python人脸图像特征提取 Python中人脸图像特征提取方法(HOG、Dlib、CNN)简述
白码王子小张 人气:0人脸图像特征提取方法
(一)HOG特征提取
1、HOG简介
Histogram of Oriented Gridients,缩写为HOG,是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征。它的主要思想是在一副图像中,局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述。其本质为:梯度的统计信息,而梯度主要存在于边缘的地方。
2、实现方法
首先将图像分成小的连通区域,这些连通区域被叫做细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来,就可以构成特征描述符。将这些局部直方图在图像的更大的范围内(叫做区间)进行对比度归一化,可以提高该算法的性能,所采用的方法是:先计算各直方图在这个区间中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更好的效果。
3、HOG特征提取优点
由于HOG是 在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。HOG特征是特别适合于做图像中的人体检测的 。
4、HOG特征提取步骤
(1)色彩和伽马归一化
为了减少光照因素的影响,首先需要将整个图像进行规范化(归一化)。在图像的纹理强度中,局部的表层曝光贡献的比重较大,所以,这种压缩处理能够有效地降低图像局部的阴影和光照变化。
(2)计算图像梯度
计算图像横坐标和纵坐标方向的梯度,并据此计算每个像素位置的梯度方向值;求导操作不仅能够捕获轮廓,人影和一些纹理信息,还能进一步弱化光照的影响。最常用的方法是:简单地使用一个一维的离散微分模板在一个方向上或者同时在水平和垂直两个方向上对图像进行处理,更确切地说,这个方法需要使用滤波器核滤除图像中的色彩或变化剧烈的数据
(3)构建方向直方图
细胞单元中的每一个像素点都为某个基于方向的直方图通道投票。投票是采取加权投票的方式,即每一票都是带有权值的,这个权值是根据该像素点的梯度幅度计算出来。可以采用幅值本身或者它的函数来表示这个权值,实际测试表明: 使用幅值来表示权值能获得最佳的效果,当然,也可以选择幅值的函数来表示,比如幅值的平方根、幅值的平方、幅值的截断形式等。细胞单元可以是矩形的,也可以是星形的。直方图通道是平均分布在0-1800(无向)或0-3600(有向)范围内。经研究发现,采用无向的梯度和9个直方图通道,能在行人检测试验中取得最佳的效果。

(4)将细胞单元组合成大的区间
由于局部光照的变化以及前景-背景对比度的变化,使得梯度强度的变化范围非常大。这就需要对梯度强度做归一化。归一化能够进一步地对光照、阴影和边缘进行压缩。
采取的办法是:把各个细胞单元组合成大的、空间上连通的区间。这样,HOG描述符就变成了由各区间所有细胞单元的直方图成分所组成的一个向量。这些区间是互有重叠的,这就意味着:每一个细胞单元的输出都多次作用于最终的描述器。
区间有两个主要的几何形状——矩形区间(R-HOG)和环形区间(C-HOG)。R-HOG区间大体上是一些方形的格子,它可以有三个参数来表征:每个区间中细胞单元的数目、每个细胞单元中像素点的数目、每个细胞的直方图通道数目。
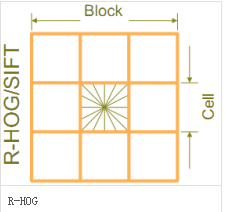
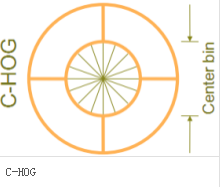
(5)收集HOG特征
把提取的HOG特征输入到SVM分类器中,寻找一个最优超平面作为决策函数。
(二)Dlib库
1、Dlib简介
Dlib是一个现代化的C ++工具箱,其中包含用于在C ++中创建复杂软件以解决实际问题的机器学习算法和工具。它广泛应用于工业界和学术界,包括机器人,嵌入式设备,移动电话和大型高性能计算环境。Dlib的开源许可证允许您在任何应用程序中免费使用它。
2、Dlib特点
文档齐全高质量的可移植代码提供大量的机器学习和图像处理算法
(三)卷积神经网络特征提取(CNN)
1、卷积神经网络简介
卷积神经网络(Convolutional Neural Network)简称CNN,CNN是所有深度学习课程、书籍必教的模型,CNN在影像识别方面的为例特别强大,许多影像识别的模型也都是以CNN的架构为基础去做延伸。另外值得一提的是CNN模型也是少数参考人的大脑视觉组织来建立的深度学习模型,学会CNN之后,对于学习其他深度学习的模型也很有帮助,本文主要讲述了CNN的原理以及使用CNN来达成99%正确度的手写字体识别。
2、CNN网络结构
基础的CNN由 卷积(convolution), 激活(activation), and 池化(pooling)三种结构组成。CNN输出的结果是每幅图像的特定特征空间。当处理图像分类任务时,我们会把CNN输出的特征空间作为全连接层或全连接神经网络(fully connected neural network, FCN)的输入,用全连接层来完成从输入图像到标签集的映射,即分类。当然,整个过程最重要的工作就是如何通过训练数据迭代调整网络权重,也就是后向传播算法。目前主流的卷积神经网络(CNNs),比如VGG, ResNet都是由简单的CNN调整,组合而来。
(1)CNN
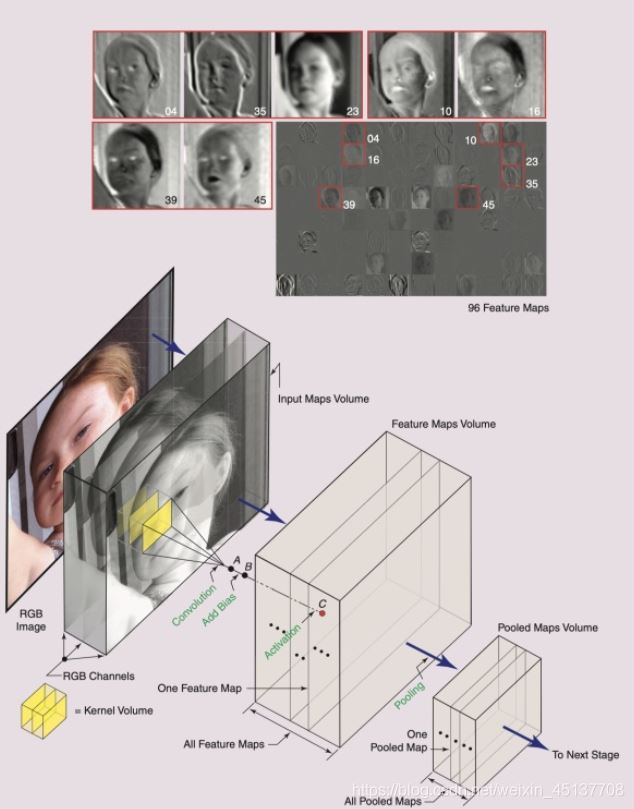
图中,一个stage中的一个CNN,通常会由三种映射空间组成:
输入映射空间(input maps volume)特征映射空间(feature maps volume)池化映射空间(pooled maps volume)
(2)卷积

注意卷积层的kernel可能不止一个,扫描步长,方向也有不同,进阶方式如下:
可以采用多个卷积核,设为n 同时扫描,得到的feature map会增加n个维度,通常认为是多抓取n个特征。可以采取不同扫描步长,比如上例子中采用步长为n, 输出是(510/n,510/n)padding,上例里,卷积过后图像维度是缩减的,可以在图像周围填充0来保证feature map与原始图像大小不变深度升降,例如采用增加一个1*1 kernel来增加深度,相当于复制一层当前通道作为feature map跨层传递feature map,不再局限于输入即输出, 例如ResNet跨层传递特征,Faster RCNN 的POI pooling
(3)激活
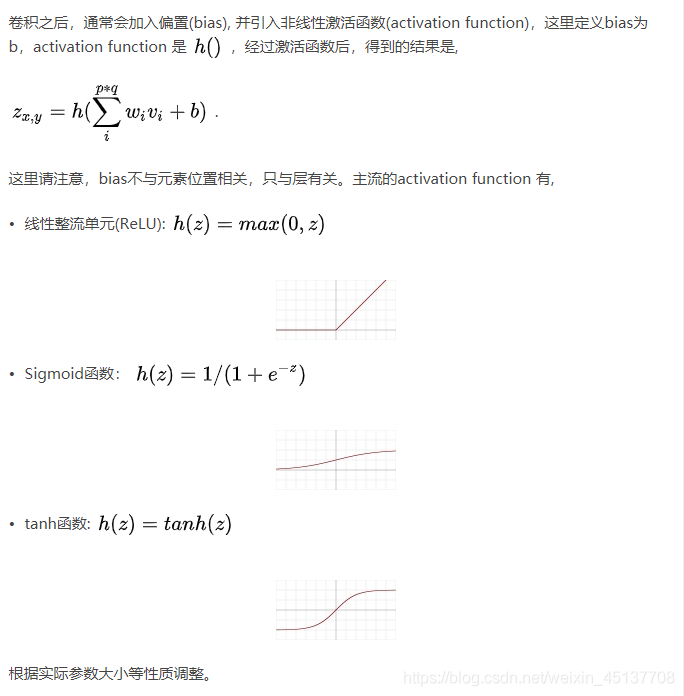
(4)池化
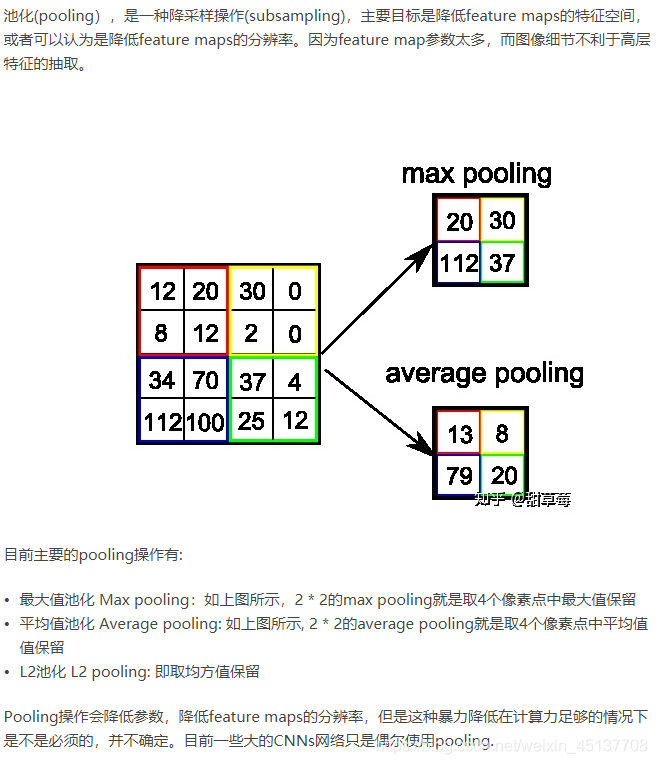
(5)全连接网络
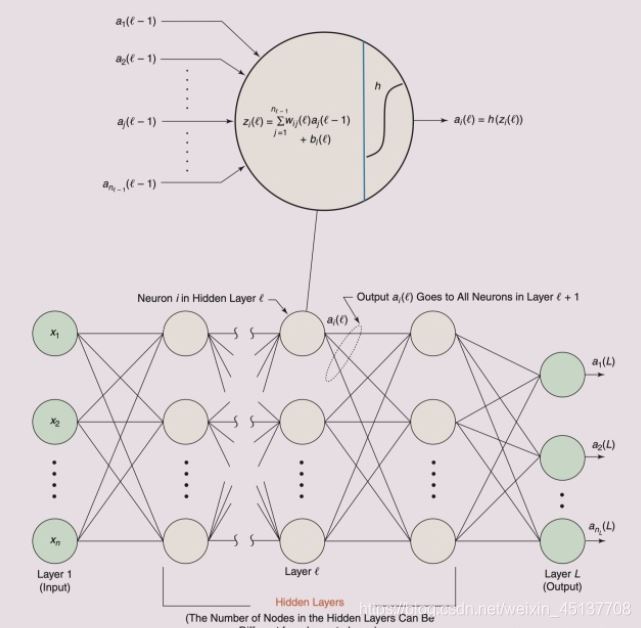
出现在CNN中的全连接网络(fully connected network)主要目的是为了分类, 这里称它为network的原因是,目前CNNs多数会采用多层全连接层,这样的结构可以被认为是网络。如果只有一层,下边的叙述同样适用。它的结构如下:

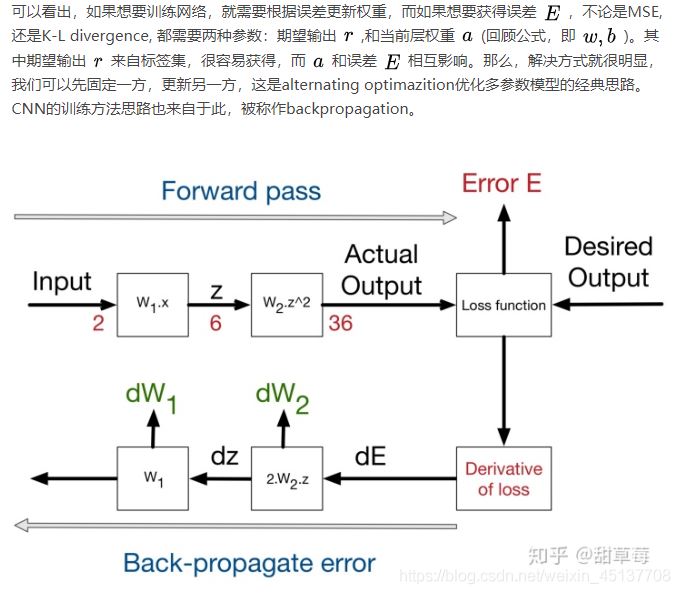
(6)目标函数和训练方法



加载全部内容