Python易语言验证码 Python调用易语言动态链接库实现验证码功能
python可乐编程 人气:0想了解Python调用易语言动态链接库实现验证码功能的相关内容吗,python可乐编程在本文为您仔细讲解Python易语言验证码的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python易语言验证码,Python易语言动态链接库,下面大家一起来学习吧。

今天成功把易语言调用验证码通杀的DLL在Python中成功调用了
特此共享出来,下面是识别截图:

识别方法1:
"""当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢? 学习Python中有不明白推荐加入交流群号:928946953 群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF!还有大牛解答!"""
# 来源:http://www.sanye.cx/?id=12022
# 优点:载入快、识别速度高、识别精度较高
# 缺点:仅在32位Python环境中成功运行
# 获取上级目录
path = os.path.abspath(os.path.dirname(os.getcwd()))
# 获取验证码文件夹
img_list = os.listdir(path + r"\captcha")
# 载入识别库
dll = cdll.LoadLibrary(path + r"\ocr1\ocr.dll")
# 初始化识别库
dll.init()
# 遍历图片并识别
for i in img_list:
# 读入图片
with open(path + r"\captcha\{0}".format(i), "rb") as file:
# 读入图片
image = file.read()
# 利用dll中的ocr函数进行识别
Str = dll.ocr(image, len(image))
# 返回的是指针,所以此处将指针转换为字符串,然后再编码即可得到字符串类型
text = string_at(Str).decode("utf-8")
print(f"识别返回:{text},类型:{type(text)},ID地址:{id(text)}")
识别方法2:
# 来源:[url=https://www.52pojie.cn/thread-1072587-1-1.html]https://www.52pojie.cn/thread-1072587-1-1.html[/url]
# 优点:识别速度高、识别精度高
# 缺点:仅在32位Python环境中成功运行、载入时间较长
# 获取上级目录
path = os.path.abspath(os.path.dirname(os.getcwd()))
# 载入识别库
dll = cdll.LoadLibrary(path + r"\ocr2\OCRS.dll")
# 载入字库与建立字库索引
with open(path + r"\ocr2\通杀英文数字库.cnn", "rb") as file:
# 载入字库
word_bank = file.read()
# 建立字库索引
work_index = dll.INIT(path, word_bank, len(word_bank), -1, 1)
# 读入待识别图片列表
img_list = os.listdir(path + "\captcha")
# 循环识别图片并输出
for i in img_list:
# 打开指定图片
with open(path + "\captcha\{0}".format(i), "rb") as file_img:
# 读入图片
image = file_img.read()
Str = create_string_buffer(100) # 创建文本缓冲区
dll.OCR(work_index, image, len(image), Str) # 利用DLL中的识别函数进行识别
text = Str.raw.decode("utf-8") # 对识别的返回值进行编码
print(f"识别返回:{text},类型:{type(text)},ID地址:{id(text)}")

1.自己弄了一个类,下载下来直接使用,调用方法:
dll = Ver_code_1(DLL文件所在的文件夹目录) #或者 dll = Ver_code_2(DLL文件所在的文件夹目录) #识别图片: dll.ocr(图片)
2.修正了识别库2空白字符未消除,无法正确判断长度的问题(可以利用固定长度判断是否符合,进行初步筛选,避免提交后网页返回验证码错误)
import os
from ctypes import *
class Ver_code_1:
# 启动时需要传入ocr.dll
def __init__(self, path):
# 载入识别库
self.dll = cdll.LoadLibrary(path + r"\ocr.dll")
# 初始化识别库
self.dll.init()
def ocr(self, image):
Str = self.dll.ocr(image, len(image))
# 返回的是指针,所以此处将指针转换为字符串,然后再编码即可得到字符串类型
return string_at(Str).decode("utf-8")
class Ver_code_2:
def __init__(self, path):
# 载入识别库
self.dll = cdll.LoadLibrary(path + r"\OCRS.dll")
# 载入字库与建立字库索引
with open(path + r"\通杀英文数字库.cnn", "rb") as file:
# 载入字库
self.word_bank = file.read()
# 建立字库索引
self.word_index = self.dll.INIT(path, self.word_bank, len(self.word_bank), -1, 1)
def ocr(self, image):
Str = create_string_buffer(100) # 创建文本缓冲区
self.dll.OCR(self.word_index, image, len(image), Str) # 利用DLL中的识别函数进行识别
return Str.raw.decode("utf-8").rstrip('\x00') # 对识别的返回值进行编码后返回,这里的\x00是删除缓冲区的空白符
注意!测试环境为:
Python 3.9.2 (tags/v3.9.2:1a79785, Feb 19 2021, 13:30:23) [MSC v.1928 32 bit (Intel)] on win32
经测试,无法在64位环境下调用,如有大佬能实现,烦请告知一下
关于DLL改64位的思路:
我找到了论坛中的IDA pro,成功将DLL进行了反编译,如图:
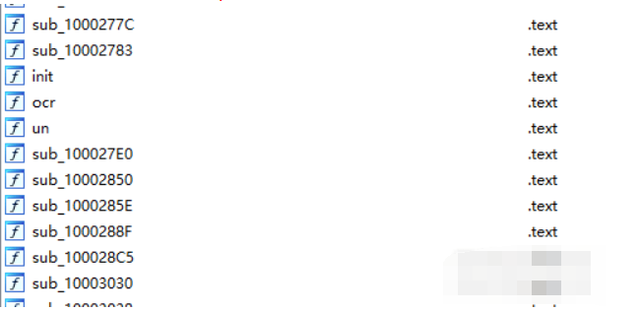
其实最关键的就是以上的init以及ocr两个函数,但是后续如何将IDA pro项目转换为64位,然后进行编译,目前没有找到合适的方法,如果有大佬麻烦告知一下。
加载全部内容