Python人工智能模型训练经验 Python人工智能深度学习模型训练经验总结
Swayzzu 人气:0一、假如训练集表现不好
1.尝试新的激活函数
ReLU:Rectified Linear Unit
图像如下图所示:当z<0时,a = 0, 当z>0时,a = z,也就是说这个激活函数是对输入进行线性转换。使用这个激活函数,由于有0的存在,计算之后会删除掉一些神经元,使得神经网络变窄。

该函数也有其他变体,如下图所示,主要是对于z小于0的时候,对应

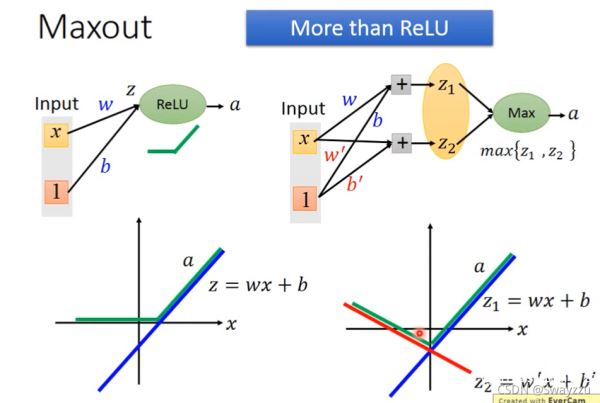
Maxout:以上几种函数的一般形式
简单来说就是谁大输出谁,通过Maxout可以自己学习激活函数。当给出的参数不同的时候,可以得到上面所描述的各类函数。如下图所示,当输入给1个计算单元时,得到蓝色的线,假如第二个计算单元参数均为0,则是X轴上的一条线,那么在这两个之中取大的那个,就是ReLU;当第二个计算单元参数不为0的时候,就可以得到其他形式的结果。
2.自适应学习率
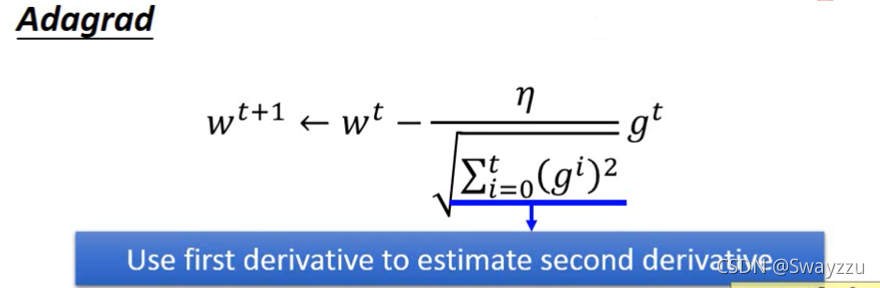
①Adagrad
Adagrad是使用前面的梯度进行平方和再开方,作为计算梯度时系数的一部分。
②RMSProp
是Adagrad的进阶版,在Adagrad中,是使用了前面所有的梯度平方和再开方,这个系数中没有考虑当前的梯度。在RMSProp中,是考虑了现在的梯度,也对其进行平方,并对两项进行一个权重的分配。
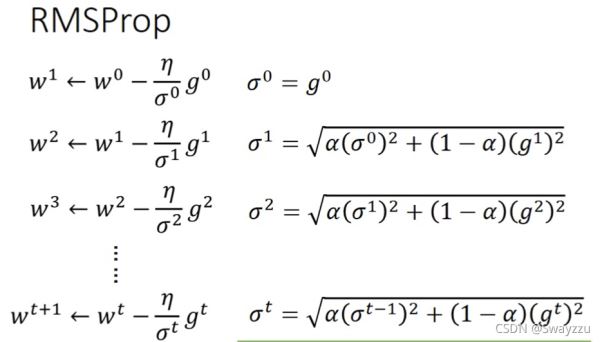
③ Momentum
加入动量的梯度下降
下图中,v就是上一次的方向。在计算本次方向的时候,加入lambda倍的上一次的方向。其实v就是过去算出来的所有的梯度的总和。

④Adam
将RMSProp和Momentum结合

二、在测试集上效果不好
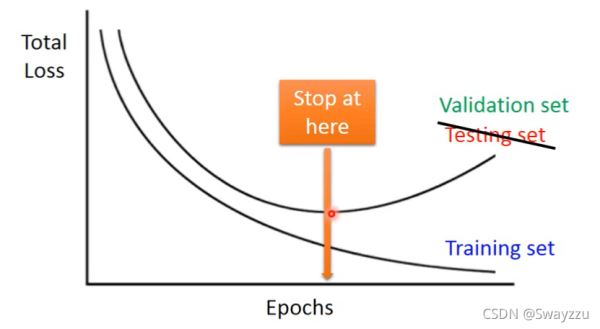
1.提前停止
通过交叉验证集,提前停止训练
2.正则化
和其他的算法正则化方式一致,有L1和L2正则,此处不再详细描述。
3.Dropout
每次训练的时候,都以p%的几率去掉一些神经元以及输入值。得到如下图所示的更瘦一些的神经网络。直接去训练这个神经网络。下一次训练的时候,对整个网络重新进行采样。(类似于随机森林)
在测试的时候不进行dropout,如果训练的时候的dropout几率是p%,那么在测试集上,所有的权重都乘上(1-p)%

加载全部内容