Python机器学习多层感知机 Python机器学习多层感知机原理解析
Supre_yuan 人气:0隐藏层
我们在前面描述了仿射变换,它是一个带有偏置项的线性变换。首先,回想下之前下图中所示的softmax回归的模型结构。该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作。如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了。但是,仿射变换中的线性是一个很强的假设。
我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用。在此表示的基础上建立一个线性模型可能会是合适的,但我们不知道如何手动计算这么一种表示。对于深度神经网络,我们使用观测数据来联合学习隐藏层表示和应用于该表示的线性预测器。
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制,使其能处理更普遍的函数关系类型。要做到这一点,最简单的方法是将许多全连接层堆叠在一起。每一层都输出到上面的层,直到生成最后的输出。我们可以把前L−1层看作表示,把最后一层看作线性预测器。这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。下面,我们以图的方式描述了多层感知机。

这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算;因此,这个多层感知机的层数为2。注意,这个层都是全连接的。每个输入都会影响隐藏层中的每个神经元,而隐藏层中的每个神经元又会影响输出层的每个神经元。
然而,具有全连接层的多层感知机的参数开销可能会高得令人望而却步,即使在不改变输入和输出大小的情况下,也可能促使在参数节约和模型有效性之间进行权衡。
从线性到非线性

注意,在添加隐藏层之后,模型现在需要跟踪和更新额外的参数。
可我们能从中得到什么好处呢?这里我们会惊讶地发现:在上面定义的模型里,我们没有好处。上面的隐藏单元由输入的仿射函数给出,而输出(softmax操作前)只是隐藏单元的仿射函数。仿射函数的仿射函数本身就是仿射函数。但是我们之前的线性模型已经能够表示任何仿射函数。

由于 X中的每一行对应于小批量中的一个样本,处于记号习惯的考量,我们定义非线性函数 σ也以按行的方式作用于其输入,即一次计算一个样本。我们在之前以相同的方式使用了softmax符号来表示按行操作。但是在本节中,我们应用于隐藏层的激活函数通常不仅仅是按行的,而且也是按元素。这意味着在计算每一层的线性部分之后,我们可以计算每个激活值,而不需要查看其他隐藏单元所取的值。对于大多数激活函数都是这样。
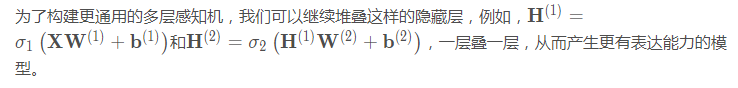
激活函数
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活。它们是输入信号转换为输出的可微运算。大多数激活函数都是非线性的。由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
import torch from d2l import torch as d2l
ReLU函数
最受欢迎的选择是线性整流单元,因为它实现简单,同时在各种预测任务中表现良好。ReLU提供了一种非常简单的非线性变换。给定元素x ,ReLU函数被定义为该元素与0的最大值:
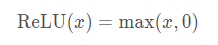
通俗地说,ReLU函数通过将相应的激活值设为0来仅保留正元素并丢弃所有负元素。为了直观感受下,我们可以画出函数的曲线图。下图所示,激活函数是分段线性的。
x = torch.arange(-8, 8, 0.1, requires_grad=True) y = torch.relu(x) d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
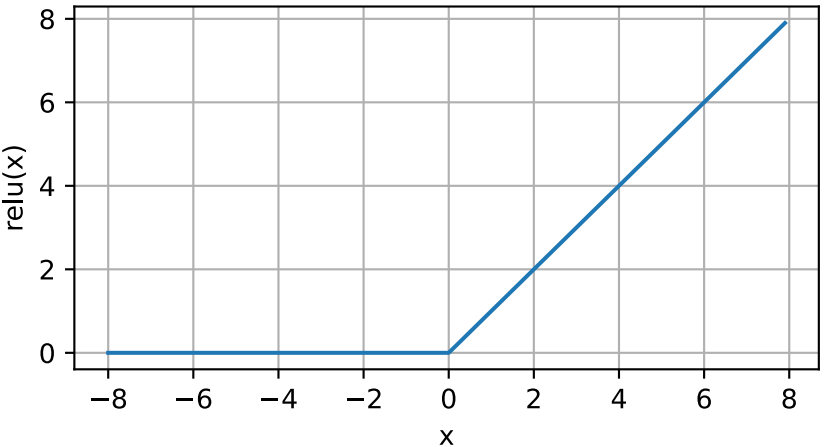
注意,当输入值精确等于0时,ReLU函数不可导。在此时,我们默认使用左侧的导数,即当输入为0时导数为0。我们可以忽略这种情况,因为输入可能永远都不会是0。这里用上一句古老的谚语,“如果微妙的边界条件很重要,我们很可能是在研究数学而非工程”,这个观点正好适用于这里。下面我们绘制ReLU函数的导数。
y.backward(torch.ones_ilke(x), retain_graph=True) d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))
使用ReLU的原因是,它求导表现得特别好,要么让参数消失,要么让参数通过。这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络梯度消失问题。
注意,ReLU函数有许多变体,包括参数化ReLU函数(Parameterized ReLU)。该变体为ReLU添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:
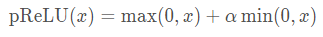
sigmoid函数

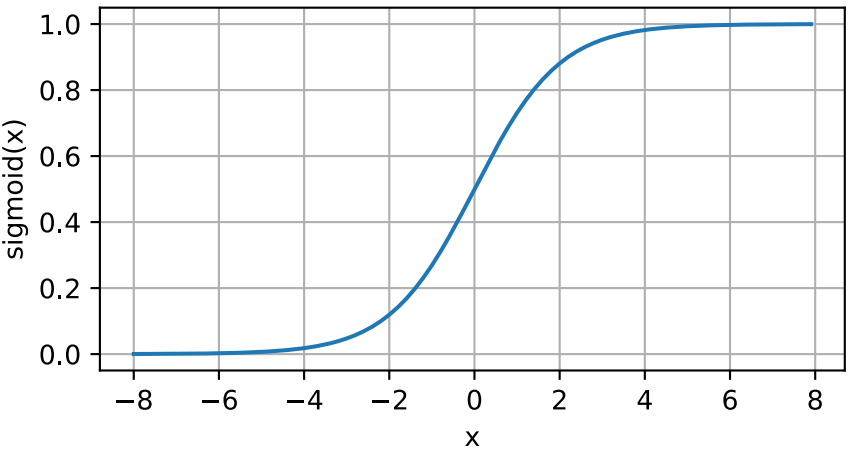
在最早的神经网络中,科学家们感兴趣的是对“激发”或“不激发”的生物神经元进行建模。因此,这一领域的先驱,如人工神经元的发明者麦卡洛克和皮茨,从他们开始就专注于阈值单元。阈值单元在其输入低于某个阈值时取值为0,当输入超过阈值时取1。
当人们的注意力逐渐转移到梯度的学习时,sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。当我们想要将输出视作二分类问题的概率时,sigmoid仍然被广泛用作输出单元上的激活函数(可以将sigmoid视为softmax的特例)。然而, sigmoid在隐藏层中已经较少使用,它在大部分时候已经被更简单、更容易训练的ReLU所取代。
tanh函数
与sigmoid函数类似,tanh(双曲正切)函数也能将其输入压缩转换到区间(-1,1)上。tanh函数的公式如下:
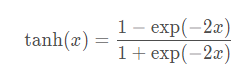
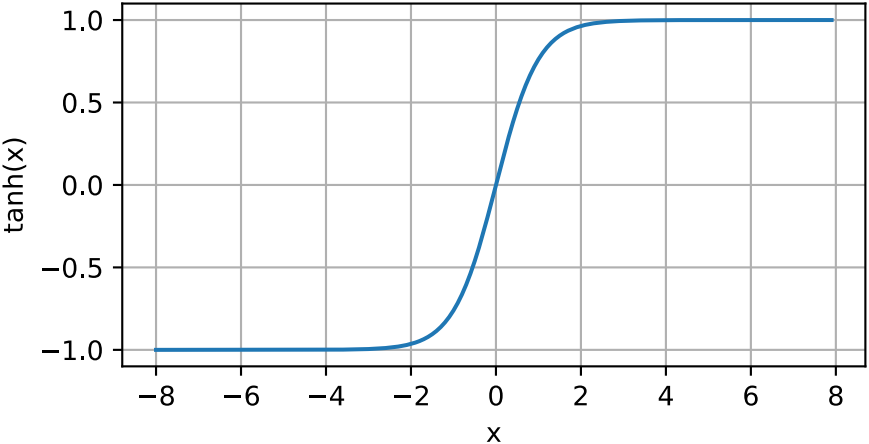
下面我们绘制tanh函数。注意,当输入在0附近时,tanh函数接近线性变换。函数的形状类似于sigmoid函数,不同的是tanh函数关于坐标系原点中心对称。
以上就是Python机器学习多层感知机原理解析的详细内容,更多关于Python机器学习多层感知机的资料请关注其它相关文章!
加载全部内容