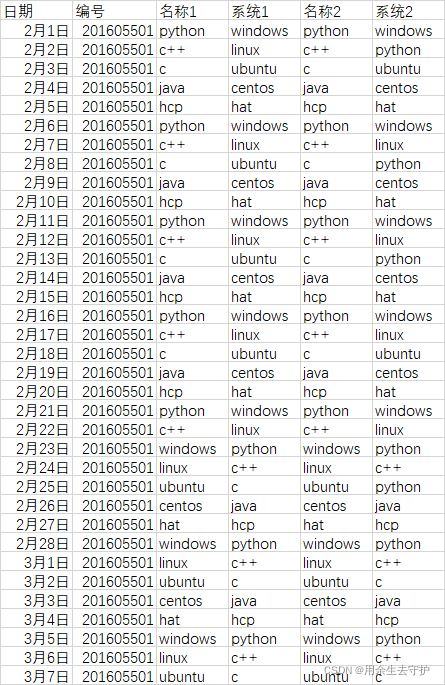
1.图片展示
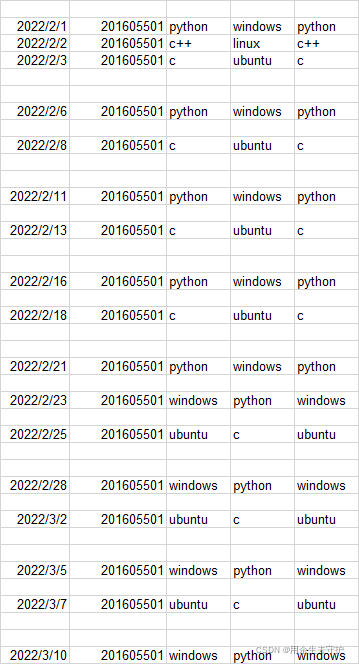
从如图所示的数据中提取含有"python"、"ubuntu"关键词的所有行数据,其它的不提取:
备注: 关键词和数据行列数可自定义!!!
提取前:
提取后:
2.提取方法
代码如下(示例):
import xlrd
import xlwt
data = xlrd.open_workbook(r'shuju.xlsx')
rtable = data.sheets()[0]
wbook = xlwt.Workbook(encoding='utf-8',style_compression = 0)
wtable = wbook.add_sheet('sheet1',cell_overwrite_ok = True)
count = 0
keyword = ('python')
keyword1 = ('ubuntu') #可添加多个关键词
for i in range(0,40): #区域按数据包含的行数进行填写,过多会显示超出范围(out of range)
if rtable.cell(i,2).value == keyword or rtable.cell(i,3).value == keyword or rtable.cell(i,4).value == keyword or rtable.cell(i,5).value == keyword or rtable.cell(i,2).value == keyword1 or rtable.cell(i,3).value == keyword1 or rtable.cell(i,4).value == keyword1 or rtable.cell(i,5).value == keyword1:
for j in range(0,5):
wtable.write(i,j,rtable.row_values(i)[j])
count += 1
print (count)
wbook.save(r'medicaldata.xls')
缺点:需要手动删除空白,容易出现超出范围错误!!
二、python提取第二版
1.图片展示
提取前:
提取后:
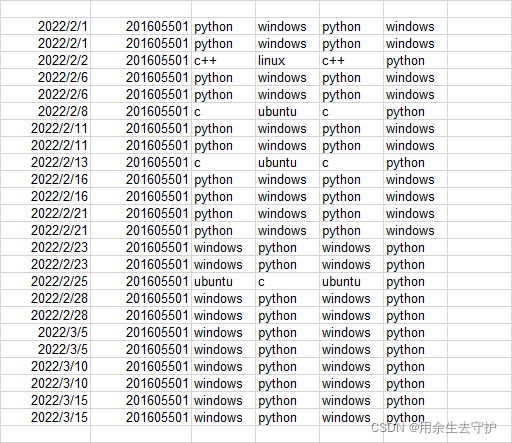
2.提取方法
代码如下(示例):
import os
import xlwt
import xlrd
from openpyxl import load_workbook
##目的文件夹
dirpath=r'E:\py\python3.7\test\test89tiqu'
keyword='python'
##遍历函数
def files(dirpath, suffix=['.xls', 'xlsx']):
for root ,dirs ,files in os.walk(dirpath):
for name in files:
if name.split('.')[-1] in suffix:
yield os.path.join(root, name)
if __name__ == '__main__':
jieguo = xlwt.Workbook(encoding="ascii") #生成excel
wsheet = jieguo.add_sheet('sheet name') #生成sheet
y=0 #生成的excel的行计数
try:
file_list = files(dirpath)
for filename in file_list:
workbook = xlrd.open_workbook(filename) #读取源excel文件
print(filename)
sheetnum=workbook.nsheets #获取源文件sheet数目
for m in range(0,sheetnum):
sheet = workbook.sheet_by_index(m) #读取源excel文件第m个sheet的内容
nrowsnum=sheet.nrows #获取该sheet的行数
for i in range(0,nrowsnum):
date=sheet.row(i) #获取该sheet第i行的内容
for n in range(0,len(date)):
aaa=str(date[n]) #把该行第n个单元格转化为字符串,目的是下一步的关键字比对
print(aaa)
if aaa.find(keyword)>0: #进行关键字比对,包含关键字返回1,否则返回0
y=y+1
for j in range(len(date)):
wsheet.write(y,j,sheet.cell_value(i,j)) #该行包含关键字,则把它所有单元格依次写入入新生成的excel的第y行
jieguo.save('jieguo.xls') #保存新生成的Excel
except Exception as e:
print(e)
jieguo.save('jieguo.xls') #保存新生成的Excel
加载全部内容