正则表达式 非贪婪匹配 轻松入门正则表达式之非贪婪匹配篇详解
小旺不正经 人气:0想了解轻松入门正则表达式之非贪婪匹配篇详解的相关内容吗,小旺不正经在本文为您仔细讲解正则表达式 非贪婪匹配的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:正则表达式,非贪婪匹配,下面大家一起来学习吧。
非贪婪匹配 (.*?)
import re
a = '456qwe789rty123abc'
re=re.findall('456(.*?)789',a)
print(re)

通常情况,满足匹配规则“456(.*?)789”的内容通常不止一个,那么findall()函数会从字符串的起始位置开始寻找文本A,找到后开始寻找文本B,当找到第一个文本B后,暂时停止寻找,将文本A和文本B之间的内容存入列表;然后继续寻找文本A,并重复之前的步骤,直到到达字符串的结束位置,并将所有匹配到的内容存入列表。
import re
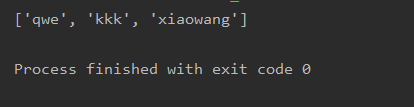
a = '456qwe789rty123456kkk789abc456xiaowang789'
re=re.findall('456(.*?)789',a)
print(re)
贪婪模式的话就会寻找最长的
import re
a = '456qwe789rty123456kkk789abc456xiaowang789'
re=re.findall('456(.*)789',a)
print(re)

非贪婪匹配 .*?
import re
a='<a href="https://blog.csdn.net/weixin_42403632/article/details/120825546" rel="external nofollow" target="_blank" data-report-click="{"spm":"3001.5501"}" data-report-query="spm=3001.5501" data-v-6fe2b6a7="">'
re=re.findall('<a href="(.*?)" rel="external nofollow" rel="external nofollow" .*?',a)
print(re)

" 和 url后面的html代码用.*?代表,需要提取的是<a href="后的内容,用“(.*?)”代表
实战爬取博客专栏url
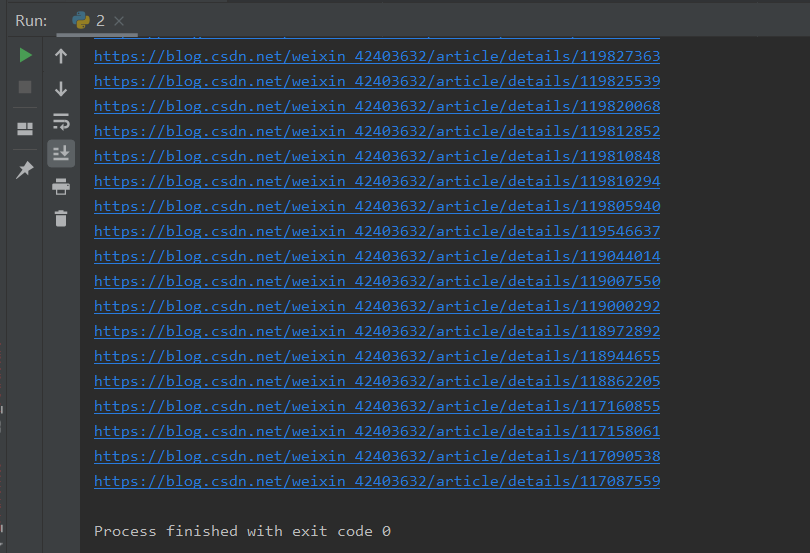
import re,requests
url='https://blog.csdn.net/weixin_42403632/category_11076268.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
re=re.findall('<a href="(.*?)" rel="external nofollow" rel="external nofollow" .*?rel="noopener">',html)
for i in re:
print(i)
加载全部内容