Hadoop hive环境配置 Hadoop环境配置之hive环境配置详解
山间皮卡丘 人气:0想了解Hadoop环境配置之hive环境配置详解的相关内容吗,山间皮卡丘在本文为您仔细讲解Hadoop hive环境配置的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Hadoop hive环境配置,Hadoop 环境配置,下面大家一起来学习吧。
1、将下载的hive压缩包拉到/opt/software/文件夹下
安装包版本:apache-hive-3.1.2-bin.tar.gz

2、将安装包解压到/opt/module/文件夹中,命令:
cd /opt/software/ tar -zxvf 压缩包名 -C /opt/module/
3、修改系统环境变量,命令:
vi /etc/profile
在编辑面板中添加如下代码:
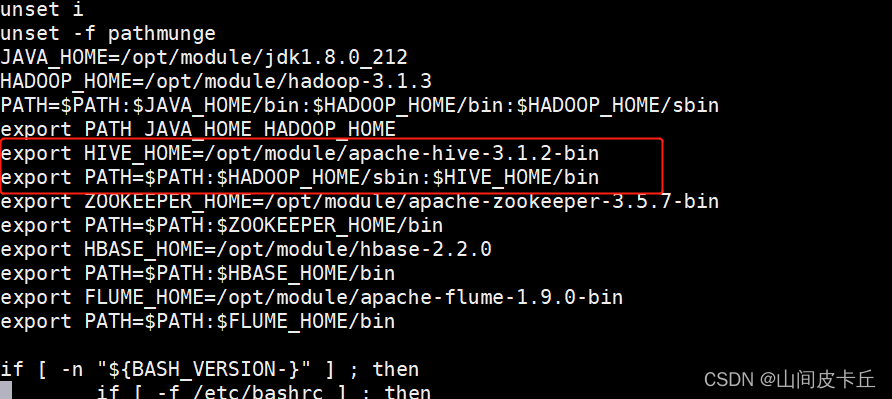
export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin export PATH=$PATH:$HADOOP_HOME/sbin:$HIVE_HOME/bin
4、重启环境配置,命令:
source /etc/profile
5、修改hive环境变量
cd /opt/module/apache-hive-3.1.2-bin/bin/
①配置hive-config.sh文件
vi hive-config.sh
在编辑面板中添加如下代码:
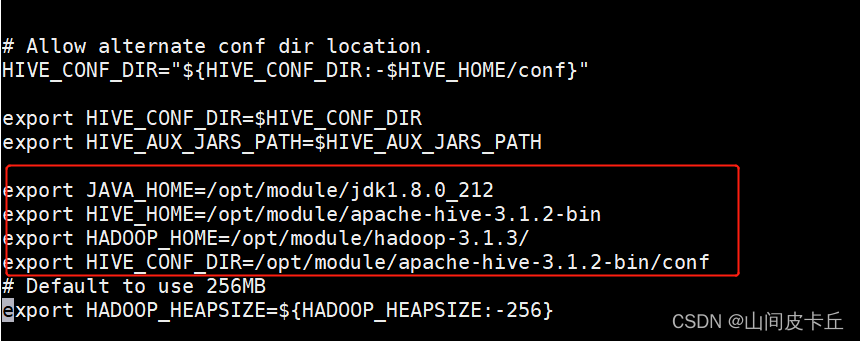
export JAVA_HOME=/opt/module/jdk1.8.0_212 export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin export HADOOP_HOME=/opt/module/hadoop-3.2.0 export HIVE_CONF_DIR=/opt/module/apache-hive-3.1.2-bin/conf
6、拷贝hive配置文件,命令:
cd /opt/module/apache-hive-3.1.2-bin/conf/ cp hive-default.xml.template hive-site.xml
7、修改hive配置文件,找到对应位置按一下代码进行修改:
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
# 自定义密码
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.100:3306/hive?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/module/apache-hive-3.1.2-bin/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/opt/module/apache-hive-3.1.2-bin/iotmp</value>
<description/>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/module/apache-hive-3.1.2-bin/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/module/apache-hive-3.1.2-bin/tmp/${system:user.name}</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/module/apache-hive-3.1.2-bin/tmp/${system:user.name}/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
<description>
Expects one of [derby, oracle, mysql, mssql, postgres].
Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.
</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
</configuration>
8、上传mysql驱动包到/opt/module/apache-hive-3.1.2-bin/lib/文件夹下
驱动包:mysql-connector-java-8.0.15.zip,解压后从里面获取jar包
9、进入数据库,在数据库中新建名为hive的数据库,确保 mysql数据库中有名称为hive的数据库
mysql> create database hive;
10、初始化元数据库,命令:
schematool -dbType mysql -initSchema
11、群起,命令:
start-all.sh Hadoop100上 start-yarn.sh Hadoop101上
12、启动hive,命令:
hive
13、检测是否启动成功,命令:
show databases;
出现各类数据库,则启动成功
加载全部内容