Pandas两个表格内容模糊匹配 Python Pandas两个表格内容模糊匹配的实现
迪迦瓦特曼 人气:5想了解Python Pandas两个表格内容模糊匹配的实现的相关内容吗,迪迦瓦特曼在本文为您仔细讲解Pandas两个表格内容模糊匹配的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:pandas两列模糊匹配,pandas表格内容模糊匹配,pandas模糊匹配两列,下面大家一起来学习吧。
一、方法2
此方法是两个表构建某一相同字段,然后全连接,在做匹配结果筛选,此方法针对数据量不大的时候,逻辑比较简单,但是内存消耗较大
1. 导入库
import pandas as pd import numpy as np import re
2. 构建关键词
#关键词数据
df_keyword = pd.DataFrame({
"keyid" : np.arange(5),
"keyword" : ["numpy", "pandas", "matplotlib", "sklearn", "tensorflow"]
})
df_keyword

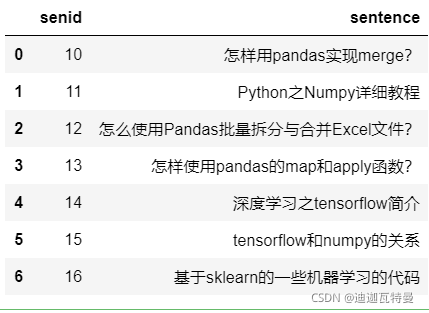
3. 构建句子
df_sentence = pd.DataFrame({
"senid" : np.arange(10,17),
"sentence" : [
"怎样用pandas实现merge?",
"Python之Numpy详细教程",
"怎么使用Pandas批量拆分与合并Excel文件?",
"怎样使用pandas的map和apply函数?",
"深度学习之tensorflow简介",
"tensorflow和numpy的关系",
"基于sklearn的一些机器学习的代码"
]
})
df_sentence
4. 建立统一索引
df_keyword['match'] = 1 df_sentence['match'] = 1
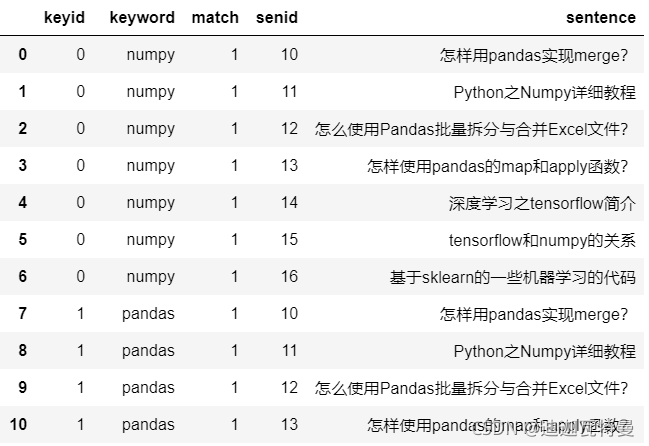
5. 表连接
df_merge = pd.merge(df_keyword, df_sentence) df_merge
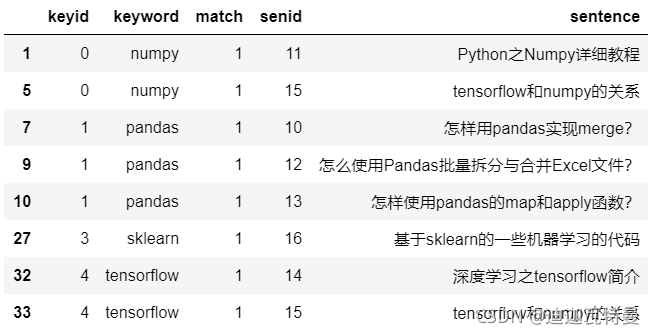
6. 关键词匹配
def match_func(row):
return re.search(row["keyword"], row["sentence"], re.IGNORECASE) is not None
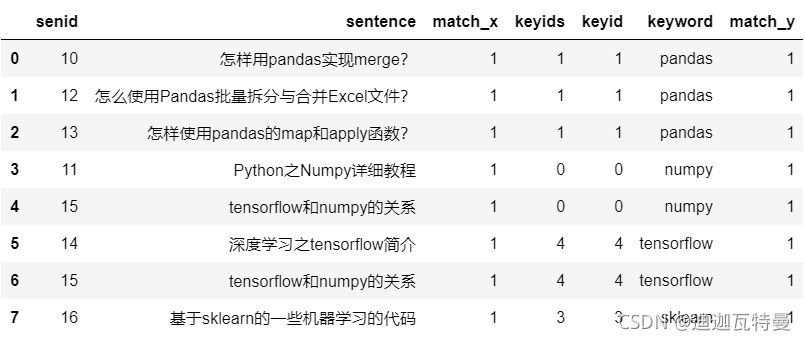
df_merge[df_merge.apply(match_func, axis = 1)]
匹配结果如下
二、方法2
此方法对编程能力有要求,在大数据集上计算量较方法一小很多
1. 构建字典
key_word_dict = {
row.keyword : row.keyid
for row in df_keyword.itertuples()
}
key_word_dict
{'numpy': 0, 'pandas': 1, 'matplotlib': 2, 'sklearn': 3, 'tensorflow': 4}
2. 关键词匹配
def merge_func(row):
#新增一列,表示可以匹配的keyid
row["keyids"] = [
keyid
for key_word, keyid in key_word_dict.items()
if re.search(key_word, row["sentence"], re.IGNORECASE)
]
return row
df_merge = df_sentence.apply(merge_func, axis = 1)
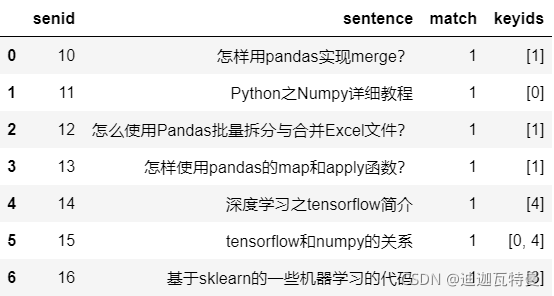
3. 结果展示
df_merge
4. 匹配结果展开
df_result = pd.merge(
left = df_merge.explode("keyids"),
right = df_keyword,
left_on = "keyids",
right_on = "keyid")
df_result
总结
加载全部内容