python爬取淘宝商品信息
不正经的kimol君 人气:0Tip:本文仅供学习与交流,切勿用于非法用途!!!
背景介绍
有个同学问我:“XXX,有没有办法搜集一下淘宝的商品信息啊,我想要做个统计”。于是乎,闲来无事的我,又开始琢磨起这事…

一、模拟登陆
兴致勃勃的我,冲进淘宝就准备一顿乱搜:

在搜索栏里填好关键词:“显卡”,小手轻快敲击着回车键(小样~看我的)
心情愉悦的我等待着返回满满的商品信息,结果苦苦的等待换了的却是302,于是我意外地来到了登陆界面。
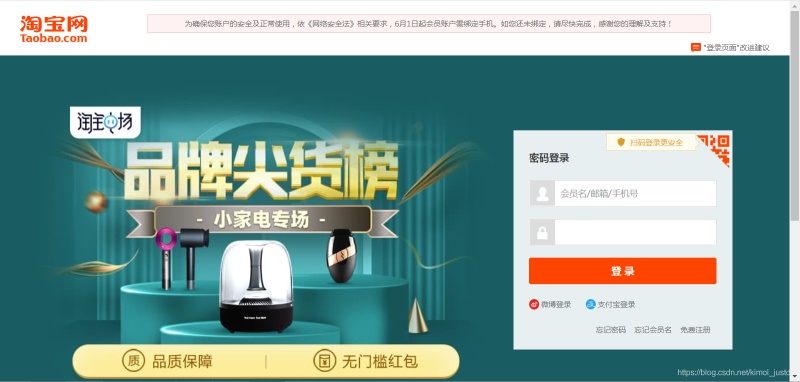
情况基本就是这么个情况了…
然后我查了一下,随着淘宝反爬手段的不断加强,很多小伙伴应该已经发现,淘宝搜索功能是需要用户登陆的!
关于淘宝模拟登陆,有大大已经利用requests成功模拟登陆(感兴趣的小伙伴请往这边>>>requests登陆淘宝<<<)
这个方法得先分析淘宝登陆的各种请求,并模拟生成相应的参数,相对来说有一定的难度。于是我决定换一种思路,通过selenium+二维码的方式:
# 打开图片
def Openimg(img_location):
img=Image.open(img_location)
img.show()
# 登陆获取cookies
def Login():
driver = webdriver.PhantomJS()
driver.get('https://login.taobao.com/member/login.jhtml')
try:
driver.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
except:
pass
time.sleep(3)
# 执行JS获得canvas的二维码
JS = 'return document.getElementsByTagName("canvas")[0].toDataURL("image/png");'
im_info = driver.execute_script(JS) # 执行JS获取图片信息
im_base64 = im_info.split(',')[1] #拿到base64编码的图片信息
im_bytes = base64.b64decode(im_base64) #转为bytes类型
time.sleep(2)
with open('./login.png','wb') as f:
f.write(im_bytes)
f.close()
t = threading.Thread(target=Openimg,args=('./login.png',))
t.start()
print("Logining...Please sweep the code!\n")
while(True):
c = driver.get_cookies()
if len(c) > 20: #登陆成功获取到cookies
cookies = {}
for i in range(len(c)):
cookies[c[i]['name']] = c[i]['value']
driver.close()
print("Login in successfully!\n")
return cookies
time.sleep(1)
通过webdriver打开淘宝登陆界面,把二维码下载到本地并打开等待用户扫码(相应的元素大家通过浏览器的F12元素分析很容易就能找出)。待扫码成功后,将webdriver里的cookies转为DICT形式,并返回。(这里是为了后续requests爬取信息的时候使用)
二、爬取商品信息
当我拿到cookies之后,便能对商品信息进行爬取了。
(小样 ~我来啦)
1. 定义相关参数
定义相应的请求地址,请求头等等:
# 定义参数
headers = {'Host':'s.taobao.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding':'gzip, deflate, br',
'Connection':'keep-alive'}
list_url = 'http://s.taobao.com/search?q=%(key)s&ie=utf8&s=%(page)d'
2. 分析并定义正则
当请求得到HTML页面后,想要得到我们想要的数据就必须得对其进行提取,这里我选择了正则的方式。通过查看页面源码:
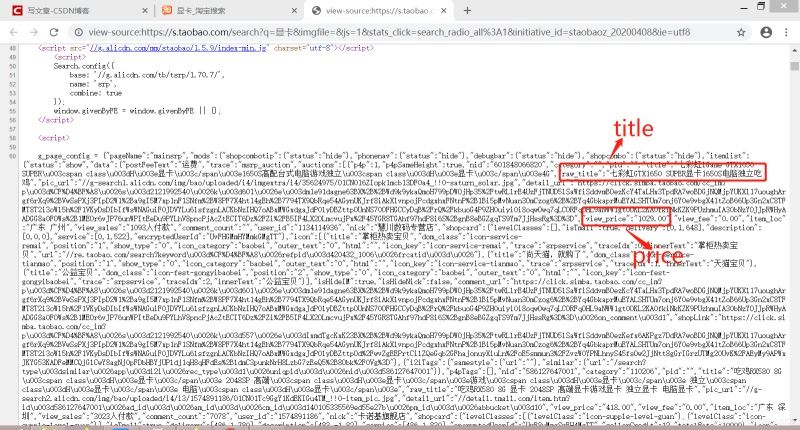
偷懒的我上面只标志了两个数据,不过其他也是类似的,于是得到以下正则:
# 正则模式 p_title = '"raw_title":"(.*?)"' #标题 p_location = '"item_loc":"(.*?)"' #销售地 p_sale = '"view_sales":"(.*?)人付款"' #销售量 p_comment = '"comment_count":"(.*?)"'#评论数 p_price = '"view_price":"(.*?)"' #销售价格 p_nid = '"nid":"(.*?)"' #商品唯一ID p_img = '"pic_url":"(.*?)"' #图片URL
(ps.聪明的小伙伴应该已经发现了,其实商品信息是被保存在了g_page_config变量里面,所以我们也可以先提取这个变量(一个字典),然后再读取数据,也可!)
3. 数据爬取
完事具备,只欠东风。于是,东风来了:
# 数据爬取
key = input('请输入关键字:') # 商品的关键词
N = 20 # 爬取的页数
data = []
cookies = Login()
for i in range(N):
try:
page = i*44
url = list_url%{'key':key,'page':page}
res = requests.get(url,headers=headers,cookies=cookies)
html = res.text
title = re.findall(p_title,html)
location = re.findall(p_location,html)
sale = re.findall(p_sale,html)
comment = re.findall(p_comment,html)
price = re.findall(p_price,html)
nid = re.findall(p_nid,html)
img = re.findall(p_img,html)
for j in range(len(title)):
data.append([title[j],location[j],sale[j],comment[j],price[j],nid[j],img[j]])
print('-------Page%s complete!--------\n\n'%(i+1))
time.sleep(3)
except:
pass
data = pd.DataFrame(data,columns=['title','location','sale','comment','price','nid','img'])
data.to_csv('%s.csv'%key,encoding='utf-8',index=False)
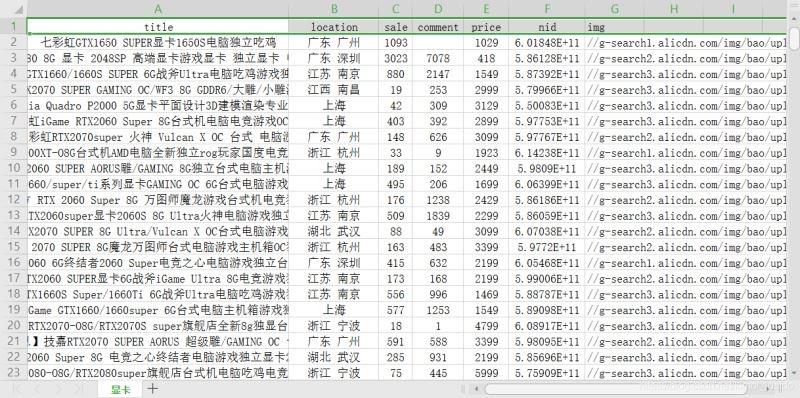
上面代码爬取20也商品信息,并将其保存在本地的csv文件中,效果是这样的:
三、简单数据分析
有了数据,放着岂不是浪费,我可是社会主义好青年,怎能做这种事? 那么,就让我们来简单看看这些数据叭:
(当然,数据量小,仅供娱乐参考)
1.导入库
# 导入相关库 import jieba import operator import pandas as pd from wordcloud import WordCloud from matplotlib import pyplot as plt
相应库的安装方法(其实基本都能通过pip解决):
- jieba
- pandas
- wordcloud
- matplotlib
2.中文显示
# matplotlib中文显示 plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.sans-serif'] = ['SimHei']
不设置可能出现中文乱码等闹心的情况哦~
3.读取数据
# 读取数据
key = '显卡'
data = pd.read_csv('%s.csv'%key,encoding='utf-8',engine='python')
4.分析价格分布
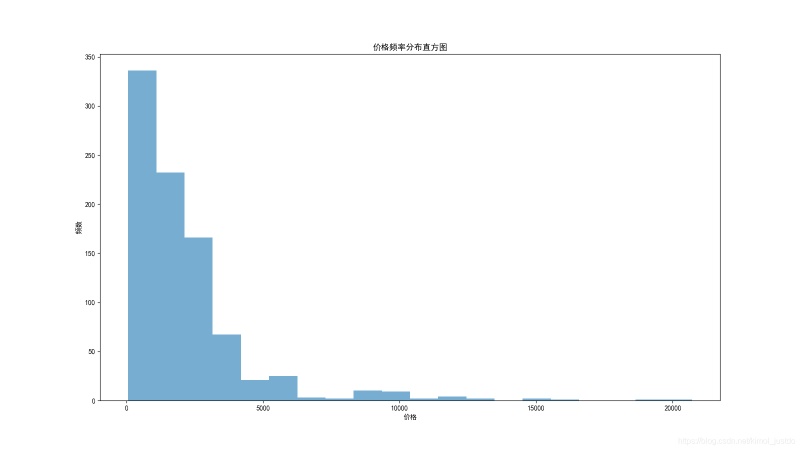
# 价格分布
plt.figure(figsize=(16,9))
plt.hist(data['price'],bins=20,alpha=0.6)
plt.title('价格频率分布直方图')
plt.xlabel('价格')
plt.ylabel('频数')
plt.savefig('价格分布.png')
价格频率分布直方图:
5.分析销售地分布
# 销售地分布
group_data = list(data.groupby('location'))
loc_num = {}
for i in range(len(group_data)):
loc_num[group_data[i][0]] = len(group_data[i][1])
plt.figure(figsize=(19,9))
plt.title('销售地')
plt.scatter(list(loc_num.keys())[:20],list(loc_num.values())[:20],color='r')
plt.plot(list(loc_num.keys())[:20],list(loc_num.values())[:20])
plt.savefig('销售地.png')
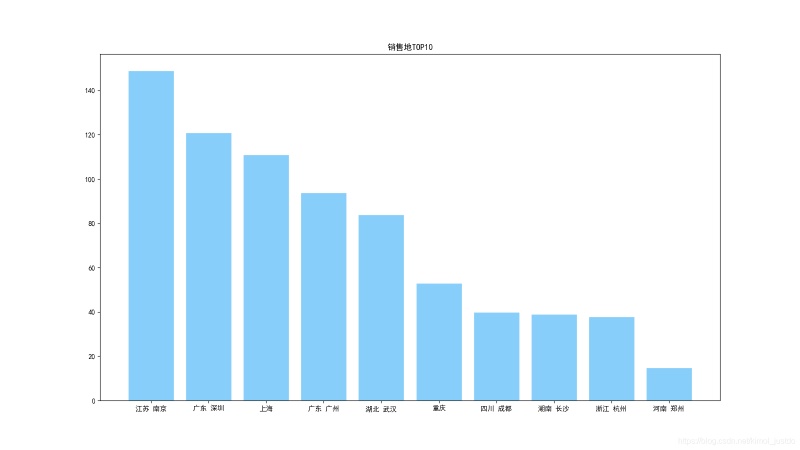
sorted_loc_num = sorted(loc_num.items(), key=operator.itemgetter(1),reverse=True)#排序
loc_num_10 = sorted_loc_num[:10] #取前10
loc_10 = []
num_10 = []
for i in range(10):
loc_10.append(loc_num_10[i][0])
num_10.append(loc_num_10[i][1])
plt.figure(figsize=(16,9))
plt.title('销售地TOP10')
plt.bar(loc_10,num_10,facecolor = 'lightskyblue',edgecolor = 'white')
plt.savefig('销售地TOP10.png')
销售地分布:
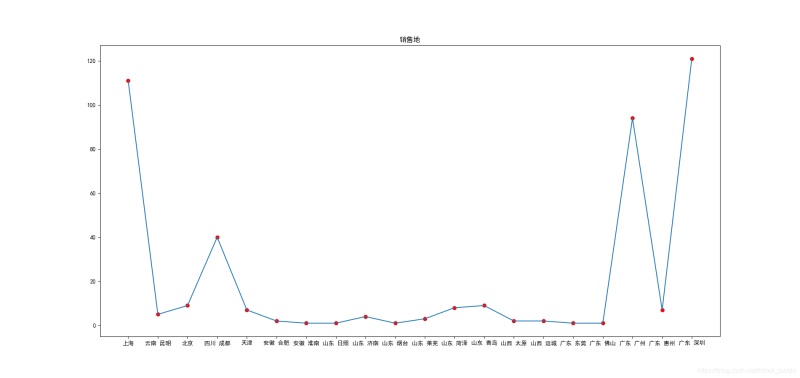
销售地TOP10:
6.词云分析
# 制作词云
content = ''
for i in range(len(data)):
content += data['title'][i]
wl = jieba.cut(content,cut_all=True)
wl_space_split = ' '.join(wl)
wc = WordCloud('simhei.ttf',
background_color='white', # 背景颜色
width=1000,
height=600,).generate(wl_space_split)
wc.to_file('%s.png'%key)
淘宝商品”显卡“的词云:

写在最后
感谢各位大大的耐心阅读~
加载全部内容