pytorch tensorboard使用
wf6892 人气:0我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorboard这一套完美的可视化工具,未免可以将其应用到Pytorch中,用于Pytorch的可视化。这里特别感谢Github上的解决方案: https://github.com/lanpa/tensorboardX。
一、tensorboard程序实例:
1.代码
from torch.utils.tensorboard import SummaryWriter # 用于将数据写入tensorboard
import csv # 用于从本地csv中读取数据
'''从csv读取数据,用于后续显示在tensorboard中'''
fileAddr = 'models/211016_101208/reward.csv' # 待读取的文件地址
file = open(fileAddr, 'r') # 打开文件
data = csv.reader(file) # 从文件中读取数据,但此时data是{reader}格式
next(data) # 忽略数据的第一行,这是csv的表头。
'''csv数据读取完毕'''
'''将data数据写入tensorboard'''
tensorboard_logs_addr = "logs_tensorboard/211021" # 设定tensorboard文件存放的地址
writer = SummaryWriter(tensorboard_logs_addr)
for index, data1 in enumerate(data): # 开始写入文件。
# 一个图中写入多组数据,共用y轴
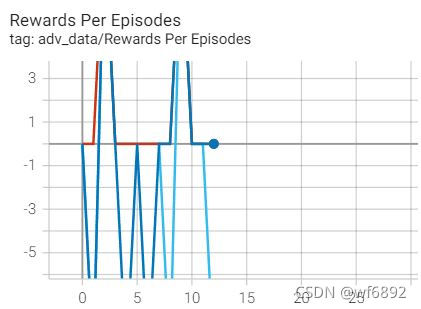
writer.add_scalars('adv_data/Rewards Per Episodes',
{'agent0':float(data1[0]),
'agent1':float(data1[1]),
'agent2':float(data1[2]),}, index)
# 一个图中写入一组数据
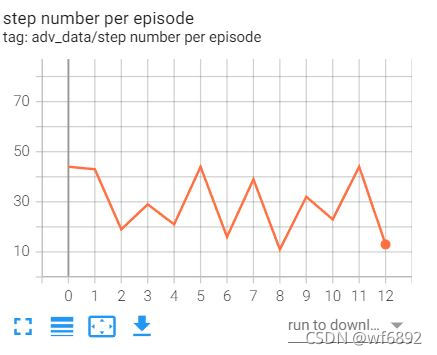
writer.add_scalar('adv_data/step number per episode', int(data1[4]), index)
# 一个图中写入一组数据
writer.add_scalar('gda_data/Rewards per episode', float(data1[3]), index)
writer.add_scalar('gda_data/step number per episode', int(data1[4]), index)
writer.close() # 完成后关闭
运行以上代码,便会在文件夹logs_tensorboard/211021中生成tensorboard数据。
2.在命令提示符中操作
# 打开命令提示符后默认在c盘,固先转换到d盘
C:\Users\wf>d:
# 进入程序所在文件夹
D:\>cd D:\04MADDPG\40_MADDPG_torch-master -UAV_FixedSpeed
# 打开tensorboard的代码
D:\04MADDPG\40_MADDPG_torch-master -UAV_FixedSpeed>tensorboard --logdir=logs_tensorboard/211021
完
说明:
tensorboard --logdir=logs_tensorboard/211021
tensorboard --logdir= 是不可更改的;
logs_tensorboard/211021 是tensorboard文件存放的地址;logs_tensorboard文件夹的上一层就是程序所在文件夹;
3.在浏览器中打开网址
http://localhost:6006/
4.效果
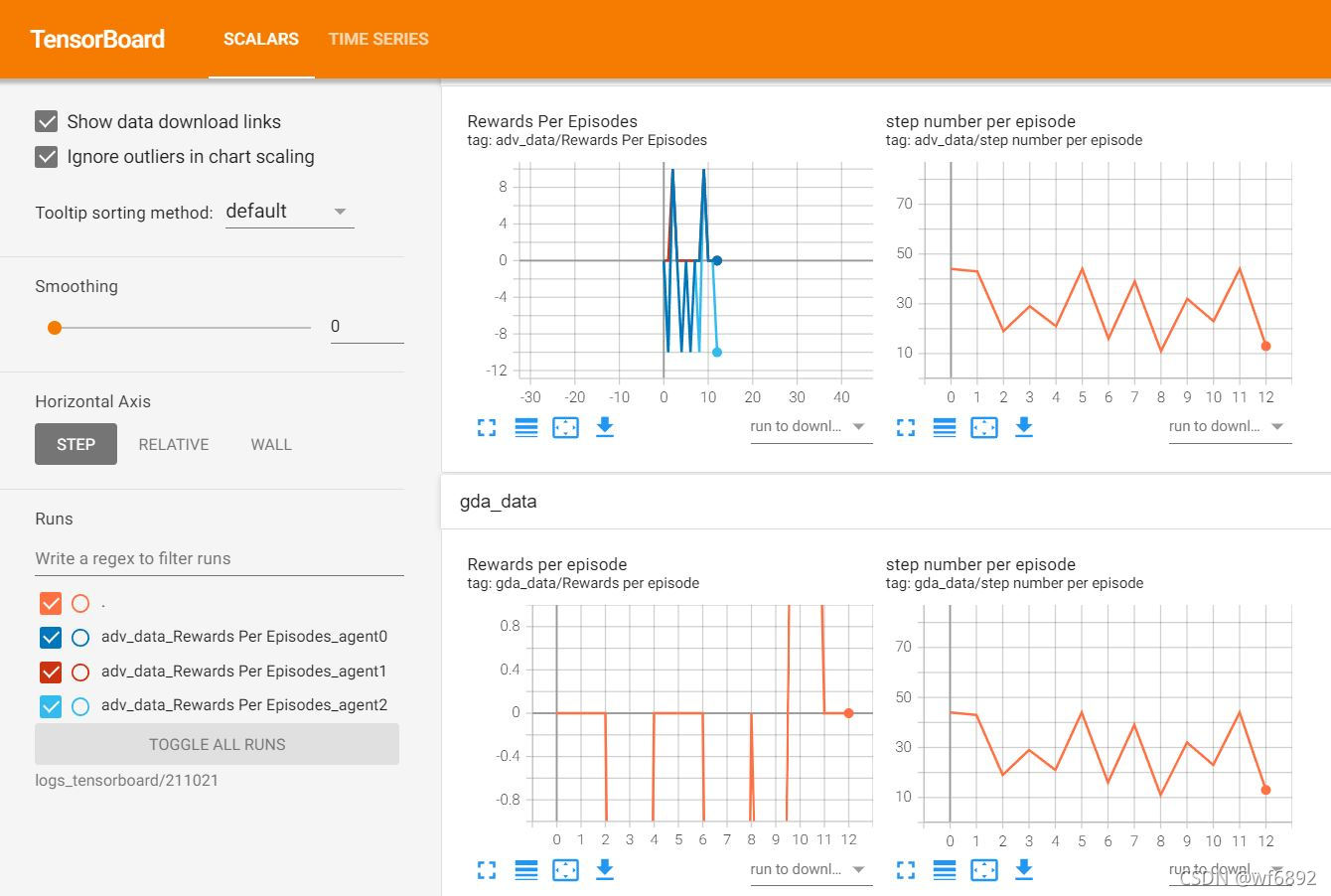
二、writer.add_scalar()与writer.add_scalars()参数说明
writer.add_scalar() 一副图中只有一组数据
writer.add_scalars() 一副图中有多组数据,但共用x轴
1.概述
将数据写入tensorboard只有以下代码:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("tensorboard文件存放地址")
# 将数据写入tensorboard文件,规定写入的形式
writer.add_scalar() 或 writer.add_scalars()
writer.close()
2.参数说明
writer.add_scalar('TAG', Y-DATA, X-DATA)
writer.add_scalars('TAG', {'Line1':Line1-Y-DATA,
'Line2':Line2-Y-DATA,
'Line3':Line3-Y-DATA,
... ... ,}, X-DATA)
其中:
- 运行一次writer.add_scalar()或writer.add_scalar()生成一张图像;
- 如果后面运行的writer.add_scalar()的标签和前面的相同,会覆盖掉旧的图像;
参数说明:
TAG 是当前绘制图像的分类标签,可以设置2级标签;如A1/B1,A1/C1,A2/B2;
当两张图像的第一级标签相同时,两张图象会放在一行;
当两张图像的第一级标签不同时,两张图象会放在不同的组,即两张图像上下放;
Y-DATA 是图像中Y轴的数据
Line1-Y-DATA 是图像中Line1的Y轴数据
Line2-Y-DATA 是图像中Line2的Y轴数据
Line3-Y-DATA 是图像中Line3的Y轴数据
X-DATA 是图像中X轴的数据
Line1、Line2、Line3是同一张图像中,几个曲线的名称,他们共用X轴
3.writer.add_scalar()效果
4.writer.add_scalars()效果
加载全部内容