MySQL自增id用尽 线上MySQL的自增id用尽怎么办
JavaEdge. 人气:0MySQL的自增id都定义了初始值,然后不断加步长。虽然自然数没有上限,但定义了表示这个数的字节长度,计算机存储就有上限。比如,无符号整型(unsigned int)是4个字节,上限就是2^32 - 1。那自增id用完,会怎么样?
表定义自增值id
表定义的自增值达到上限后的逻辑是:再申请下一个id时,得到的值保持不变。
mysql> create table t(id int unsigned auto_increment primary key) auto_increment=4294967295; Query OK, 0 rows affected (0.01 sec) mysql> insert into t values(null); Query OK, 1 row affected (0.00 sec) mysql> show create table t; +-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | t | CREATE TABLE `t` ( `id` int unsigned NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4294967295 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci | +-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) //成功插入一行 4294967295 mysql> insert into t values(null); ERROR 1062 (23000): Duplicate entry '4294967295' for key 't.PRIMARY'
第一个insert成功后,该表的AUTO_INCREMENT还是4294967295,导致第二个insert又拿到相同自增id值,再试图执行插入语句,主键冲突。
2^32 - 1(4294967295)不是一个特别大的数,一个频繁插入删除数据的表是可能用完的。建表时就需要考虑你的表是否有可能达到该上限,若有,就应创建成8字节的bigint unsigned。
InnoDB系统自增row_id
若你创建的InnoDB表未指定主键,则InnoDB会自动创建一个不可见的,6个字节的row_id。InnoDB维护了一个全局的dict_sys->row_id值

所有无主键的InnoDB表,每插入一行数据,都将当前的dict_sys->row_id作为要插入数据的row_id,然后把dict_sys->row_id加1。
代码实现时row_id是个长度为8字节的无符号长整型(bigint unsigned)。但InnoDB在设计时,给row_id留的只是6个字节的长度,这样写到数据表中时只放了最后6个字节,所以row_id能写到数据表中的值,就有两个特征:
- row_id写入表中的值范围,是从0到2^48 - 1
- 当
dict_sys.row_id=2^48时,如果再有插入数据的行为要来申请row_id,拿到以后再取最后6个字节的话就是0
即写入表的row_id从0~2^48 - 1。达到上限后,下个值就是0,然后继续循环。
2^48 - 1已经很大,但若一个MySQL实例活得久,还是可能达到上限。
InnoDB里,申请到row_id=N后,就将这行数据写入表中;若表中已经存在row_id=N的行,新写入的行就会覆盖原有的行。
验证该结论:通过gdb修改系统的自增row_id。用gdb是为了便于复现问题,只能在测试环境使用。
row_id用完的验证序列
 row_id
row_id
用完的效果验证
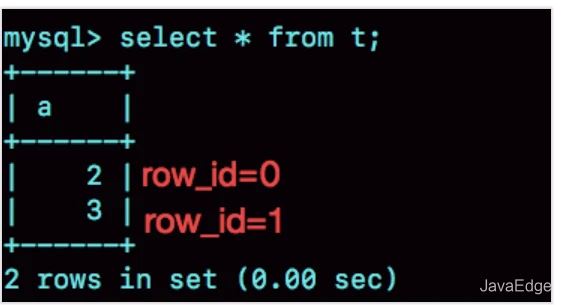
可见,在我用gdb将dict_sys.row_id设置为2^48之后,再插入a=2会出现在表t的第一行,因为该值的row_id=0。
之后再插入a=3,由于row_id=1,就覆盖了之前a=1的行,因为a=1这一行的row_id也是1。
所以应该在InnoDB表中主动创建自增主键:当表自增id到达上限后,再插入数据时会报主键冲突错误。
毕竟覆盖数据,就意味着数据丢失,影响数据可靠性;报主键冲突,插入失败,影响可用性。一般可靠性优于可用性。
Xid
redo log和binlog有个共同字段Xid,用来对应事务。Xid在MySQL内部是如何生成的呢?
MySQL内部维护了一个全局变量global_query_id
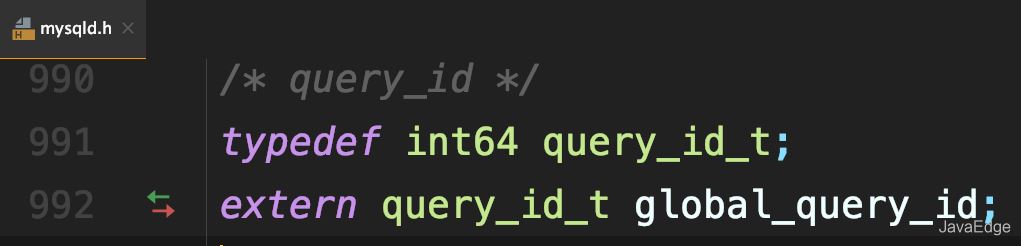
每次执行语句时,将它赋值给query_id,然后给该变量+1:
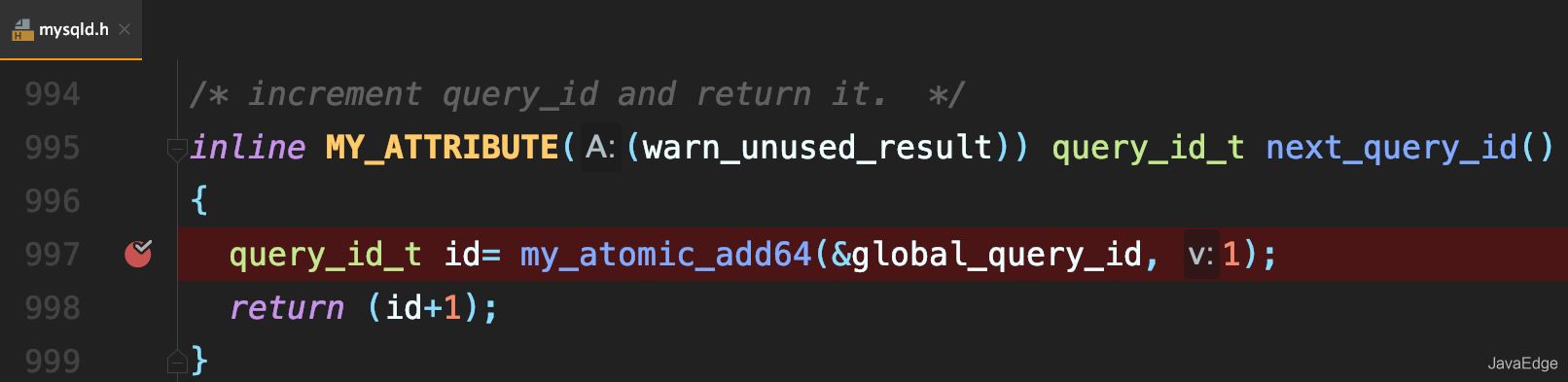
若当前语句是该事务执行的第一条语句,则MySQL还会同时把query_id赋值给该事务的Xid:
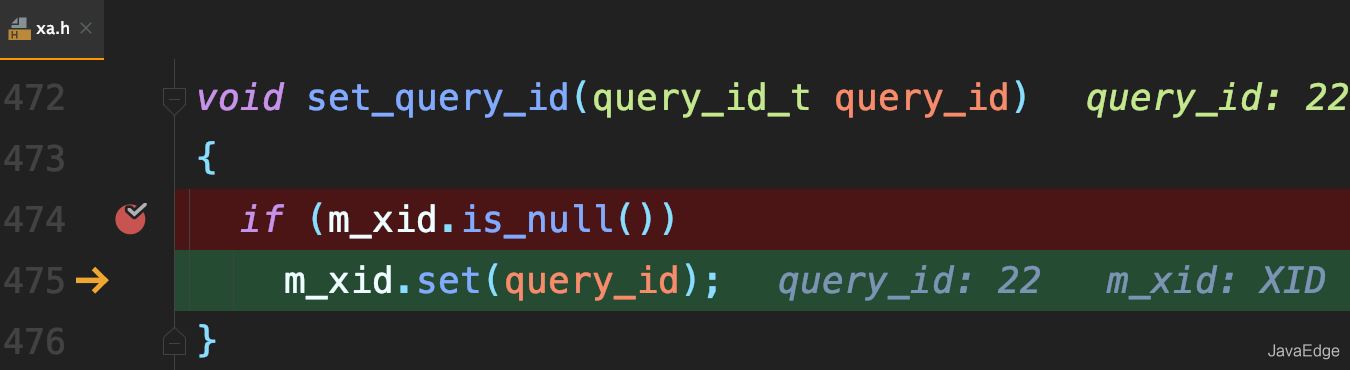
而global_query_id是一个纯内存变量,重启之后就清零了。所以同一DB实例,不同事务的Xid可能相同。
但MySQL重启之后会重新生成新binlog文件,这就保证同一个binlog文件里的Xid唯一。
虽然MySQL重启不会导致同一个binlog里面出现两个相同Xid,但若global_query_id达到上限,就会继续从0开始计数。理论上还是会出现同一个binlog里面出现相同Xid。
因为global_query_id8字节,上限2^64 - 1。要出现这种情况,需满足:
- 执行一个事务,假设Xid是A
- 接下来执行
2^64次查询语句,让global_query_id回到A 2^64太大了,这种可能只存在于理论中。- 再启动一个事务,这个事务的Xid也是A
Innodb trx_id
Xid由server层维护
InnoDB内部使用Xid,为了关联InnoDB事务和server
但InnoDB自己的trx_id,是另外维护的事务id(transaction id)。
InnoDB内部维护了一个max_trx_id全局变量,每次需要申请一个新的trx_id时,就获得max_trx_id的当前值,然后并将max_trx_id加1。
InnoDB数据可见性的核心思想
每一行数据都记录了更新它的trx_id,当一个事务读到一行数据时,判断该数据是否可见,就是通过事务的一致性视图与这行数据的trx_id做对比。
对于正在执行的事务,你可以从information_schema.innodb_trx表中看到事务的trx_id。
看如下案例:事务的trx_id
| S1 | S2 | |
|---|---|---|
| t1 | begin select * from t limit 1 |
|
| t2 | use information_schema; select trx_id, trx_mysql_thread_id from innodb_trx |
|
| t3 | insert into t values(null) | |
| t3 | select trx_id, trx_mysql_thread_id from innodb_trx |
S2 的执行记录:
mysql> use information_schema; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select trx_id, trx_mysql_thread_id from innodb_trx; +-----------------+---------------------+ | trx_id | trx_mysql_thread_id | +-----------------+---------------------+ | 421972504382792 | 70 | +-----------------+---------------------+ 1 row in set (0.00 sec) mysql> select trx_id, trx_mysql_thread_id from innodb_trx; +---------+---------------------+ | trx_id | trx_mysql_thread_id | +---------+---------------------+ | 1355623 | 70 | +---------+---------------------+ 1 row in set (0.01 sec)
S2从innodb_trx表里查出的这两个字段,第二个字段trx_mysql_thread_id就是线程id。显示线程id,是为说明这两次查询看到的事务对应的线程id都是5,即S1所在线程。
t2时显示的trx_id是一个很大的数;t4时刻显示的trx_id是1289,看上去是一个比较正常的数字。这是为啥?
t1时,S1还未涉及更新,是一个只读事务。对于只读事务,InnoDB并不会分配trx_id:
- t1时,trx_id的值就是0。而这个很大的数,只是显示用
- 直到S1在t3时执行insert,InnoDB才真正分配trx_id。所以t4时,S2查到该trx_id的值就是1289。
除了明显的修改类语句,若在select 语句后面加上for update,也不是只读事务。
- update 和 delete语句除了事务本身,还涉及到标记删除旧数据,即要把数据放到purge队列里等待后续物理删除,这个操作也会把max_trx_id+1, 因此在一个事务中至少加2
- InnoDB的后台操作,比如表的索引信息统计这类操作,也是会启动内部事务的,因此你可能看到,trx_id值并不是按照加1递增的。
t2时查到的很大数字是怎么来的?
每次查询时,由系统临时计算:当前事务的trx变量的指针地址转成整数,再加上248
这样可以保证:
- 因为同一只读事务在执行期间,它的指针地址不会变,所以无论在 innodb_trx还是在innodb_locks表里,同一个只读事务查出来的trx_id就会是一样的
- 若有并行只读事务,每个事务的trx变量的指针地址肯定不同。这样,不同并发只读事务,查出来的trx_id就是不同的。
为什么要加248?
保证只读事务显示的trx_id值比较大,正常情况下就会区别于读写事务的id。但trx_id跟row_id的逻辑类似,定义为8个字节。
理论上还是可能出现一个读写事务与一个只读事务显示的trx_id相同。不过概率很低,也没有什么实质危害,不管。
为何只读事务不分配trx_id?
- 减小事务视图里面活跃事务数组的大小。因为当前正在运行的只读事务,不影响数据的可见性判断。所以,在创建事务的一致性视图时,InnoDB就只需要拷贝读写事务的trx_id
- 减少trx_id的申请次数。InnoDB执行一个普通的select语句,也要对应一个只读事务。所以只读事务优化后,普通查询语句无需申请trx_id,大大减少并发事务申请trx_id的锁冲突
由于只读事务不分配trx_id,显然trx_id的增速变慢。
但 max_trx_id 会持久化存储,重启也不会重置为0。理论上,只要一个MySQL实例跑得够久,就可能出现max_trx_id达到2^48 - 1,然后从0开始循环。
达到该状态后,MySQL就会持续出现一个脏读bug:
首先把当前的max_trx_id先修改成2^48 - 1。这里是可重复读。
复现脏读

因为系统的max_trx_id被设置成2^48 - 1,所以在session A启动的事务TA的低水位就是2^48 - 1。
t2时:
- session B执行第一条update语句的
事务id=2^48 - 1 - 第二条事务id就是0了,这条update执行后生成的数据版本上的
trx_id=0
t3时:
session A执行select的可见性判断:c=3这个数据版本的trx_id(0),小于事务TA的低水位(2^48 - 1),所以认为该数据可见。
但这是脏读。
由于低水位值会持续增加,而事务id从0开始计数,导致系统在该时刻后,所有查询都会出现脏读。
并且MySQL重启时max_trx_id也不会清0,即重启MySQL,这个bug仍然存在。那这bug也是只存在于理论上吗?
假设一个MySQL实例的TPS是50w,持续这样,17.8年后就会出现该情况。但从MySQL真正开始流行到现在,恐怕都还没有实例跑到过这个上限。不过,只要MySQL实例服务时间够长,就必然会出现该bug。
这也可以加深对低水位和数据可见性的理解。
thread_id
系统保存了一个全局变量thread_id_counter
每新建一个连接,就将thread_id_counter赋值给这个新连接的线程变量new_id。
thread_id_counter定义为4个字节,因此达到2^32 - 1,就会重置为0,继续增加。

但不会在show processlist看到两个相同的thread_id。因为MySQL使用了一个唯一数组

给新线程分配thread_id时的逻辑:

总结
每种自增id有各自的应用场景,在达到上限后的表现也不同:
- 表的自增id达到上限后,再申请时它的值就不会改变,进而导致继续插入数据时报主键冲突错误
- row_id达到上限后,则会归0再重新递增,如果出现相同的row_id,后写的数据会覆盖之前的数据
- Xid只需要不在同一个binlog文件中出现重复值即可。虽然理论上会出现重复值,但是概率极小,可以忽略不计
- InnoDB的max_trx_id 递增值每次MySQL重启都会被保存起来,所以我们文章中提到的脏读的例子就是一个必现的bug,好在留给我们的时间还很充裕
加载全部内容