Python Mnist手写数字识别 Python实战小项目之Mnist手写数字识别
GSAU-深蓝工作室 人气:0想了解Python实战小项目之Mnist手写数字识别的相关内容吗,GSAU-深蓝工作室在本文为您仔细讲解Python Mnist手写数字识别的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python,Mnist,手写数字识别,Python,实战,下面大家一起来学习吧。
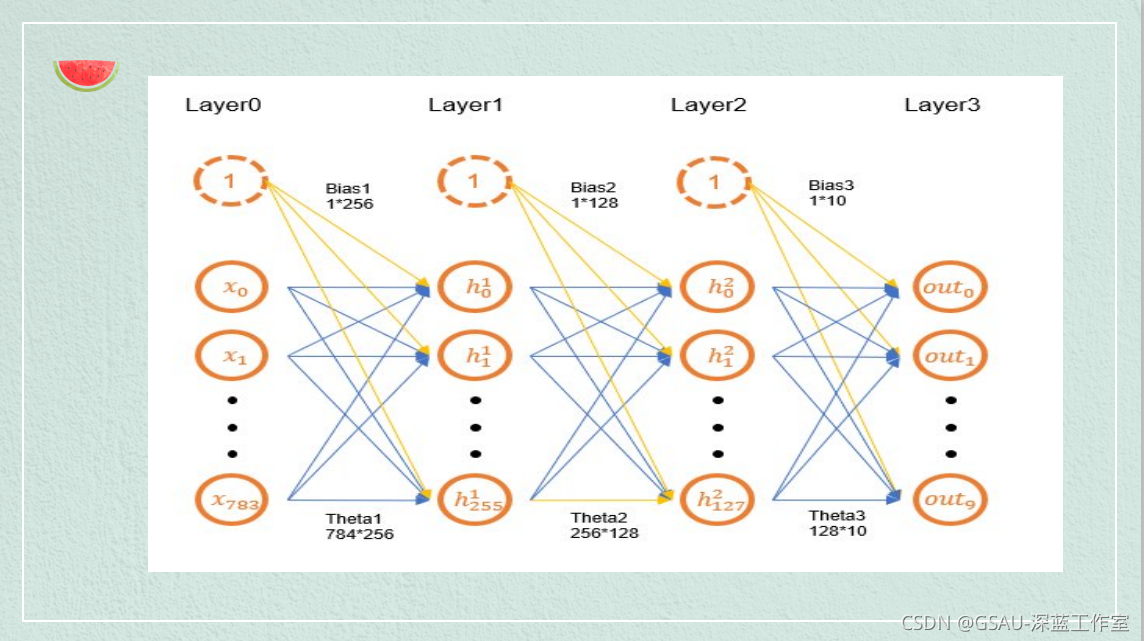
程序流程分析图:

传播过程:

代码展示:
创建环境
使用<pip install+包名>来下载torch,torchvision包
准备数据集
设置一次训练所选取的样本数Batch_Sized的值为512,训练此时Epochs的值为8
BATCH_SIZE = 512
EPOCHS = 8
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
下载数据集
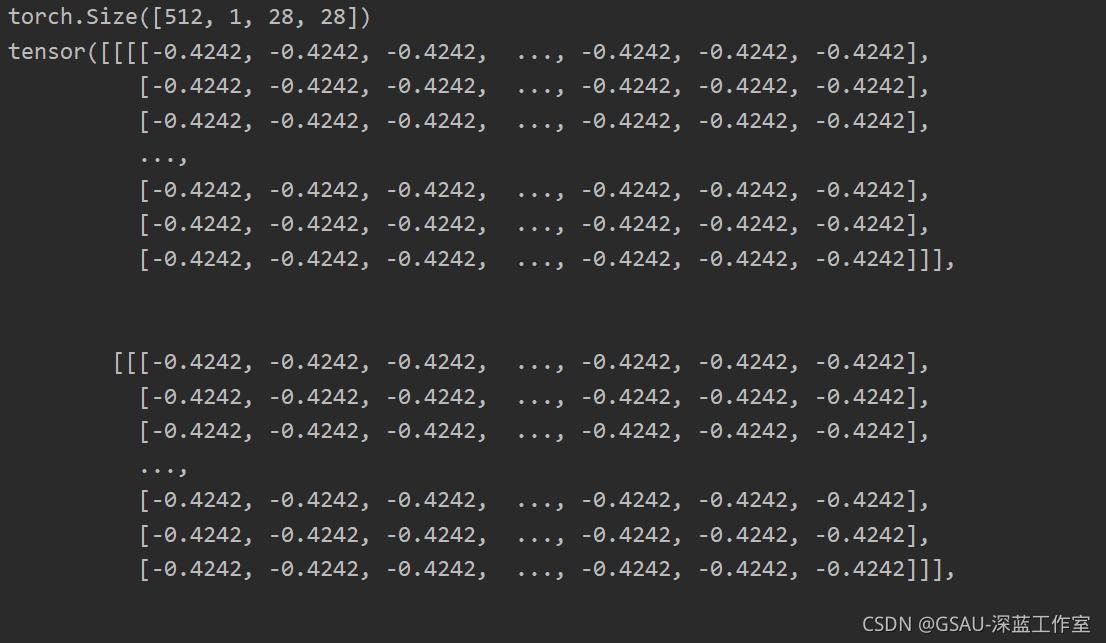
Normalize()数字归一化,转换使用的值0.1307和0.3081是MNIST数据集的全局平均值和标准偏差,这里我们将它们作为给定值。model
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([.
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
下载测试集
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
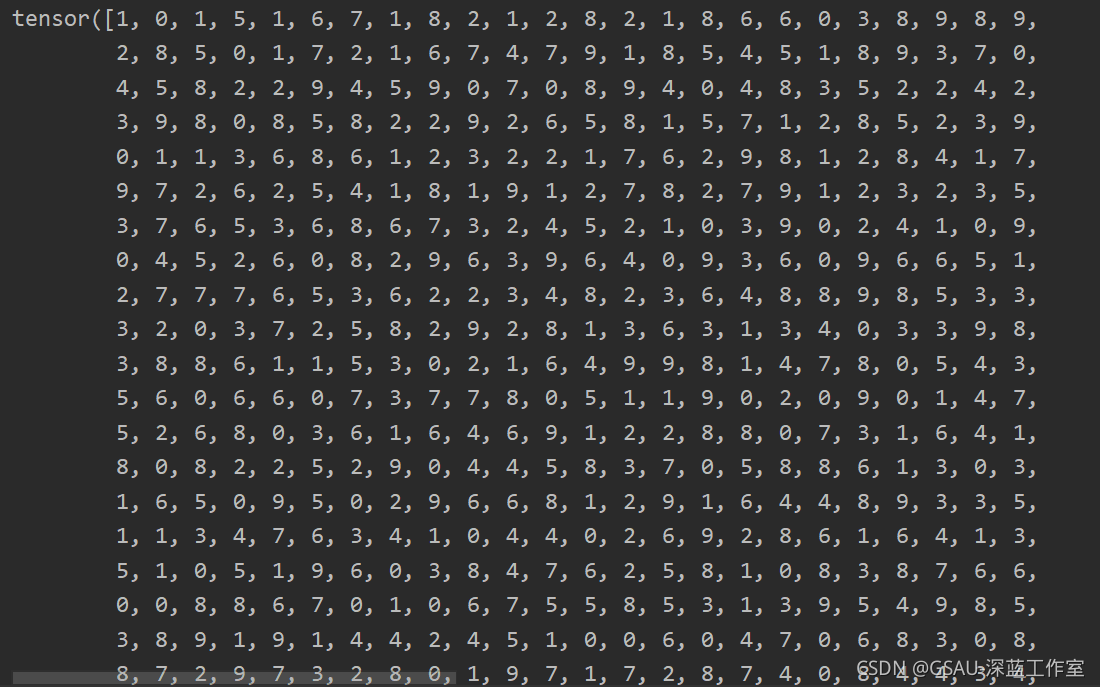
绘制图像
我们可以使用matplotlib来绘制其中的一些图像
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape)
print(example_data)
import matplotlib.pyplot as plt
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()

搭建神经网络
这里我们构建全连接神经网络,我们使用三个全连接(或线性)层进行前向传播。
class linearNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.log_softmax(x, dim=1)
return x
训练模型
首先,我们需要使用optimizer.zero_grad()手动将梯度设置为零,因为PyTorch在默认情况下会累积梯度。然后,我们生成网络的输出(前向传递),并计算输出与真值标签之间的负对数概率损失。现在,我们收集一组新的梯度,并使用optimizer.step()将其传播回每个网络参数。
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
测试模型
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 将一批的损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
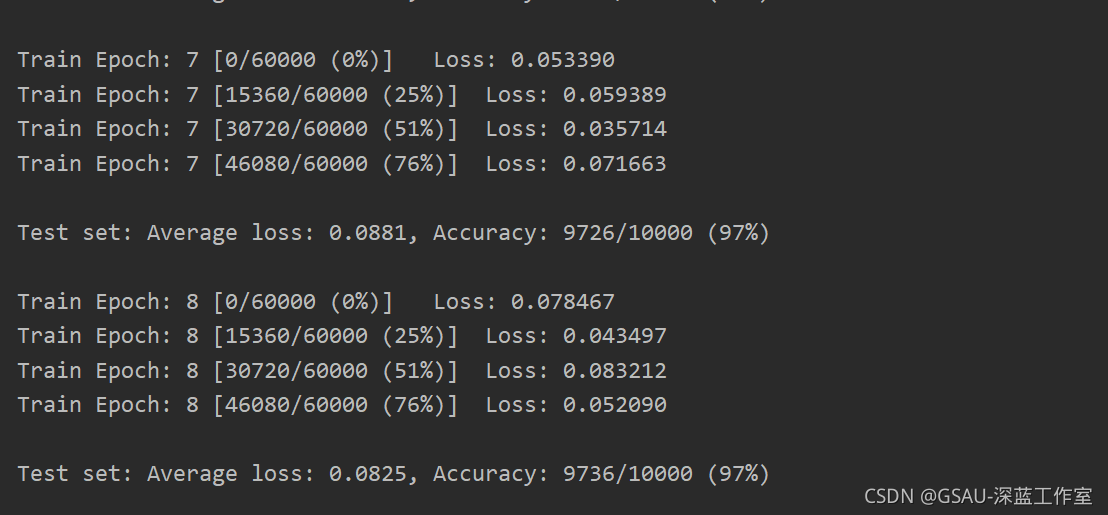
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
将训练次数进行循环
if __name__ == '__main__':
model = linearNet()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
保存训练模型
torch.save(model, 'MNIST.pth')
运行结果展示:
分享人:苏云云
加载全部内容