Java fork/join框架 轻轻松松吃透Java并发fork/join框架
索取~~ 人气:0Fork / Join 是一个工具框架 , 其核心思想在于将一个大运算切成多个小份 , 最大效率的利用资源 , 其主要涉及到三个类 : ForkJoinPool / ForkJoinTask / RecursiveTask
一、概述
java.util.concurrent.ForkJoinPool由Java大师Doug Lea主持编写,它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。本文中对Fork/Join框架的讲解,基于JDK1.8+中的Fork/Join框架实现,参考的Fork/Join框架主要源代码也基于JDK1.8+。
文章将首先先谈谈recursive task,然后讲解Fork/Join框架的基本使用;接着结合Fork/Join框架的工作原理来理解其中需要注意的使用要点;最后再讲解使用Fork/Join框架解决一些实际问题。
二、说一说 RecursiveTask
RecursiveTask 是一种 ForkJoinTask 的递归实现 , 例如可以用于计算斐波那契数列 :
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) { this.n = n; }
Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
RecursiveTask 继承了 ForkJoinTask 接口 ,其内部有几个主要的方法:
// Node 1 : 返回结果 , 存放最终结果
V result;
// Node 2 : 抽象方法 compute , 用于计算最终结果
protected abstract V compute();
// Node 3 : 获取最终结果
public final V getRawResult() {
return result;
}
// Node 4 : 最终执行方法 , 这里是需要调用具体实现类compute
protected final boolean exec() {
result = compute();
return true;
}
常见使用方式:
@
public class ForkJoinPoolService extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2; //阀值
private int start;
private int end;
public ForkJoinPoolService(Integer start, Integer end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start + end) / 2;
ForkJoinPoolService leftTask = new ForkJoinPoolService(start, middle);
ForkJoinPoolService rightTask = new ForkJoinPoolService(middle + 1, end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到其结果
Integer rightResult = rightTask.join();
Integer leftResult = leftTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
}
三、 Fork/Join框架基本使用
这里是一个简单的Fork/Join框架使用示例,在这个示例中我们计算了1-1001累加后的值:
/**
* 这是一个简单的Join/Fork计算过程,将1—1001数字相加
*/
public class TestForkJoinPool {
private static final Integer MAX = 200;
static class MyForkJoinTask extends RecursiveTask<Integer> {
// 子任务开始计算的值
private Integer startValue;
// 子任务结束计算的值
private Integer endValue;
public MyForkJoinTask(Integer startValue , Integer endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Integer compute() {
// 如果条件成立,说明这个任务所需要计算的数值分为足够小了
// 可以正式进行累加计算了
if(endValue - startValue < MAX) {
System.out.println("开始计算的部分:startValue = " + startValue + ";endValue = " + endValue);
Integer totalValue = 0;
for(int index = this.startValue ; index <= this.endValue ; index++) {
totalValue += index;
}
return totalValue;
}
// 否则再进行任务拆分,拆分成两个任务
else {
MyForkJoinTask subTask1 = new MyForkJoinTask(startValue, (startValue + endValue) / 2);
subTask1.fork();
MyForkJoinTask subTask2 = new MyForkJoinTask((startValue + endValue) / 2 + 1 , endValue);
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
}
public static void main(String[] args) {
// 这是Fork/Join框架的线程池
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> taskFuture = pool.submit(new MyForkJoinTask(1,1001));
try {
Integer result = taskFuture.get();
System.out.println("result = " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
}
}
以上代码很简单,在关键的位置有相关的注释说明。这里本文再对以上示例中的要点进行说明。首先看看以上示例代码的可能执行结果:
开始计算的部分:startValue = 1;endValue = 126
开始计算的部分:startValue = 127;endValue = 251
开始计算的部分:startValue = 252;endValue = 376
开始计算的部分:startValue = 377;endValue = 501
开始计算的部分:startValue = 502;endValue = 626
开始计算的部分:startValue = 627;endValue = 751
开始计算的部分:startValue = 752;endValue = 876
开始计算的部分:startValue = 877;endValue = 1001
result = 501501
四、工作顺序图
下图展示了以上代码的工作过程概要,但实际上Fork/Join框架的内部工作过程要比这张图复杂得多,例如如何决定某一个recursive task是使用哪条线程进行运行;再例如如何决定当一个任务/子任务提交到Fork/Join框架内部后,是创建一个新的线程去运行还是让它进行队列等待。
所以如果不深入理解Fork/Join框架的运行原理,只是根据之上最简单的使用例子观察运行效果,那么我们只能知道子任务在Fork/Join框架中被拆分得足够小后,并且其内部使用多线程并行完成这些小任务的计算后再进行结果向上的合并动作,最终形成顶层结果。不急,一步一步来,我们先从这张概要的过程图开始讨论。

图中最顶层的任务使用submit方式被提交到Fork/Join框架中,后者将前者放入到某个线程中运行,工作任务中的compute方法的代码开始对这个任务T1进行分析。如果当前任务需要累加的数字范围过大(代码中设定的是大于200),则将这个计算任务拆分成两个子任务(T1.1和T1.2),每个子任务各自负责计算一半的数据累加,请参见代码中的fork方法。如果当前子任务中需要累加的数字范围足够小(小于等于200),就进行累加然后返回到上层任务中。
1、ForkJoinPool构造函数
ForkJoinPool有四个构造函数,其中参数最全的那个构造函数如下所示:
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode)
- parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量,也不要将这个属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性进行比较,因为ForkJoinPool的组织结构和工作方式与后者完全不一样。而后续的讨论中,读者还可以发现Fork/Join框架中可存在的线程数量和这个参数值的关系并不是绝对的关联(有依据但并不全由它决定)。
- factory:当Fork/Join框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactory接口,而是需要实现ForkJoinWorkerThreadFactory接口。后者是一个函数式接口,只需要实现一个名叫newThread的方法。在Fork/Join框架中有一个默认的ForkJoinWorkerThreadFactory接口实现:DefaultForkJoinWorkerThreadFactory。
- handler:异常捕获处理器。当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
- asyncMode:这个参数也非常重要,从字面意思来看是指的异步模式,它并不是说Fork/Join框架是采用同步模式还是采用异步模式工作。Fork/Join框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。即是说存在于队列中的待执行任务,即可以使用先进先出的工作模式,也可以使用后进先出的工作模式。
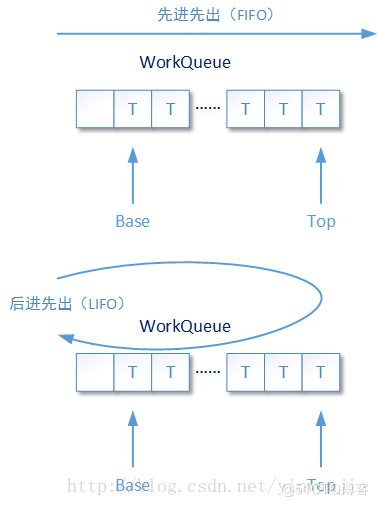
当asyncMode设置为ture的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false
...... asyncMode ? FIFO_QUEUE : LIFO_QUEUE, ......
ForkJoinPool还有另外两个构造函数,一个构造函数只带有parallelism参数,既是可以设定Fork/Join框架的最大并行任务数量;另一个构造函数则不带有任何参数,对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量(Runtime.getRuntime().availableProcessors())。实际上ForkJoinPool还有一个私有的、原生构造函数,之上提到的三个构造函数都是对这个私有的、原生构造函数的调用。
......
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
......
如果你对Fork/Join框架没有特定的执行要求,可以直接使用不带有任何参数的构造函数。也就是说推荐基于当前操作系统可以使用的CPU内核数作为Fork/Join框架内最大并行任务数量,这样可以保证CPU在处理并行任务时,尽量少发生任务线程间的运行状态切换(实际上单个CPU内核上的线程间状态切换基本上无法避免,因为操作系统同时运行多个线程和多个进程)。
2、fork方法和join方法
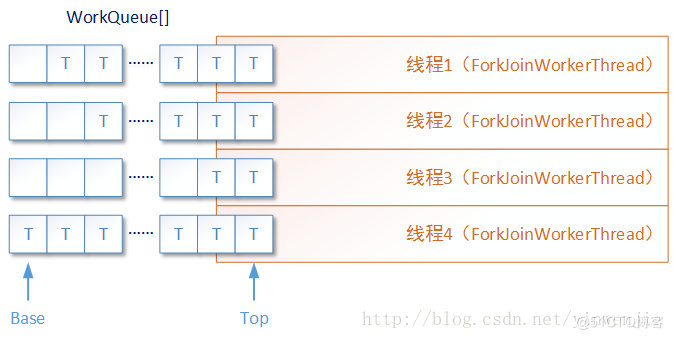
Fork/Join框架中提供的fork方法和join方法,可以说是该框架中提供的最重要的两个方法,它们和parallelism“可并行任务数量”配合工作,可以导致拆分的子任务T1.1、T1.2甚至TX在Fork/Join框架中不同的运行效果。例如TX子任务或等待其它已存在的线程运行关联的子任务,或在运行TX的线程中“递归”执行其它任务,又或者启动一个新的线程运行子任务……
fork方法用于将新创建的子任务放入当前线程的work queue队列中,Fork/Join框架将根据当前正在并发执行ForkJoinTask任务的ForkJoinWorkerThread线程状态,决定是让这个任务在队列中等待,还是创建一个新的ForkJoinWorkerThread线程运行它,又或者是唤起其它正在等待任务的ForkJoinWorkerThread线程运行它。
这里面有几个元素概念需要注意,ForkJoinTask任务是一种能在Fork/Join框架中运行的特定任务,也只有这种类型的任务可以在Fork/Join框架中被拆分运行和合并运行。ForkJoinWorkerThread线程是一种在Fork/Join框架中运行的特性线程,它除了具有普通线程的特性外,最主要的特点是每一个ForkJoinWorkerThread线程都具有一个独立的任务等待队列(work queue),这个任务队列用于存储在本线程中被拆分的若干子任务。
join方法用于让当前线程阻塞,直到对应的子任务完成运行并返回执行结果。或者,如果这个子任务存在于当前线程的任务等待队列(work queue)中,则取出这个子任务进行“递归”执行。其目的是尽快得到当前子任务的运行结果,然后继续执行。
五、使用Fork/Join解决实际问题
之前所举的的例子是使用Fork/Join框架完成1-1000的整数累加。这个示例如果只是演示Fork/Join框架的使用,那还行,但这种例子和实际工作中所面对的问题还有一定差距。本篇文章我们使用Fork/Join框架解决一个实际问题,就是高效排序的问题。
1.使用归并算法解决排序问题
排序问题是我们工作中的常见问题。目前也有很多现成算法是为了解决这个问题而被发明的,例如多种插值排序算法、多种交换排序算法。而并归排序算法是目前所有排序算法中,平均时间复杂度较好(O(nlgn)),算法稳定性较好的一种排序算法。它的核心算法思路将大的问题分解成多个小问题,并将结果进行合并。

整个算法的拆分阶段,是将未排序的数字集合,从一个较大集合递归拆分成若干较小的集合,这些较小的集合要么包含最多两个元素,要么就认为不够小需要继续进行拆分。
那么对于一个集合中元素的排序问题就变成了两个问题:1、较小集合中最多两个元素的大小排序;2、如何将两个有序集合合并成一个新的有序集合。第一个问题很好解决,那么第二个问题是否会很复杂呢?实际上第二个问题也很简单,只需要将两个集合同时进行一次遍历即可完成——比较当前集合中最小的元素,将最小元素放入新的集合,它的时间复杂度为O(n):
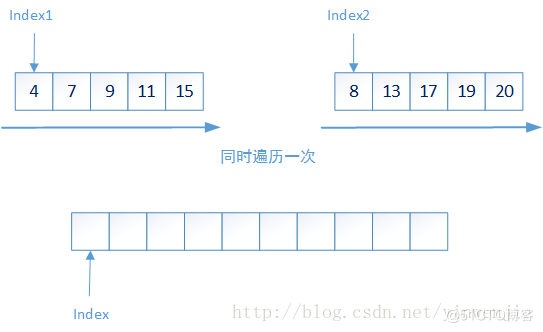
以下是归并排序算法的简单实现:
package test.thread.pool.merge;
import java.util.Arrays;
import java.util.Random;
/**
* 归并排序
* @author yinwenjie
*/
public class Merge1 {
private static int MAX = 10000;
private static int inits[] = new int[MAX];
// 这是为了生成一个数量为MAX的随机整数集合,准备计算数据
// 和算法本身并没有什么关系
static {
Random r = new Random();
for(int index = 1 ; index <= MAX ; index++) {
inits[index - 1] = r.nextInt(10000000);
}
}
public static void main(String[] args) {
long beginTime = System.currentTimeMillis();
int results[] = forkits(inits);
long endTime = System.currentTimeMillis();
// 如果参与排序的数据非常庞大,记得把这种打印方式去掉
System.out.println("耗时=" + (endTime - beginTime) + " | " + Arrays.toString(results));
}
// 拆分成较小的元素或者进行足够小的元素集合的排序
private static int[] forkits(int source[]) {
int sourceLen = source.length;
if(sourceLen > 2) {
int midIndex = sourceLen / 2;
int result1[] = forkits(Arrays.copyOf(source, midIndex));
int result2[] = forkits(Arrays.copyOfRange(source, midIndex , sourceLen));
// 将两个有序的数组,合并成一个有序的数组
int mer[] = joinInts(result1 , result2);
return mer;
}
// 否则说明集合中只有一个或者两个元素,可以进行这两个元素的比较排序了
else {
// 如果条件成立,说明数组中只有一个元素,或者是数组中的元素都已经排列好位置了
if(sourceLen == 1
|| source[0] <= source[1]) {
return source;
} else {
int targetp[] = new int[sourceLen];
targetp[0] = source[1];
targetp[1] = source[0];
return targetp;
}
}
}
/**
* 这个方法用于合并两个有序集合
* @param array1
* @param array2
*/
private static int[] joinInts(int array1[] , int array2[]) {
int destInts[] = new int[array1.length + array2.length];
int array1Len = array1.length;
int array2Len = array2.length;
int destLen = destInts.length;
// 只需要以新的集合destInts的长度为标准,遍历一次即可
for(int index = 0 , array1Index = 0 , array2Index = 0 ; index < destLen ; index++) {
int value1 = array1Index >= array1Len?Integer.MAX_VALUE:array1[array1Index];
int value2 = array2Index >= array2Len?Integer.MAX_VALUE:array2[array2Index];
// 如果条件成立,说明应该取数组array1中的值
if(value1 < value2) {
array1Index++;
destInts[index] = value1;
}
// 否则取数组array2中的值
else {
array2Index++;
destInts[index] = value2;
}
}
return destInts;
}
}
以上归并算法对1万条随机数进行排序只需要2-3毫秒,对10万条随机数进行排序只需要20毫秒左右的时间,对100万条随机数进行排序的平均时间大约为160毫秒(这还要看随机生成的待排序数组是否本身的凌乱程度)。可见归并算法本身是具有良好的性能的。使用JMX工具和操作系统自带的CPU监控器监视应用程序的执行情况,可以发现整个算法是单线程运行的,且同一时间CPU只有单个内核在作为主要的处理内核工作:
JMX中观察到的线程情况:
CPU的运作情况:
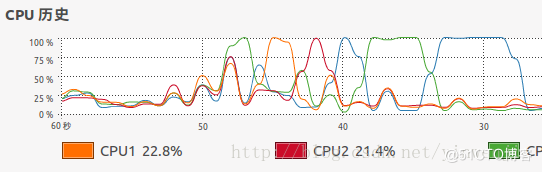
2.使用Fork/Join运行归并算法
但是随着待排序集合中数据规模继续增大,以上归并算法的代码实现就有一些力不从心了,例如以上算法对1亿条随机数集合进行排序时,耗时为27秒左右。
接着我们可以使用Fork/Join框架来优化归并算法的执行性能,将拆分后的子任务实例化成多个ForkJoinTask任务放入待执行队列,并由Fork/Join框架在多个ForkJoinWorkerThread线程间调度这些任务。如下图所示:
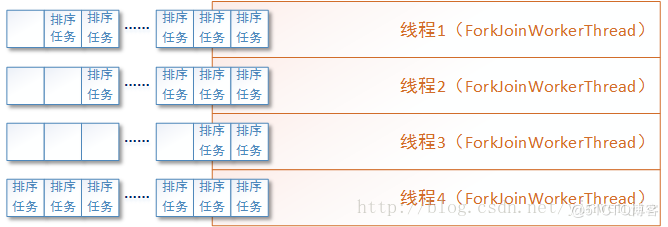
以下为使用Fork/Join框架后的归并算法代码,请注意joinInts方法中对两个有序集合合并成一个新的有序集合的代码,是没有变化的可以参见本文上一小节中的内容。所以在代码中就不再赘述了:
......
/**
* 使用Fork/Join框架的归并排序算法
* @author yinwenjie
*/
public class Merge2 {
private static int MAX = 100000000;
private static int inits[] = new int[MAX];
// 同样进行随机队列初始化,这里就不再赘述了
static {
......
}
public static void main(String[] args) throws Exception {
// 正式开始
long beginTime = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
MyTask task = new MyTask(inits);
ForkJoinTask<int[]> taskResult = pool.submit(task);
try {
taskResult.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
long endTime = System.currentTimeMillis();
System.out.println("耗时=" + (endTime - beginTime));
}
/**
* 单个排序的子任务
* @author yinwenjie
*/
static class MyTask extends RecursiveTask<int[]> {
private int source[];
public MyTask(int source[]) {
this.source = source;
}
/* (non-Javadoc)
* @see java.util.concurrent.RecursiveTask#compute()
*/
@Override
protected int[] compute() {
int sourceLen = source.length;
// 如果条件成立,说明任务中要进行排序的集合还不够小
if(sourceLen > 2) {
int midIndex = sourceLen / 2;
// 拆分成两个子任务
MyTask task1 = new MyTask(Arrays.copyOf(source, midIndex));
task1.fork();
MyTask task2 = new MyTask(Arrays.copyOfRange(source, midIndex , sourceLen));
task2.fork();
// 将两个有序的数组,合并成一个有序的数组
int result1[] = task1.join();
int result2[] = task2.join();
int mer[] = joinInts(result1 , result2);
return mer;
}
// 否则说明集合中只有一个或者两个元素,可以进行这两个元素的比较排序了
else {
// 如果条件成立,说明数组中只有一个元素,或者是数组中的元素都已经排列好位置了
if(sourceLen == 1
|| source[0] <= source[1]) {
return source;
} else {
int targetp[] = new int[sourceLen];
targetp[0] = source[1];
targetp[1] = source[0];
return targetp;
}
}
}
private int[] joinInts(int array1[] , int array2[]) {
// 和上文中出现的代码一致
}
}
}
使用Fork/Join框架优化后,同样执行1亿条随机数的排序处理时间大约在14秒左右,当然这还和待排序集合本身的凌乱程度、CPU性能等有关系。但总体上这样的方式比不使用Fork/Join框架的归并排序算法在性能上有30%左右的性能提升。以下为执行时观察到的CPU状态和线程状态:
JMX中的内存、线程状态:
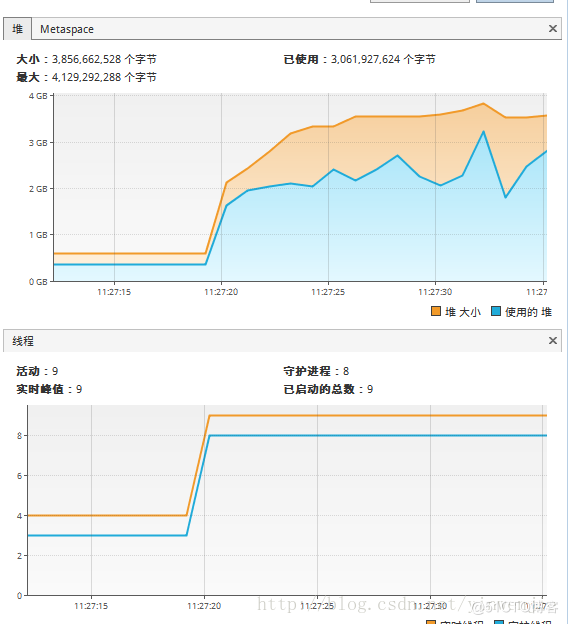
CPU使用情况:
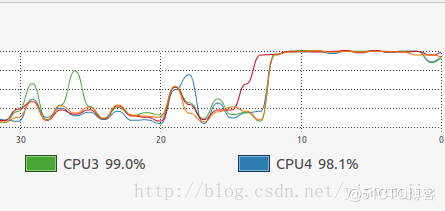
除了归并算法代码实现内部可优化的细节处,使用Fork/Join框架后,我们基本上在保证操作系统线程规模的情况下,将每一个CPU内核的运算资源同时发挥了出来。
加载全部内容