Python 爬取虎牙视频 Python爬虫实战之虎牙视频爬取附源码
松鼠爱吃饼干 人气:0想了解Python爬虫实战之虎牙视频爬取附源码的相关内容吗,松鼠爱吃饼干在本文为您仔细讲解Python 爬取虎牙视频的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python,爬取视频,Python,实战,Python,爬取虎牙,下面大家一起来学习吧。
知识点
- 爬虫基本流程
- re正则表达式简单使用
- requests
- json数据解析方法
- 视频数据保存
开发环境
- Python 3.8
- Pycharm
爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析]
1.确定需求 (爬取的内容是什么东西?)
- 都通过开发者工具进行抓包分析
- 分析视频播放url地址 是可以从哪里获取到
- 如果我们想要的数据内容 是 音频数据/视频数据 (media)
- 虽然说知道视频播放地址, 但是我们还需要知道这个播放地址 可以从什么地方获取
2.发送请求, 用python代码模拟浏览器对于目标地址发送请求
3.获取数据, 获取服务器给我们返回的数据内容
4.解析数据, 提取我们想要数据内容, 视频标题/视频url地址
5.保存数据
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
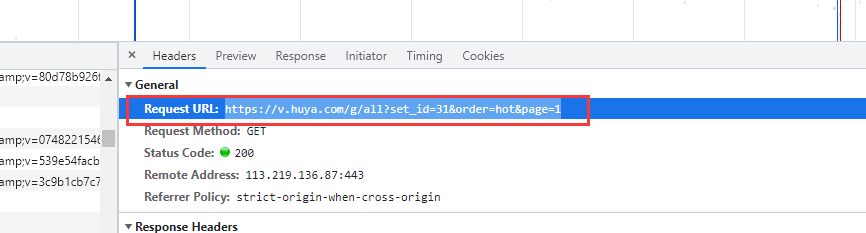
分析目标url
先打开一个视频,查看id

打开开发者工具,查找
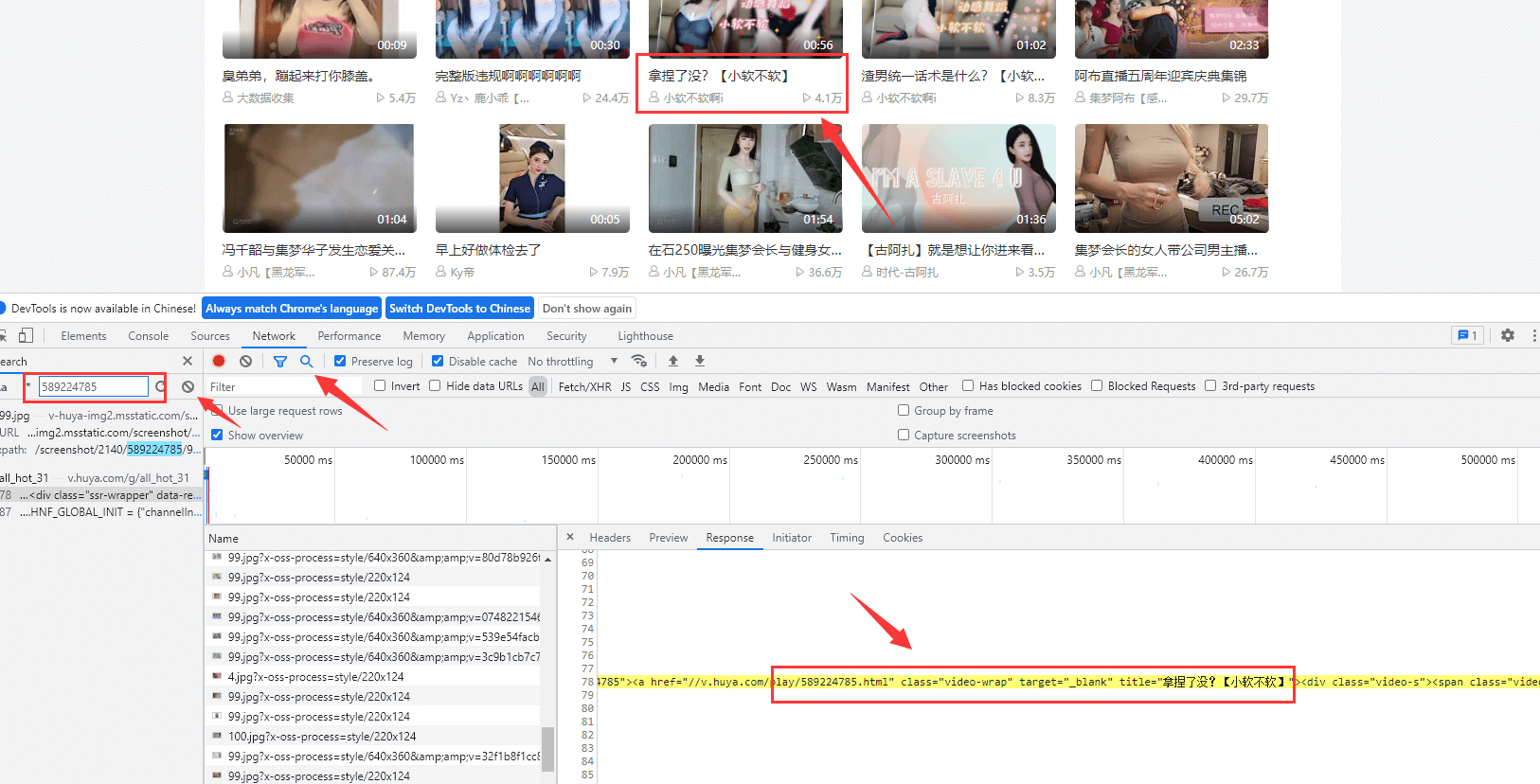
拿到目标url
开始代码
最开始还是线导入所需模块
import requests # 数据请求模块 pip install requests (第三方模块) import pprint # 格式化输出模块 内置模块 不需要安装 import re # 正则表达式 import json
数据请求
def get_response(html_url):
# 用python代码模拟浏览器
# headers 把python代码进行伪装
# user-agent 浏览器的基本标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 用代码直接获取的 一般大多数都是直接 cookie
response = requests.get(url=html_url, headers=headers)
return response
获取视频标题以及url地址
def get_video_info(video_id):
html_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={video_id}&uid=&_=1634127164373'
response = get_response(html_url)
title = response.json()['data']['moment']['title'] # 视频标题
video_url = response.json()['data']['moment']['videoInfo']['definitions'][0]['url']
video_info = [title, video_url]
return video_info
获取视频id
def get_video_id(html_url):
html_data = get_response(html_url).text
result = re.findall('<script> window.HNF_GLOBAL_INIT = (.*?) </script>', html_data)[0]
# 需要把获取的字符串数据, 转成json字典数据
json_data = json.loads(result)['videoData']['videoDataList']['value']
# json_data 列表 里面元素是字典
# print(json_data)
video_ids = [i['vid'] for i in json_data] # 列表推导式
# lis = []
# for i in json_data:
# lis.append(i['vid'])
# print(video_ids)
# print(type(json_data))
return video_ids
# 目光所至 我皆可爬
def main(html):
video_ids = get_video_id(html_url=html)
for video_id in video_ids:
video_info = get_video_info(video_id)
save(video_info[0], video_info[1])
保存数据
def save(title, video_url):
# 保存数据, 也是还需要对于播放地址发送请求的
# response.content 获取响应的二进制数据
video_content = get_response(html_url=video_url).content
new_title = re.sub(r'[\/:*?"<>|]', '_', title)
# 'video\\' + title + '.mp4' 文件夹路径以及文件名字 mode 保存方式 wb二进制保存方式
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print('保存成功: ', title)
调用函数
if __name__ == '__main__':
# get_video_info('589462235')
video_info = get_video_info('589462235')
save(video_info[0], video_info[1])
for page in range(1, 6):
print(f'正在爬取第{page}页的数据内容')
# python基础入门课程 第一节课 讲解的知识点 字符串格式化方法
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
main(url)
运行代码,得到数据

加载全部内容