Python 爬虫技巧 Python爬虫必备技巧详细总结
小旺不正经 人气:0想了解Python爬虫必备技巧详细总结的相关内容吗,小旺不正经在本文为您仔细讲解Python 爬虫技巧的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python,爬虫技巧,Python,爬虫,下面大家一起来学习吧。
自定义函数
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&word=' + company
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.news-title_1YtI1 a')
for i in title:
print(i.text)
# 批量调用函数
companies = ['腾讯', '阿里巴巴', '百度集团']
for i in companies:
baidu(i)
批量输出多个搜索结果的标题

结果保存为文本文件
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&word=' + company
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.news-title_1YtI1 a')
fl=open('test.text','a', encoding='utf-8')
for i in title:
fl.write(i.text + '\n')
# 批量调用函数
companies = ['腾讯', '阿里巴巴', '百度集团']
for i in companies:
baidu(i)
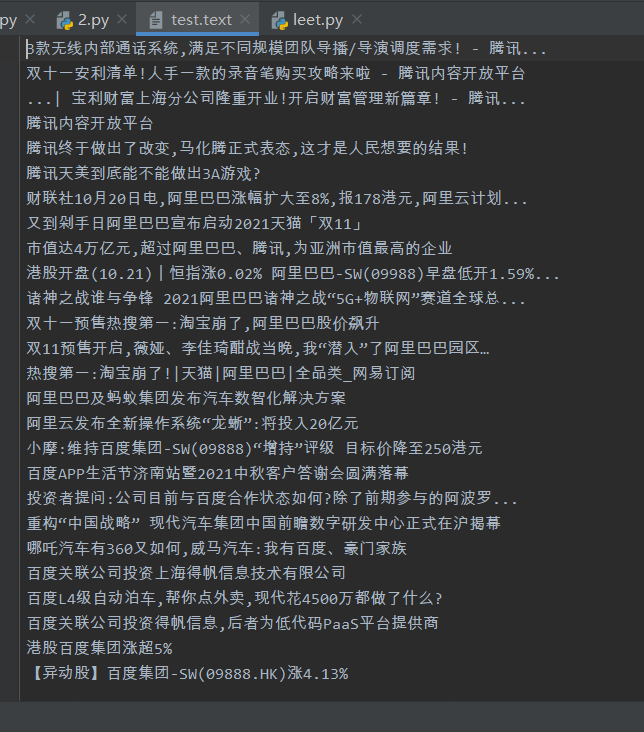
写入代码
fl=open('test.text','a', encoding='utf-8')
for i in title:
fl.write(i.text + '\n')
异常处理
for i in companies:
try:
baidu(i)
print('运行成功')
except:
print('运行失败')
写在循环中 不会让程序停止运行 而会输出运行失败
休眠时间
import time
for i in companies:
try:
baidu(i)
print('运行成功')
except:
print('运行失败')
time.sleep(5)
time.sleep(5)
括号里的单位是秒
放在什么位置 则在什么位置休眠(暂停)
爬取多页内容
百度搜索腾讯
切换到第二页
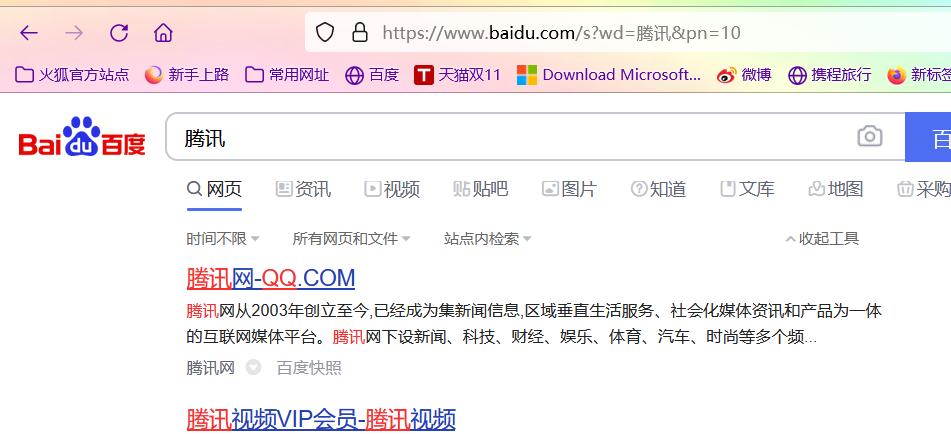
去掉多多余的
https://www.baidu.com/s?wd=腾讯&pn=10
分析出
https://www.baidu.com/s?wd=腾讯&pn=0 为第一页
https://www.baidu.com/s?wd=腾讯&pn=10 为第二页
https://www.baidu.com/s?wd=腾讯&pn=20 为第三页
https://www.baidu.com/s?wd=腾讯&pn=30 为第四页
..........
代码
from bs4 import BeautifulSoup
import time
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(c):
url = 'https://www.baidu.com/s?wd=腾讯&pn=' + str(c)+'0'
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.t a')
for i in title:
print(i.text)
for i in range(10):
baidu(i)
time.sleep(2)
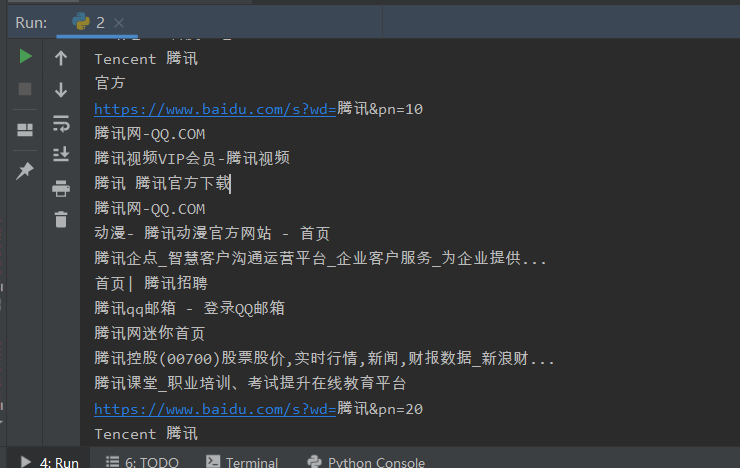
加载全部内容