带头双向循环链表数据结构 C语言编程数据结构带头双向循环链表全面详解
高邮吴少 人气:0前言
上一篇数据结构专栏,我们介绍了单链表的各个接口函数,大家可能会发现单链表存在一些缺陷:比如它一个节点要存储数据+下一个节点地址,占用的空间要远多于顺序表;并且由于单链表是无法从后往前找的,如果你想进行尾删这样的操作,你必须从第一个节点往后找,你的时间复杂度一定是O(n)。
为了解决上面的一些缺陷,我们今天来介绍带头双向循环链表
一、什么是带头循环双向链表

这种链表会有一个哨兵位head节点指向d1,然后d1指向d2…这和单链表非常相似。
但和单链表最大的区别就是:这种链表的每个节点不仅会存储下一个节点地址而且会存储上一个节点的地址,然后尾节点会存储一个指向哨兵位head的地址,然后哨兵位head会存储一个指向尾结点的地址。
具体代码如下:
typedef int LTDataType;//万一以后需要改链表数据类型,可以直接在这里更改(int)
typedef struct ListNode
{
struct ListNode*next;
struct ListNode*prev;
LTDataType data;
}ListNode;//结构体重命名
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、链表初始化
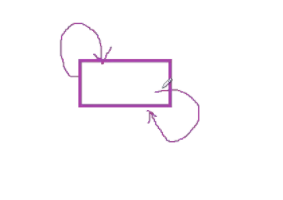
类似于上图的效果,刚开始创建只有一个节点,它储存的前地址和后地址都指向自己
代码如下(示例):
#include<stdlib.h>//malloc函数头文件
ListNode* BuyListNode(LTDataType x)//创建一个节点
{
ListNode*newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
ListNode* ListInit()//链表初始化
{
ListNode*phead = BuyListNode(0);
phead->next = phead;
phead->prev = phead;
return phead;
}
ps:这里ListInit函数用的是返回值的方法,你也可以用二级指针传参来进行初始化操作
三、链表接口函数
1.尾插
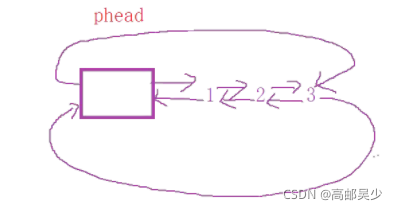
我们以上图为例,原先链表的head节点的前驱指向3,然后3的后驱指向head节点,那在3后面怎么进行尾插呢?由于head节点里存放了3节点的地址,所以我们可以直接找到3节点,找到之后怎么办?把head节点的前驱改成4节点地址,3节点后驱改为4节点地址,最后4节点后驱指向head节点。如下图:

代码如下(示例):
#include<assert.h>//assert函数头文件
void ListPushBack(ListNode*phead, LTDataType x)//尾插
{
assert(phead);//对传过来的指针进行断言,因为你要进行尾插至少得有个头节点啊
//如果传过来的是空指针会进行报错
ListNode*tail = phead->prev;
ListNode*newnode = BuyListNode(x);
tail->next = newnode;
newnode->prev = tail;
newnode->data = phead;
phead->prev = newnode;
}
2.头插
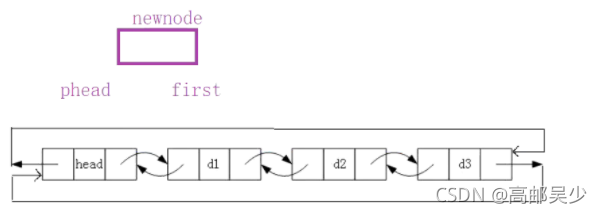
如上图,先要在head和d1之间进行头插,怎么操作?非常简单,思路和尾插一模一样
head的后驱指向newnode,newnode的前驱和后驱分别指向phead和d1,d1前驱指向newnode如下图:
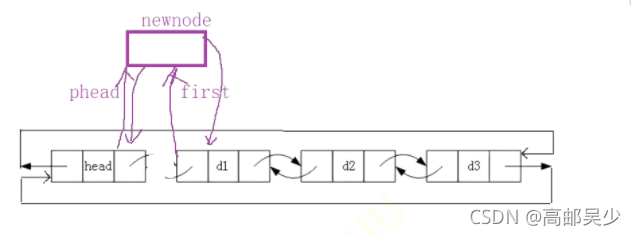
代码如下(示例):
void ListPushFront(ListNode*phead,LTDataType x)
{
assert(phead);
ListNode*first = phead->next;
ListNode*newnode = BuyListNode(x);
phead->next = newnode;
newnode->prev = phead;
newnode->next = first;
first->prev = newnode;
}
注意!!!这里是先定义了一个first来存放d1这个地址,如果不事先定义的话,phead->next = newnode;head不再存储d1地址,你就找不到d1了。当然了,如果你就是不想先定义一个first来存放d1地址也可以。怎么做呢?“先连后断”,newnode后驱先接上d1节点,然后你head节点后驱接上newnode。
3.头删
头删也是和前面两个类似的思想
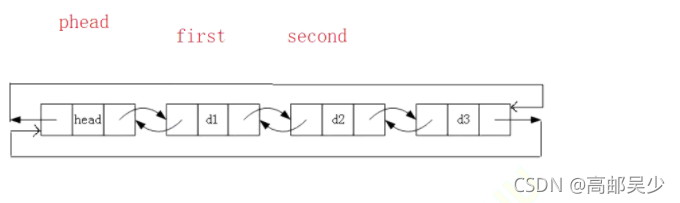
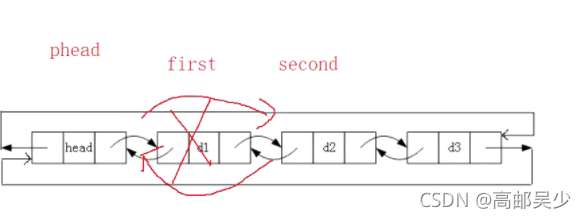
头删也就是把d1节点删掉,我们定义2个指针分别指向d1和d2,然后把head节点后驱接指向d2,d2前驱指向head即可,如下图:
代码如下(示例):
void ListPopFront(ListNode*phead)
{
assert(phead);
ListNode*first = phead->next;
ListNode*second = first->next;
phead->next = second;
second->prev = phead;
}
4.尾删
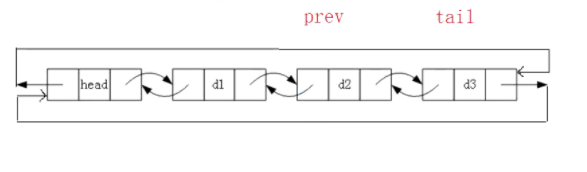
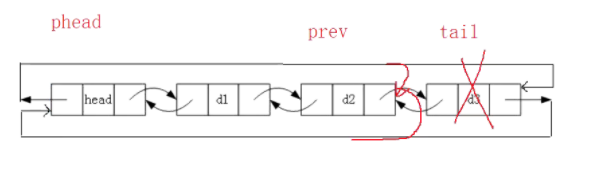
现在要删除d3这个节点,我们定义一个tail和prev指针分别指向d3和d2,然后把d2后驱接上head,head前驱接上d2即可,如下图:
代码如下(示例):
void ListPopBack(ListNode*phead)
{
assert(phead);
assert(phead->next != phead);//要进行尾删至少保证有一个节点可删(非head节点)
ListNode*tail = phead->prev;//头节点前驱指向尾部
ListNode*prev = tail->prev;//通过尾部得到d2地址
prev->next = phead;//d2后驱head节点
phead->prev = prev;//head前驱指向d2节点
}
5.任意位置插入数据
要在某个位置前插入数据,你需要先找到那个位置在哪里,我们先写一个查找函数
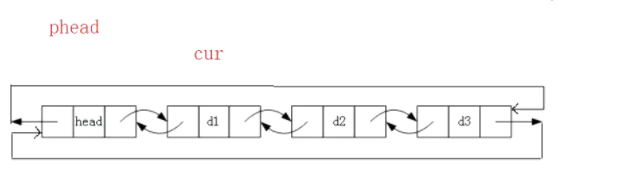
怎么个找法呢?很简单,定义一个cur指针,然后从d1开始遍历看有没有我们想要找的数据,遍历到head节点结束。
代码如下(示例):
ListNode* ListFind(ListNode*phead, LTDataType x)
{
assert(phead);
ListNode*cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;//遍历完链表都没有找到就返回空指针
}
找到所需位置后就是进行,插入操作
void ListInsert(ListNode*pos, LTDataType x)
{
assert(pos);
ListNode*prev = pos->prev;
ListNode*newnode = BuyListNode(x);
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
两个函数一起调用也是很简单的,比如我现在要在链表里数据3的位置前插入300,下面两行代码即可完成两个函数的运用。
ListNode*pos = ListFind(plist, 3); ListInsert(pos, 300);
ps:这里找到所需位置指针,你如果需要,也可以通过该指针对该位置的值进行修改,比如(返回的指针)->data=n
6.任意位置删除数据
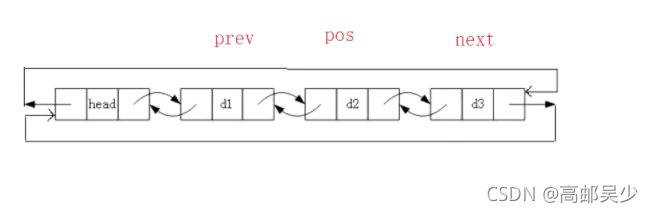
现在要删除pos位置的数据,怎么操作?非常简单!定义一个prev指向pos前一个节点,定义一个next指向pos后一个节点,然后prev和next连起来即可,如图:
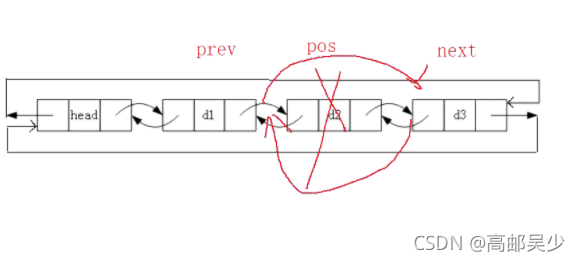
代码如下(示例):
void ListErase(ListNode*pos)//指定位置删除
{
assert(pos);
ListNode*prev = pos->prev;
ListNode*next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);//prev和next连起来了,pos就可以被释放掉了
}
四、打印链表
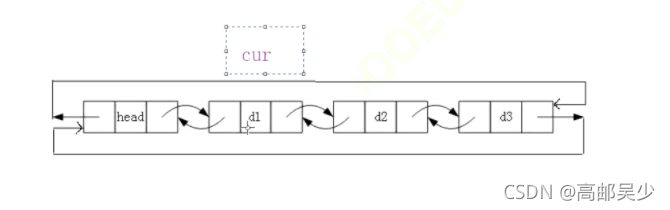
以上图为例:要打印一个链表,head节点是不需要打印的,我们只需要打印存储实际数据的d1,d2,d3即可,定义一个变量cur,让它从d1开始遍历,到head节点结束即可。
代码如下(示例):
void ListPrint(ListNode*phead)
{
ListNode*cur = phead->next;
while (cur != phead)
{
printf("%d\n", cur->data);
cur = cur->next;
}
printf("\n");
}
总结
本文介绍了带头循环双向链表,包括其定义、各个接口函数、及其遍历打印。虽然是链表中最复杂的结构,但它的代码操作却是最简单的,希望通过今天的学习读者能有所收获~更多关于带头双向循环链表数据结构的资料请关注其它相关文章!
加载全部内容