Mysql检索语句DQL
祈祷ovo 人气:11.简单检索数据
博客内容中student表为:
1.1.检索单个列
select + 列名 + from + 表名
1.2.检索多个列
select + 列名1,列名2,列名3......列n + from + 表名
1.3.检索所有列
select + *(表示通配符) +from + 表名
1.4.检索不同的行
使用distinct关键字
select + distinct + 列名 + from + 表名
举个例子:我们想要查询一个班级学生的性别有多少种,那么就不需要把每一个同学的性别都显示出来,只需要把不同性别显示出来就行即distinct返回唯一值
这里有一个注意点,distinct关键字应用于所有列前,不仅仅是前置它的列,如果给出两个列,那么除非指定的两个列都不同,否则所有的行都会被检测出来
1.5.限制检索结果
使用limit关键字
selet + 列名 + from + 表名 + limit + 数字
我们平时select语句返回匹配的行数,我们可以使用limit来限定返回的行数,比如select结果可以返回10行,我们只要前5行,那么就可以使用limit后边参数为5,如果select返回4行,而limit限制的是5行,那么会返回4行。当然limit后边的参数可以有两个,有两种写法
即:
1.selet + 列名 + from + 表名 + limit + 数字1,数字2
2.selet + 列名 + from + 表名 + limit + 数字2 + offset + 数字1
意思是从数字1所代表的行数开始,检索数字2行,第二种写法是在MySQL5之后才支持的
注意检索的第一行为行0,而不是1
1.6.使用完全限制的表名检索
select + 表名.列名 + from + 数据库名.表名
2.排序检索数据
2.1.基本语法
使用order by关键字
select + 列名(可以多个列) + from + 表名 + order by + 列名
两个列名可以不一样
我们日常都可以对员工的工资进行排序,但是有的员工工资一样,这样我们可以在员工工资一样的基础上对年龄等进行排序,这就是按照多个列进行排序
即:
select + 列名(可以多个列) + from + 表名 + order by + 列1,列2
意思是在列1一致的情况下按照列2进行排序,如果列1不一致那么就不会按照列2排序
2.2.指定排序方向
上面我们讲到的排序其实都是默认排序,默认是按照升序(字母按'A'到‘Z‘,数字从小到大)
我们一样可以降序排列
使用desc关键字
select + 列名(可以多个列) + from + 表名 + order by + 列名 desc
那么多个排序规则咋办呢,即我们把一个班的同学按照总分进行降序排序,那么总分一样的按照语文成绩也降序排列,这里我们注意
desc关键字只应用到直接位于其前面的列
所有当我们需要按照多个字段排序只需要在对应字段后边写上对应的排序规则,那么比如我们需要两个字段都降序:
select + 列名(可以多个列) + from + 表名 + order by + 列名1 desc,列名2 desc
其实升序的话我们不用写,因为默认是升序,关键字是asc
按照上边学的,我们做一个例子:
列出年龄最大的学生的姓名性别和数学成绩:
select sname,ssex,smath from student ORDER BY sage desc LIMIT 1
注意order by和limit的位置顺序
3.检索过滤数据
3.1使用简单where子句
select + 列名 + from + 表名 where + 判断条件
where一个特殊操作符:
1.
<>:不等于,其实和!=是一样的
2.between:和and连用表示在指定的两个值之间例如:select age from student where age between 18 and 20
where进行空值检查:
select + 列名 + from + 表名 + where + 列名 + is null
注意这里用到的是is不是=
3.2组合where子句
| 操作符 | 作用 |
|---|---|
| and | 要同时满足and左右两边的条件 |
| or | 满足or一边的条件就行 |
| in | 用来指定条件范围 |
| not | 用来否定条件里边的内容 |
作用and要同时满足and左右两边的条件or满足or一边的条件就行in用来指定条件范围not用来否定条件里边的内容
拿student表来举例子:
1.and:我们查找女生中数学超过90分的学生的所有信息
SELECT * FROM student where ssex=“女” and smath>90
2.or:我们查找年龄大于19岁学生的姓名,或者英语成绩大于90的学生姓名
SELECT sname FROM student where sage>19 or senglish>90
3.in:我们查找年龄为18和19岁学生的姓名
select sname from student where sage in(18,19)
4.not:我们查找除了年龄为18和19岁学生的姓名
select sname from student where sage not in(18,19)
5.我们查找年龄不是20岁的学生的所有信息并且把他们按照数学成绩降序排列,只要第二行的内容:
select * from student where sage not in(20) GROUP BY smath desc LIMIT 1,1
我们注意他们各个关键字的顺序和limit后边参数代表的含义
3.3使用通配符
通配符:用来匹配值的一部分的特殊符号
like: 根据通配符匹配而不是直接相等匹配进行比较
| 通配符 | 作用 |
|---|---|
| % | 表示任何字符出现的任意的次数 |
| _ | 匹配单个字符串长度 |
拿student表来举例子:
1.%:我们查找姓名里边带花的同学的所有信息
select * from student where sname like “%花%”
会有两条结果翠花和如花似玉,%只会匹配一侧(不限字符串长度),如果只是“%花”,那么如花似玉就不会被查找出来。当然,我们想要查找如花似玉也可以这么来查:
select * from student where sname like “%花%玉”
2._:我们查找如花似玉这名优秀的同学:
select * from student where sname like “_花_玉”
%能匹配0个字符和不限长度的字符串,而_只能而且必须匹配1个字符
4.使用正则表达式检索数据
正则表达式是用来匹配文本的特殊串,将一个模式(正则表达式)与一个文本串进行比较
正则表达式常用符号:
| 符号 | 符号作用 |
|---|---|
| . | 匹配单个字符 |
| | | 相当于或的意思 |
| […] | 或的另一种表现形式 |
| - | 表示匹配范围 |
| \\ | 匹配特殊字符 |
| * | 0个或者多个匹配 |
| + | 1个或多个匹配等于{1,} |
| ? | 0个或者一个匹配等于{0,1} |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围m不超过255 |
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [[ :<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
关键字:regexp
select + 列名(可以多个列) + from + 表名 + where + 列名 + regexp + 正则表达式
拿student表来说:
1 . 先说日regexp和like的区别
like匹配整个串然而regexp则是匹配子串
举个例子:
我们用like匹配别为1的学生的姓名
select sname from student where othername like “1”
结果:
风姐
我们把like换成regexp:
select sname from student where othername regexp “1”
结果:
翠花
凤姐
秋香
现在是不是对区别有了很明显的认识 2 ..就是匹配任意一个字符
举个例子,我们查找语文成绩个位数为8的同学的名字:
select sname from student where schinese regexp “.8”
结果:
凤姐
秋香
3.|
举个例子我们查找别名中含1 ton或2的同学的姓名
select sname from student where othername regexp “1 ton|2”
查找结果:
翠花
旺财
如花似玉
4.[....]
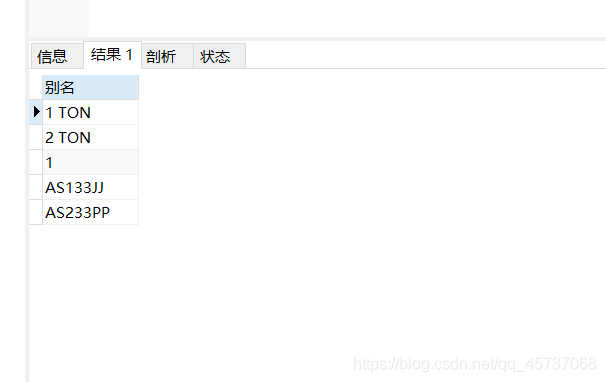
举个例子,我们查找别名为1 ton或者2 ton的学生的姓名
select sname from student where othername regexp “[1|2] ton”
运行结果:
翠花
旺财
其实上边就等同于select sname from student where othername regexp “1 ton|2 ton”
也等同于select sname from student where othername regexp “[12] ton” 5.-
举个例子,查找别名中含有小写英文字母的同学的姓名
select sname from student where othername regexp “[a-z]”
运行结果:
翠花
旺财
秋香
如花似玉
6.\\
举个例子我们查找别名中含有.这个字符的同学的姓名
select sname from student where othername regexp “\\.”
查找结果;
无
我们所接触的特殊符号\,[,],等等都可以用\\来转义
7.?我们不拿student表举例子,把书上的例子拿过来:

注意这一句话:?匹配它前面的任何字符的0次和1次
8 .{n}再拿书上的一个例子(其他的几个大括号同理):

这里有一个匹配字符类:

9.^还是书上的例子:

当然^不止可以指串的开始,还可以在集合中(就是[]中)表示否定含义
为表示否定含义举个例子:
[^a-z]:意思是匹配不是a-z的字符
我们拿student表举例子:查找别名不是以a和1开头的同学的名字
select sname from student where othername regexp “^[^a1]”
第一个^限制开头,第二个^表示否定
10.补充一点,不大小写查询
关键字:binary
我们平时查询的字符串都会忽略大小写,所以,可以使用binary不忽略大小写
select + 列名(可以多个列) + from + 表名 + where + 列名 + regexp + binary + 正则表达式
其余的重要程度没那么高,自己试吧
5.检索计算字段
5.1使用拼接字段
使用concat(str1,str2,....)函数
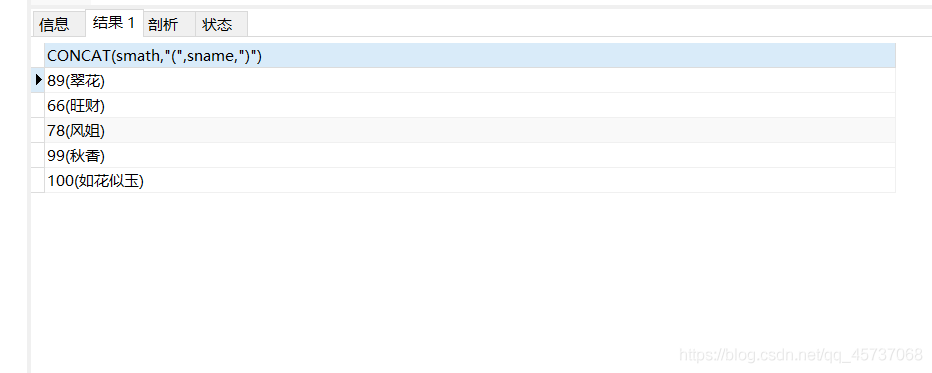
举个例子如果数学老师有这种请求,就是把所有学生的数学成绩打印出来并且打印格式为数学成(姓名) 这种格式那么可以
select concat(smath,"(",sname,")") from student
运行结果:
5.2使用别名
关键字:AS
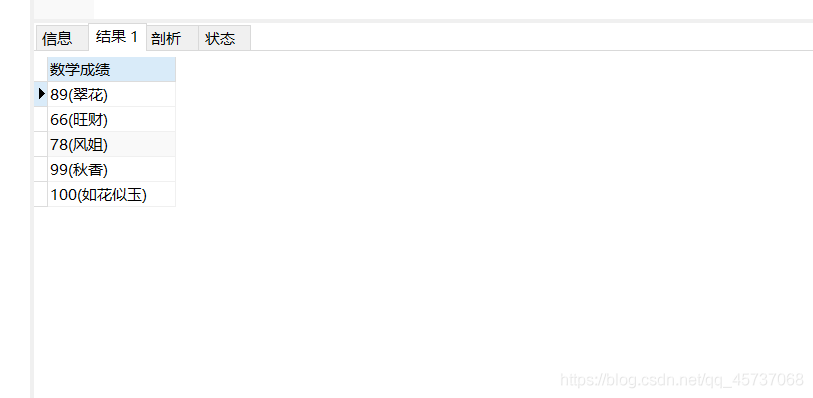
用5.1的例子
SELECT CONCAT(LTRIM(smath),"(",sname,")") AS “数学成绩” from student
结果:
AS可以不加,以上例子也可以写成
SELECT CONCAT(LTRIM(smath),"(",sname,")") “数学成绩” from student。group by,having,order by后都支持别名
5.3执行算数计算
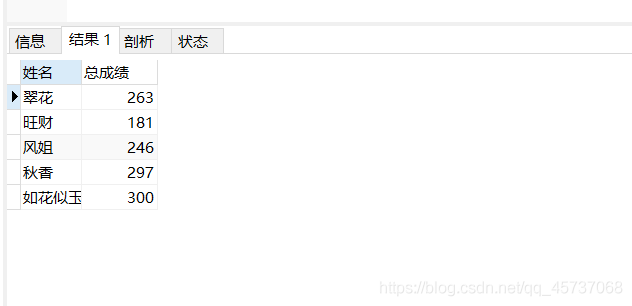
比如我们可以查找每一个同学的总分和该同学的名字:
SELECT sname as “姓名”,smath+schinese+senglish as “总成绩” from student
运行结果:
6.使用函数检索数据
6.1常用文本处理函数:
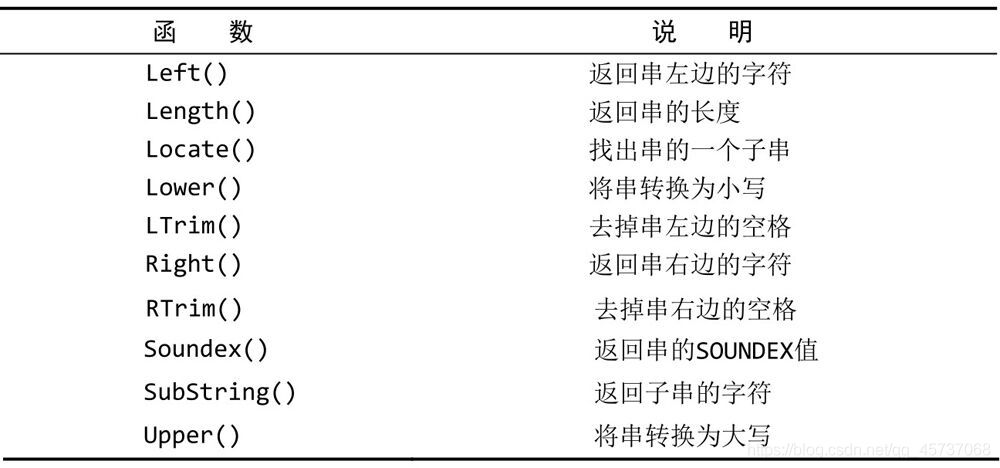
拿upper来举例子,我们把同学的别名使用upper函数查询出来:
SELECT UPPER(othername) as “别名” from student
运行结果:
6.2日期和时间处理函数:
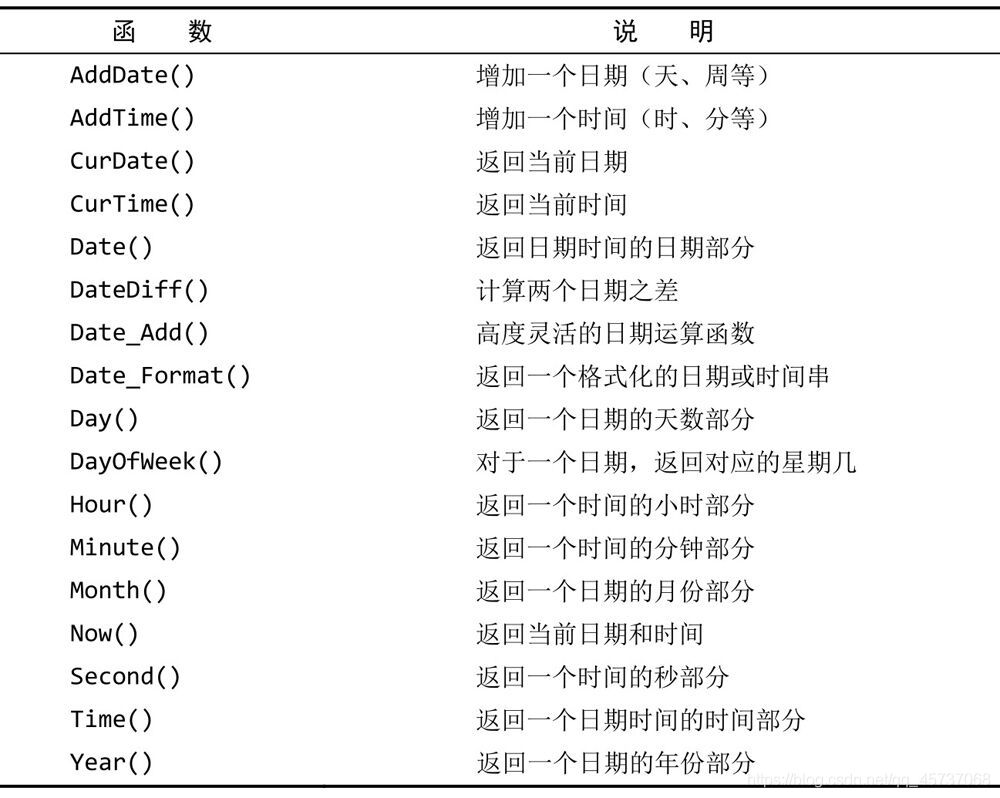
日期的格式:
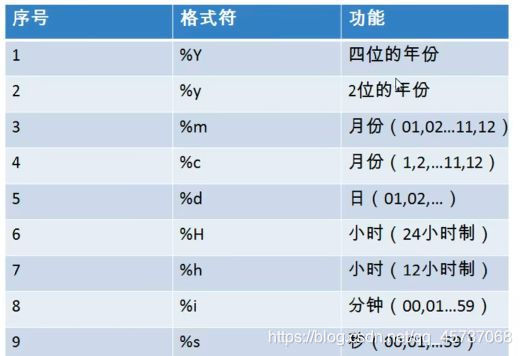
我们拿几个重要的函数举例子:
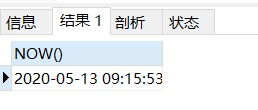
1.now():返回当前系统日期,时间
select now()
运行结果:
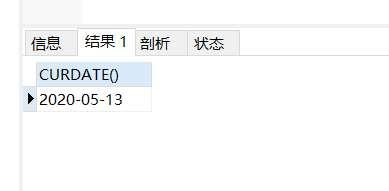
2.curdate():返回当前系统日期,不包含时间
select curdate()
运行结果:
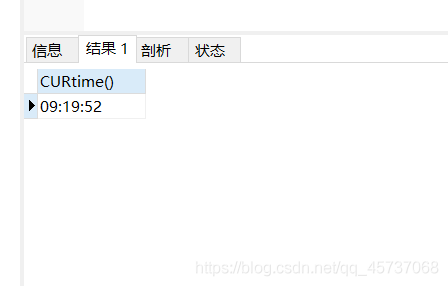
3.curtime():返回当前时间,不包含日期
select curtime()
运行结果:
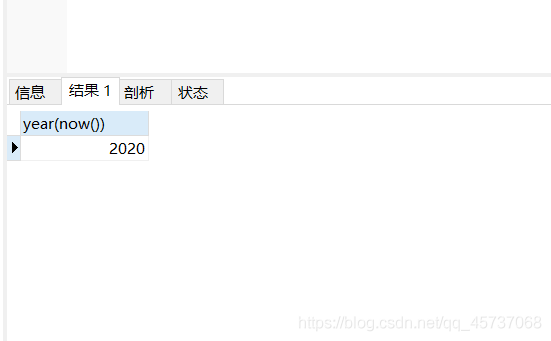
4.YEAR(),Hour()等:获取指定的部分
select year(now())
运行结果:
5.对于date_format()函数
把当前时间转换成字符串:
select DATE_FORMAT(now(),"%Y-%c-%d")
运行结果:
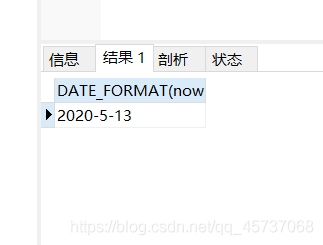
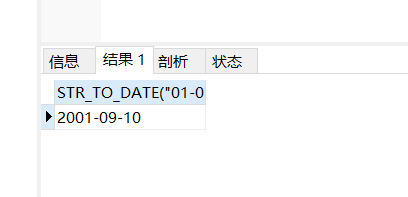
对应的有一个字符串转日期的函数:
例子:
select STR_TO_DATE(“2001-09-10”,"%Y-%c-%d")
运行结果:
6.3数值处理函数:

6.4聚集函数:

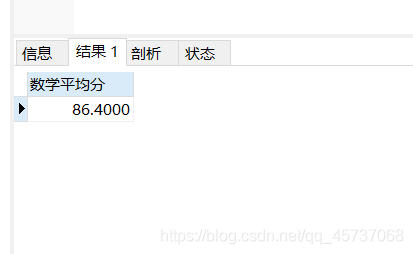
1.AVG()函数
例子:我们拿student表来说,我们查找学生的数学平均分
select avg(smath) as “数学平均分” from student
运行结果:
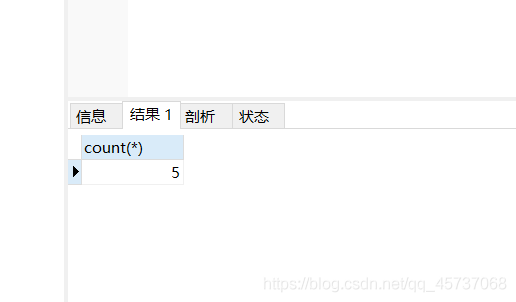
2.COUNT函数
一般的COUNT()函数有两种用法
- 1使用count(*)进行计数,不管列是不是null值
- 2.使用count(column)对特定列中具有的值进行计数,忽略null值
用法的例子:
select count(*) from student
运行结果:
3.指定不同值
关键字distinct
如果我们查找student表中不同的年龄有多少种;
select DISTINCT sage as “年龄种类” from student
运行结果:
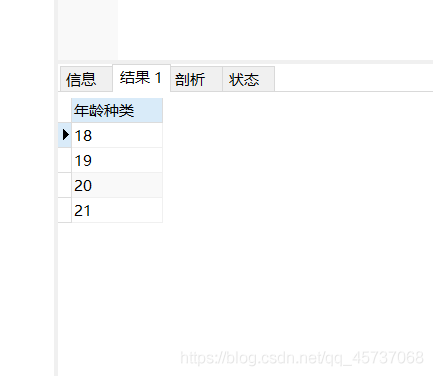
4.注意点
avg(),min(),max(),sum()函数都会忽略空值
7.分组检索数据
7.1.简单分组
关键字group by
我们举个例子:
统计student表里边男生和女生的人数
select ssex,COUNT(*) from student GROUP BY ssex
运行结果:
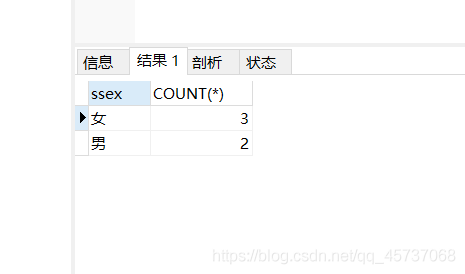
注意点:
1.如果分组里边有null值,那么null做为一个分组返回,如果有多个null值,那么把他们分为一组
2.group by必须用到where子句之后
7.2过滤分组:
就是对简单分组之后的数据再进行过滤
关键字having
举个例子,我们统计student表中数学成绩80分以上的男生人数
select ssex,COUNT(*) from student where smath>80 GROUP BY ssex HAVING ssex=“男”
运行结果:
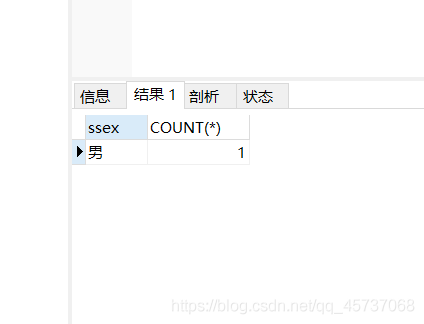
where和having的区别:
where在分组前过滤,having在分组后过滤
8.使用子查询检索数据
8.1子查询简介
1.子查询:出现在其他语句中的语句称为子查询或者内查询
内部镶嵌其他select语句的查询称为外查询或主查询
2.(1)子查询分类:
按子查询出现的位置
select后边+(仅支持标量子查询)
from后面+(支持表子查询)
where或者having后边+(支持标量子查询列子查询行子查询)
exists后边+(表子查询)
2.(2)按结果集的行列数不同:
标量子查询:(结果集只有一行一列)
列子查询:(结果集一列多行)
行子查询:(结果集一般一行多列)
表子查询:(结果集一般为多行多列)
8.2各种子查询举例:
1.where和having后边的子查询:
例子1:我们查询student表中数学分比翠花高的学生的所有信息(标量子查询):
select * from student where smath>(select smath from student where sname=“翠花”)
运行结果:
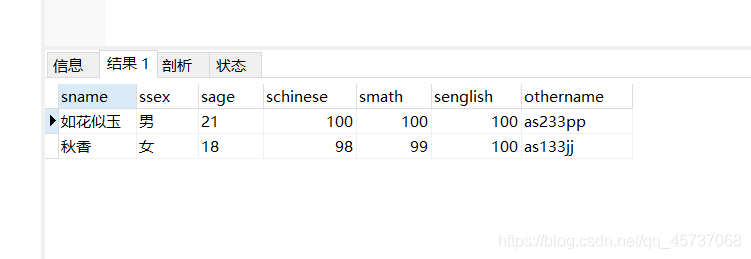
例子2:如果如花似玉这名男生的语数外三科成绩都大于80那么显示所有同学的信息(行子查询):
select * from student where (80,80,80)<(select schinese,smath,senglish from student where sname=“如花似玉”)
运行结果:
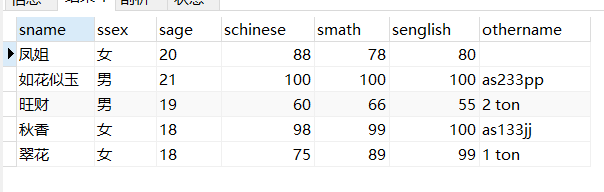
例子3:用where查询女同学的名字(列子查询)(例子比较菜)
SELECT a.sname FROM student a where a.smath in (select smath from student where ssex=“女”)
运行结果:
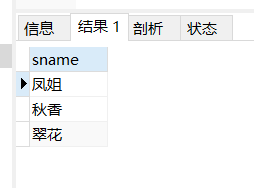
2.select后边的子查询(标量子查询)
我们分别查找同学们的获奖次数:
这里引进一个prize表:
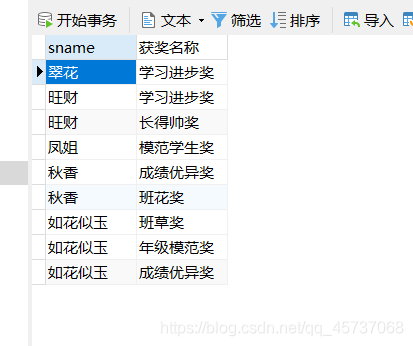
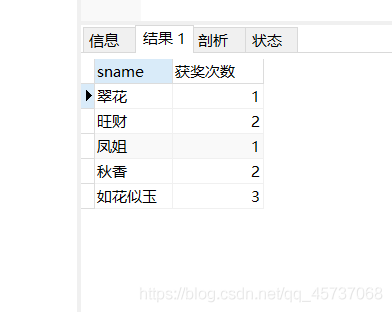
select sname,(select count(*) from prize where student.sname=prize.sname ) as “获奖次数” from student
运行结果:
3.from后边的表子查询:
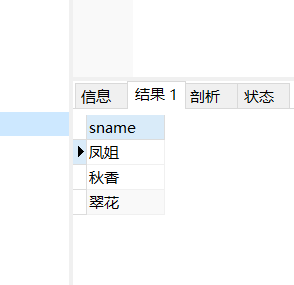
例子:我们查找女生里边数学高于八十分的同学的姓名:
select s.sname from (select * from student where ssex=“女”) as s
运行结果:
4.exists后边的表子查询
exists的作用是判空
例子:我们查询数学成绩为100的学生的姓名
SELECT a.sname FROM student a where EXISTS(select a.smath from student where a.smath=100 )
运行结果:

这里注意不能这么写:
SELECT a.sname FROM student a where EXISTS(select smath from student where smath=100 )
就是没有取别名,这么写是先运行exists里边的select,只要exists里边有一个为真,那么就会查询所有的同学的名字,否则所有的同学的名字都不会查出来,所以如果向上边那么写的话由于数学等于100的有一个同学,其他的都不是100,那么有一个为真就会把同学姓名都查出来,但是用了别名之后就是每一个同学判断一次,判断成功一个输出一个名字
8.3相关子查询
相关子查询:涉及外部查询的子查询
我们查询student表中男生和女生的数学平均分:
select ssex as sssex ,(select avg(smath) FROM student where sssex=student.ssex) as “平均分” from student GROUP BY ssex
运行结果:
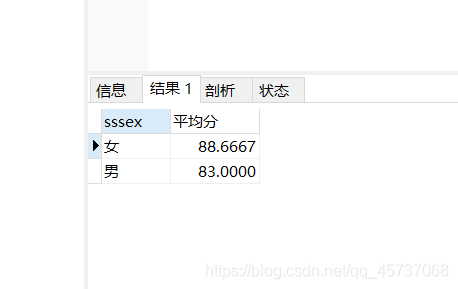
我们可以看到我把第一个ssex起一个别名,第二个用了引用,那么如果我们直接使用ssex=ssex,那么就会出错,相关子查询避免了歧义性
9.连接查询
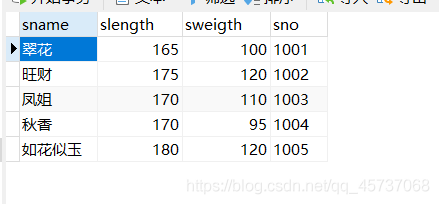
我们在student表基础上添加一个information表代表学生信息(里边有身高体重学号)
9.1连接查询
分类;
连接查询分为内连接和外连接交叉连接
1.内连接:等值连接,非等值连接,自连接
2.外连接:左外连接,右外连接,全外连接
3.交叉连接
1.内连接之等值,非等值连接(sql92版本)
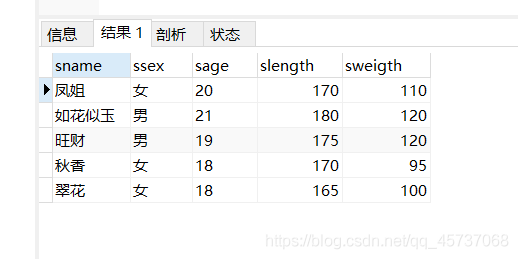
举一个等值连接的例子:结合student表和information表来查询学生的姓名,性别,年龄,身高,体重
select student.sname,ssex,sage,slength,sweigth from student,information where student.sname=information.sname
运行结果:
内连接之等值,非等值连接(sql99版本)
语法:
select + 查询列表 + from 表1 (别名) + (inner)join 表2 (别名) + on 连接条件 + (where)+ (group by) + (having) + (order by)
用sql99语句写出上述sql92版本的例子
select student.sname,ssex,sage,slength,sweigth from student join information on student.sname=information.sname
与sql2语法不同的是两个表之间用join隔开,而且和sql92不同的还有sql92语法是把连接条件和其他筛选条件都放在where中,而sql99这是把连接条件放在on后,其他筛选条件放在where后
2.内连接之自连接(sql92版本):
举一个口头例子:
例子:一张员工表里边有员工编号和领导所对应编号,那么如果要查找员工的名字和它领导的名字就会有
select a.name,b.name from 员工表 a,员工表 b where a.编号=b.领导编号
这里一张表看成了两张表,但是必须给这两张表起别名,不然就会产生歧义必须以这种格式来写
3.内连接之多表等值连接:
select + 查询列表 + from 表1 (别名) + (inner) join 表2 (别名) + on 连接条件 + (inner) join 表3 (别名) + on+连接条件 + (inner) join 表4 (别名) + on 连接条件 + ..... + (where) +(group by) + (having) + (order by)
4.外连接之左外连接:
外连接适用于一个表有另一个表没有的记录
左外连接基本语法:
SELECT + 查询链表 + FROM + 主表 (别名) + LEFT (OUTER) JOIN +从表 (别名) +ON 连接条件右外连接基本语法:
SELECT + 查询链表 + FROM + 从表 (别名) + right (OUTER) JOIN +主表 (别名) +ON 连接条件
外连接特点(左外右外):
1.外连接会查询主表里边的所有记录
2.如果主表有但从表里没有那么就会显示nuil
总的来说外连接=内连接+主表中有从表中没有的数据
我们引进一个新的表abord(student表中学生出国留学次数)
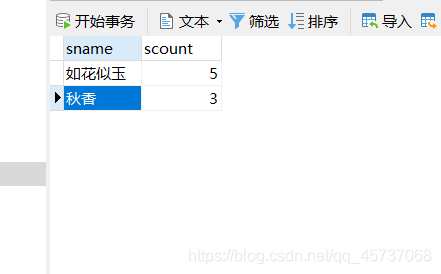
例子:
我们把每一个同学出国留学次数查询出来(我们使用左外连接):
select a.sname,b.scount from student a left JOIN abord b on a.sname=b.sname
运行结果:
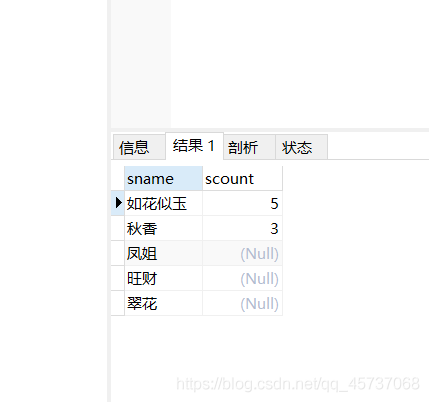
5.全外连接特点
外连接会查询主表与从表里边的所有记录
10.联合查询查询
关键字union
应用场景:当我们查询的信息来自多个表而且多个表之间没有直接连接关系,但查询的字段信息一致(比如两个表都查姓名性别,这样才能合成一张表,而且查询字段要对齐比如两表都查姓名性别,那么第一个select字段的顺序要和第二个select一致都是先姓名后性别或者先性别后姓名)
举个例子:
查找student表中年龄为18和19岁的学生的姓名和性别:
SELECT sname,ssex from student where sage=18 UNION SELECT sname,ssex from student where sage=19
运行结果:
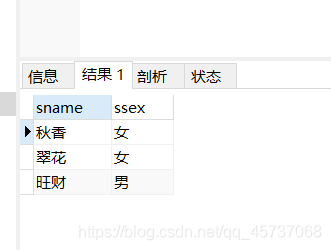
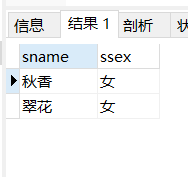
看看去重的效果:我们查询两次年龄为18岁的同学的姓名和性别
SELECT sname,ssex from student where sage=18 UNION SELECT sname,ssex from student where sage=18
运行结果:
但是如果我们用union all的话
SELECT sname,ssex from student where sage=18 UNION all SELECT sname,ssex from student where sage=18
运行结果:
11.子查询
11.1单行子查询
单行子查询,查询结果只能是一行数据,子查询里不能包含order by子句
例子(在emp中查询既不是最高工资也不是最低工资的员工信息):
select empno,ename,sal,from emp where sal>(select min(sal) from emp) and sal<(select max(sal) from emp);
11.2多行子查询
子查询返回多行数据的子查询语句,使用IN或者ANY或者ALL
例子:在emp表中查询工资大于部门编号为10的任意一个员工工资即可的其他部门的员工工资即可的其他部门的员工信息
select * from emp where sal > any(select sal from emp where deptno=10 ) and deptno<>10
11.3关联子查询
在单行子查询和多行子查询里,内外查询是分开执行的,有些内查询的执行是要借助于外查询,而外查询的执行又离不开内查询,也就是说内外查询是相关联的,这样的子查询称为关联子查询
例子:
使用关联子查询检索工资大于同职位的平均工资员信息
select empno,ename,sal from emp f where sal>(select avg(sal) from emp where job=f.job) order by job
上述例子子查询里需要用到外查询表中的职位名称,外查询又要用到子查询出来的职位信息
12.补充
12.1自然查询
自然查询是检索多个表的时候,会把两个表中具有相同的列的表进行自动连接(自然连接强制要求有相同的列名称)
关键字:natural join
比如:
select empno,ename,job,dname from emp natural join dept where sal>2000
我们的employee表里和dept都有列empno,那么这个时候,自然查询的时候系统就会自动连接
12.2交叉连接
交叉连接是不需要任何连接条件的连接(两个表不需要有任何的关系),执行结果是笛卡尔乘积
关键字:cross join
select 列1,列2 from 表1 cross join 表2
加载全部内容