Java8 使用并行流 Java8 怎样正确高效的使用并行流
小小工匠 人气:0正确使用并行流,避免共享可变状态
错用并行流而产生错误的首要原因,就是使用的算法改变了某些共享状态。下面是另一种实现对前n个自然数求和的方法,但这会改变一个共享累加器:
public static long sideEffectSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).forEach(accumulator::add);
return accumulator.total;
}
public class Accumulator {
public long total = 0;
public void add(long value) { total += value; }
}
有什么问题呢?
它在本质上就是顺序的。每次访问 total 都会出现数据竞争。如果用同步来修复,那就完全失去并行的意义了。
为了说明这一点,让我们试着把 Stream 变成并行的:
public static long sideEffectParallelSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).parallel().forEach(accumulator::add);
return accumulator.total;
}
测试下,输出

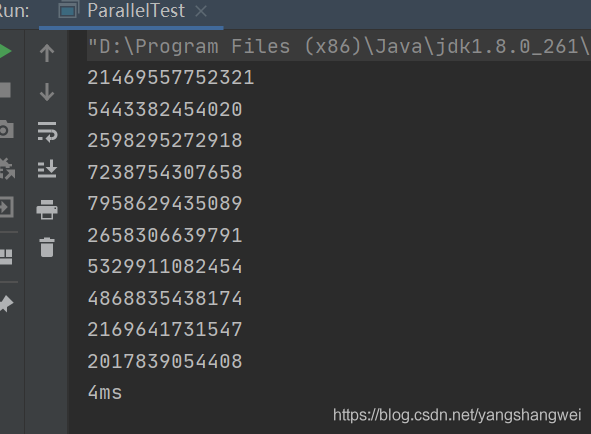
性能无关紧要了,唯一要紧的是每次执行都会返回不同的结果,都离正确值差很远。这是由于多个线程在同时访问累加器,执行 total += value ,而这却不是一个原子操作。问题的根源在于, forEach 中调用的方法有副作用它会改变多个线程共享的对象的可变状态。
要是你想用并行 Stream 又不想引发类似的意外,就必须避免这种情况。
所以共享可变状态会影响并行流以及并行计算,要避免共享可变状态,确保并行 Stream 得到正确的结果。
高效使用并行流
是否有必要使用并行流?
- 如果有疑问,多次测试结果。把顺序流转成并行流轻而易举,但却不一定是好事
- 留意装箱。自动装箱和拆箱操作会大大降低性能
Java 8中有原始类型流( IntStream 、LongStream 、 DoubleStream )来避免这种操作,但?有可能都应该用这些流。
- 有些操作本身在并行流上的性能就比顺序流差。特别是 limit 和 findFirst 等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。
例如, findAny 会比 findFirst 性能好,因为它不一定要按顺序来执行。可以调用 unordered 方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用limit 可能会比单个有序流(比如数据源是一个 List )更高效。
- 还要考虑流的操作流水线的总计算成本。
设N是要处理的元素的总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味着使用并行流时性能好的可能性比较大。
- 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还?不上并行化造成的额外开销
- 要考虑流背后的数据结构是否易于分解。
例如, ArrayList 的拆分效率比 LinkedList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用 range 工厂方法创建的原始类型流也可以快速分解。
- 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。
例如,一个 SIZED 流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
- 还要考虑终端操作中合并步骤的代价是大是小(例如 Collector 中的 combiner 方法)
如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
流的数据源和可分解性

最后, 并行流背后使用的基础架构是Java 7中引入的分支/合并框架了解它的内部原理至关重要。
java 并行计算的几点实践总结
稍微接触了 java 的并行计算,谈谈几点浅显的总结吧
并行计算不一定比串行计算快,一般在大规模问题才会显示出优势
结合 lambda 表达式的 parallelStream 可以方便调用并行计算,但可能会出现空指针错误,解决这一问题可能需要更高级的多线程知识
看网上资料,Collection 类型对并行计算支持的好,一般数组类型支持的一般。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容