Window10下使用IDEA搭建Hadoop开发环境
mrr 人气:0前言
经过三次重装,查阅无数资料后成功完成hadoop在win10上实现伪分布式集群,以及IDEA开发环境的搭建。一步一步跟着本文操作可以避免无数天坑。
下载安装Hadoop
下载安装包
进入官网下载下载hadoop的安装包(二进制文件)http://hadoop.apache.org/releases.html
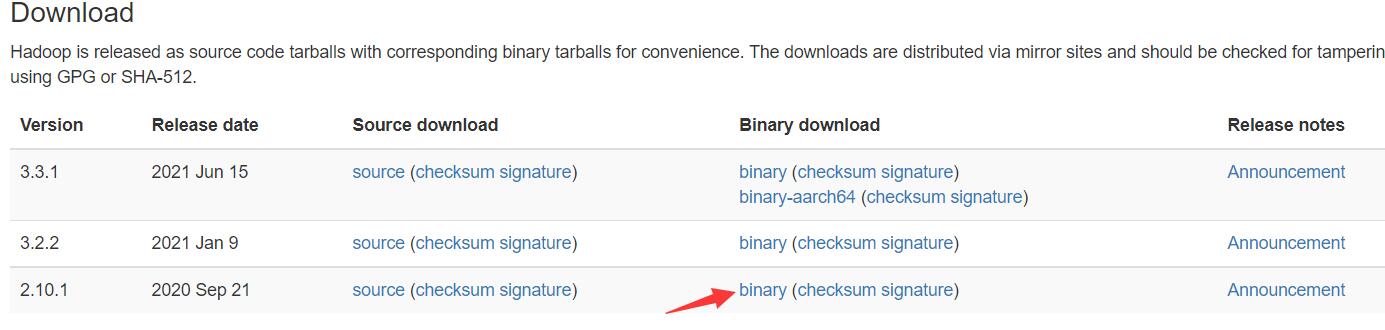

我们这里下载2.10.1版本的,如果想下载更高版本的请先去maven仓库查看是否有对应版本
解压文件
下载好的.gz文件可以直接解压。
winRAR和Bandizip都可以用来解压,但是注意必须以管理员身份打开解压软件,否则会出现解压错误
配置环境变量
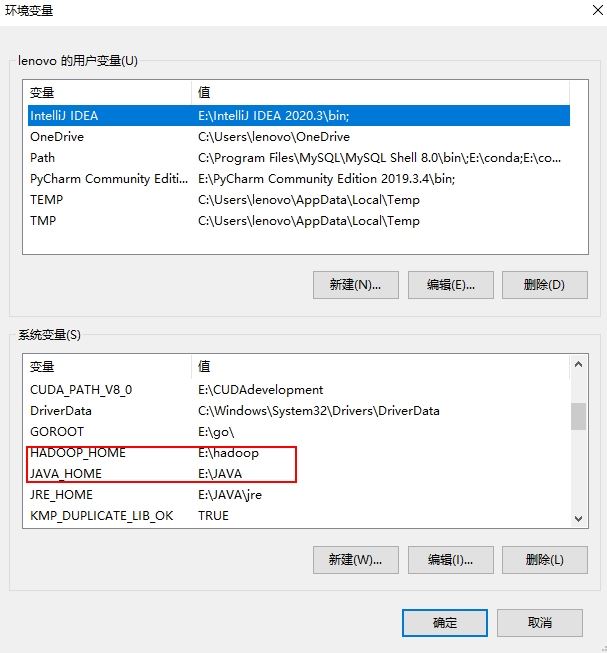
配置JAVA_HOME和HADOOP_HOME
我们在环境变量处分别设置JAVA_HOME和HADOOP_HOME
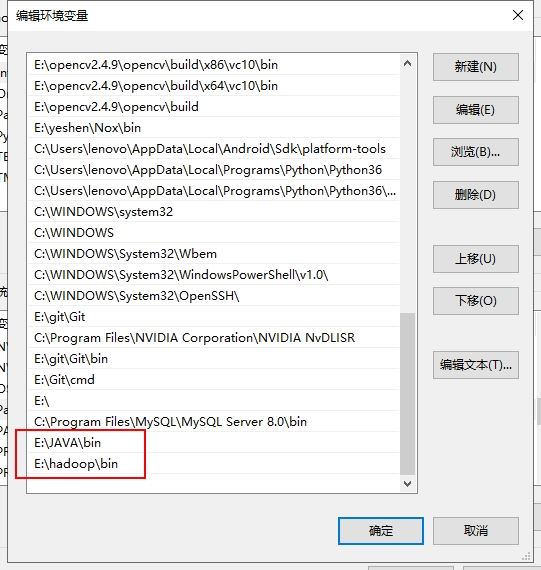
然后在Path里添加JAVA和hadoop的二进制文件夹,bin文件夹
验证环境变量配置
打开你的cmd,输入以下命令,出现我这样的输出说明配置环境变量成功:
C:\Users\lenovo>hadoop -version
HDFS配置
来到之前解压的hadoop文件夹下,打开etc/hadoop文件夹
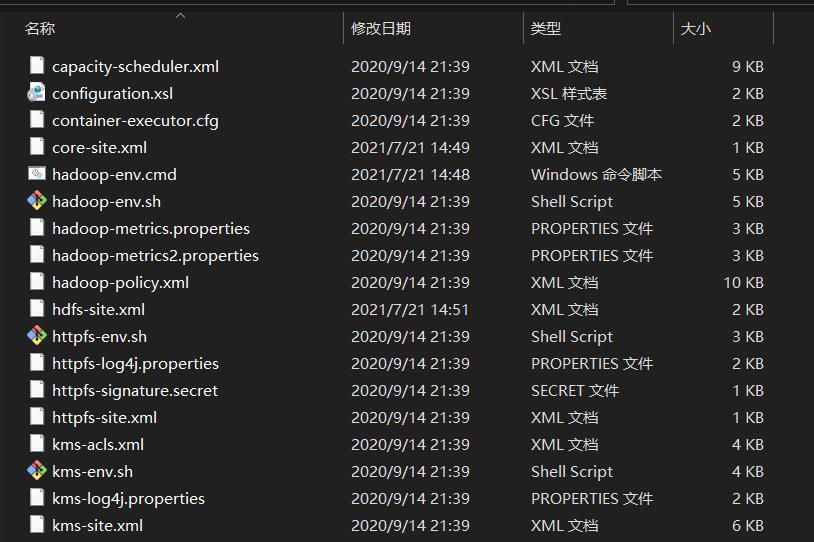
现在我们的任务就是修改这些文件当中的代码,务必修改,不然根本无法运行hadoop!!
修改 hadoop-env.cmd
将configuration处更改为:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://0.0.0.0:9000</value> </property></configuration>修改 hdfs-site.xml
将configuration处更改为如下所示,其中
file:///E:/DevTols/hadoop-2.10.1/namespace_logs
file:///E:/DevTols/hadoop-2.10.1/data
这两个文件夹一定需要是已经存在的文件夹,你可以在你的hadoop文件夹下随意创建两个文件夹,然后将下面的这两个文件夹的绝对路径替换成你的文件夹,这里我也是创建了两个新的文件夹,hadoop的下载文件夹里本身是没有的。

将configuration标签及内容替换为
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///E:/DevTols/hadoop-2.10.1/namespace_logs</value> </property> <property> <name>dfs.data.dir</name> <value>file:///E:/DevTols/hadoop-2.10.1/data</value> </property></configuration>修改 mapred-site.xml
将下方的%USERNAME%替换成你windows的用户名
用户名可以通过win键查看

<configuration> <property> <name>mapreduce.job.user.name</name> <value>%USERNAME%</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.apps.stagingDir</name> <value>/user/%USERNAME%/staging</value> </property> <property> <name>mapreduce.jobtracker.address</name> <value>local</value> </property></configuration>注意以上代码有两个地方的%USERNAME%需要替换,不要漏了!!!
修改 yarn-site.xml
<configuration> <property> <name>yarn.server.resourcemanager.address</name> <value>0.0.0.0:8020</value> </property> <property> <name>yarn.server.resourcemanager.application.expiry.interval</name> <value>60000</value> </property> <property> <name>yarn.server.nodemanager.address</name> <value>0.0.0.0:45454</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.server.nodemanager.remote-app-log-dir</name> <value>/app-logs</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/dep/logs/userlogs</value> </property> <property> <name>yarn.server.mapreduce-appmanager.attempt-listener.bindAddress</name> <value>0.0.0.0</value> </property> <property> <name>yarn.server.mapreduce-appmanager.client-service.bindAddress</name> <value>0.0.0.0</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>-1</value> </property> <property> <name>yarn.application.classpath</name> <value>%HADOOP_CONF_DIR%,%HADOOP_COMMON_HOME%/share/hadoop/common/*,%HADOOP_COMMON_HOME%/share/hadoop/common/lib/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*</value> </property></configuration>初始化环境变量
在windows下的cmd,输入cmd的命令,用于初始化环境变量。
%HADOOP_HOME%\etc\hadoop\hadoop-env.cmd格式化文件系统
这个命令在整个hadoop的配置环境和之后的使用当中务必仅使用一次!
将如下的命令输入到cmd当中进行格式化:
hadoop namenode -format会弹出一大堆指令,只要看到其中有如下提示,就说明格式化成功
INFO common.Storage: Storage directory E:\DevTols\hadoop-2.10.1\namespace_logs has been successfully formatted.向hadoop文件当中注入winutills文件
由于windows下想要开启集群,会有一定的bug,因此我们去网站:https://github.com/steveloughran/winutils
下载对应版本的winutils.exe文件。打开这个Github仓库后如下所示:
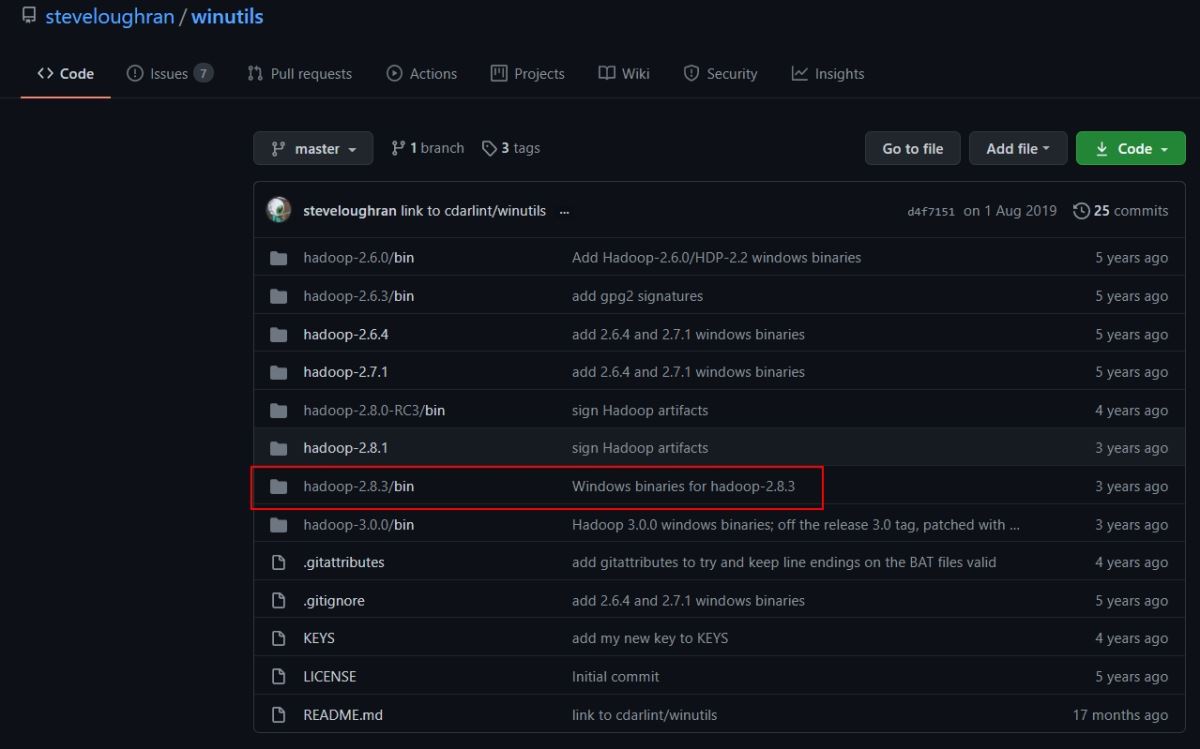
我们打开hadoop2.8.3/bin,选择其中的winutils.exe文件进行下载,然后将下载的这个文件放入到本地的hadoop/bin文件当中。不然的话,你打开一会儿你的伪分布式集群,马上hadoop就会自动关闭,缺少这两个文件的话。
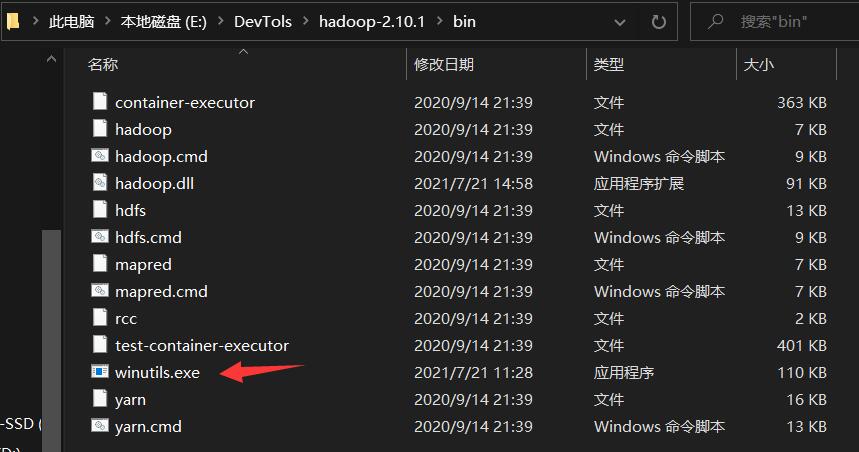
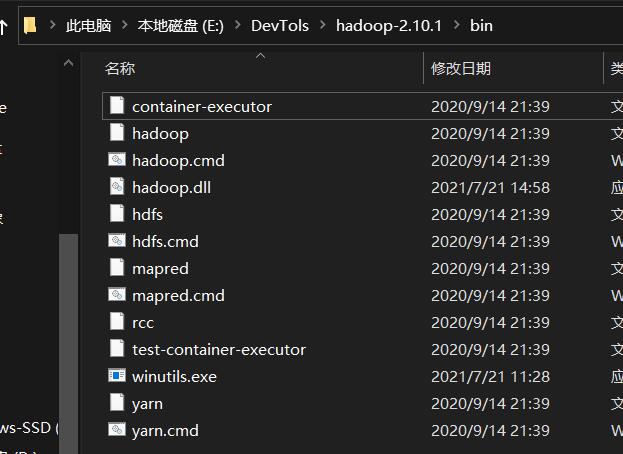
向hadoop文件当中添加hadoop.dll文件
hadoop.dll文件是启动集群时必须的,如果在安装过程中悲催地发现/bin目录下没有该文件(比如博主),就需要去网上自学下载该文件。
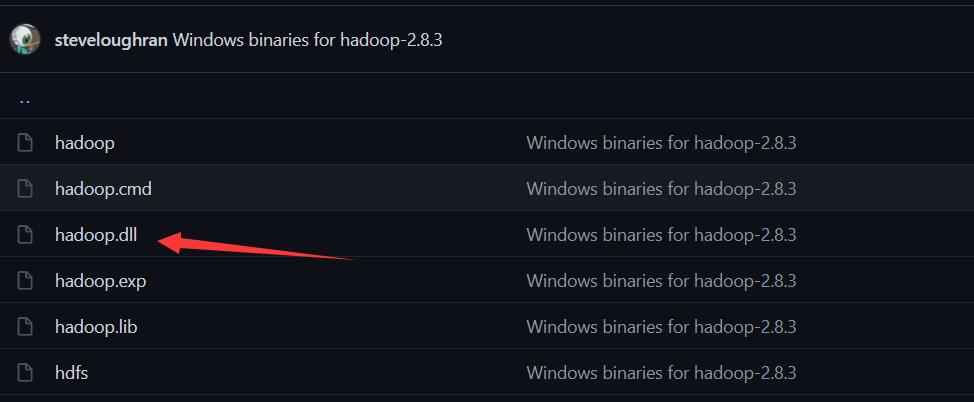
进入网页https://github.com/4ttty/winutils,
根据箭头所指步骤下载hadoop.dll文件
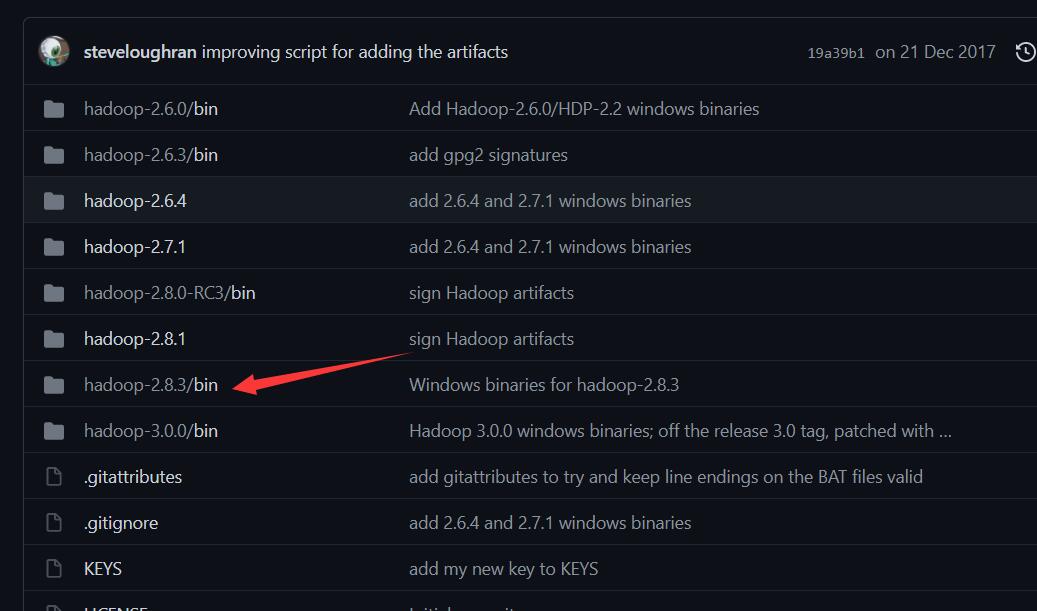
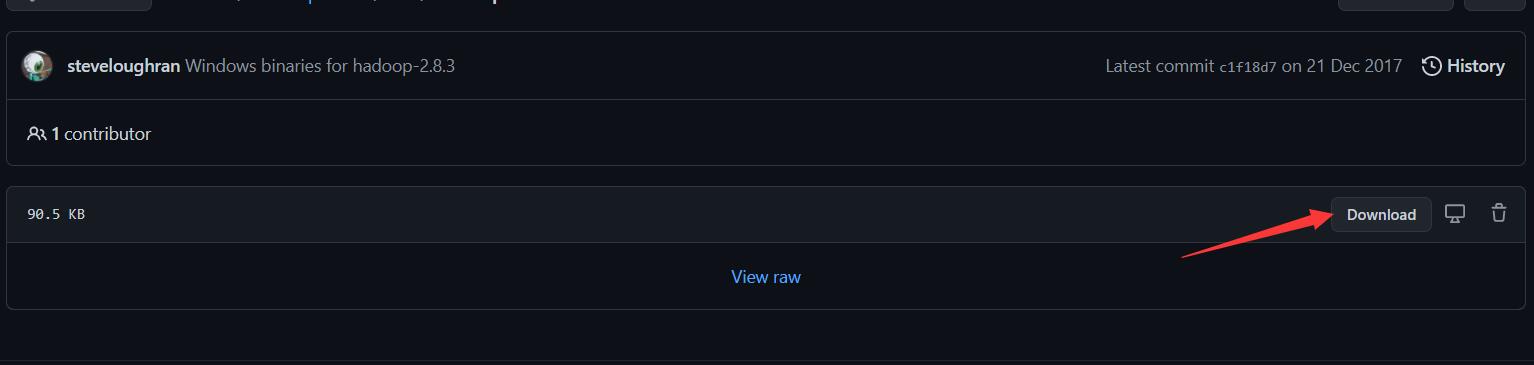
下载完成后,把文件添加到/bin目录
开启hadoop集群
在cmd当中输入
%HADOOP_HOME%/sbin/start-all.cmd这样就会跳出来很多黑色的窗口,如下所示:
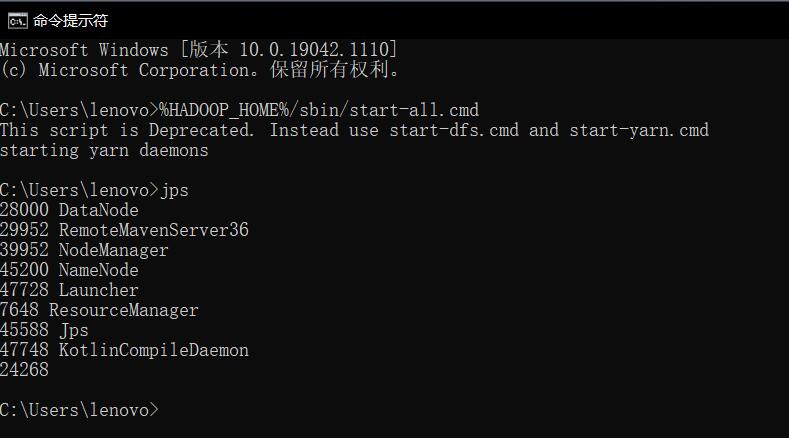
然后可以使用JPS工具查看目前开启的node有哪些,如果出现namenode,datanode的话说明集群基本上就成功了。如下所示:
打开本地浏览器进行验证
我们在浏览器输入localhost:50070,如果能够打开这样的网页,说明hadoop已经成功开启:

IDEA 配置
历经千辛万苦我们总算安装完Hadoop了,下面在IDEA上用maven配置hadoop
创建MAVEN项目工程
打开IDEA之后,里面的参数和项目工程名称随便写,等待工程创建完毕即可。然后我们编辑pom.xml文件
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atguigu</groupId> <artifactId>hdfs1205</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.10.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.10.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.10.1</version> </dependency> </dependencies></project>点击右下方的auto-import,自动安装jar包。完成后左侧External Libraries可以看到添加了很多个jar包,如下图

这样就说明我们导入maven仓库成功了。
编写log4j.proporties配置文件
在src/main/resources目录下创建log4j.proporties文件,编写如下代码
log4j.rootLogger=debug, stdout, Rlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayout# Pattern to output the caller's file name and line number.log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppenderlog4j.appender.R.File=example.loglog4j.appender.R.MaxFileSize=100KB# Keep one backup filelog4j.appender.R.MaxBackupIndex=5log4j.appender.R.layout=org.apache.log4j.PatternLayoutlog4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n编写Java文件
终于到最后一步了,编写java文件并执行
别忘了先hadoop伪分布式集群!!!
cmd中编写%HADOOP_HOME%/sbin/start-all.cmd
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileStatus;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import java.net.URI;public class Test { public static void main(String[] args) throws Exception { FileSystem fs = FileSystem.get(new URI("hdfs://127.0.0.1:9000"), new Configuration()); FileStatus[] files = fs.listStatus(new Path("/")); for (FileStatus f : files) { System.out.println(f); } System.out.println("Compile Over"); }}这段代码的含义是遍历hadoop文件系统(HDFS)下的root下所有文件的状态,并输出
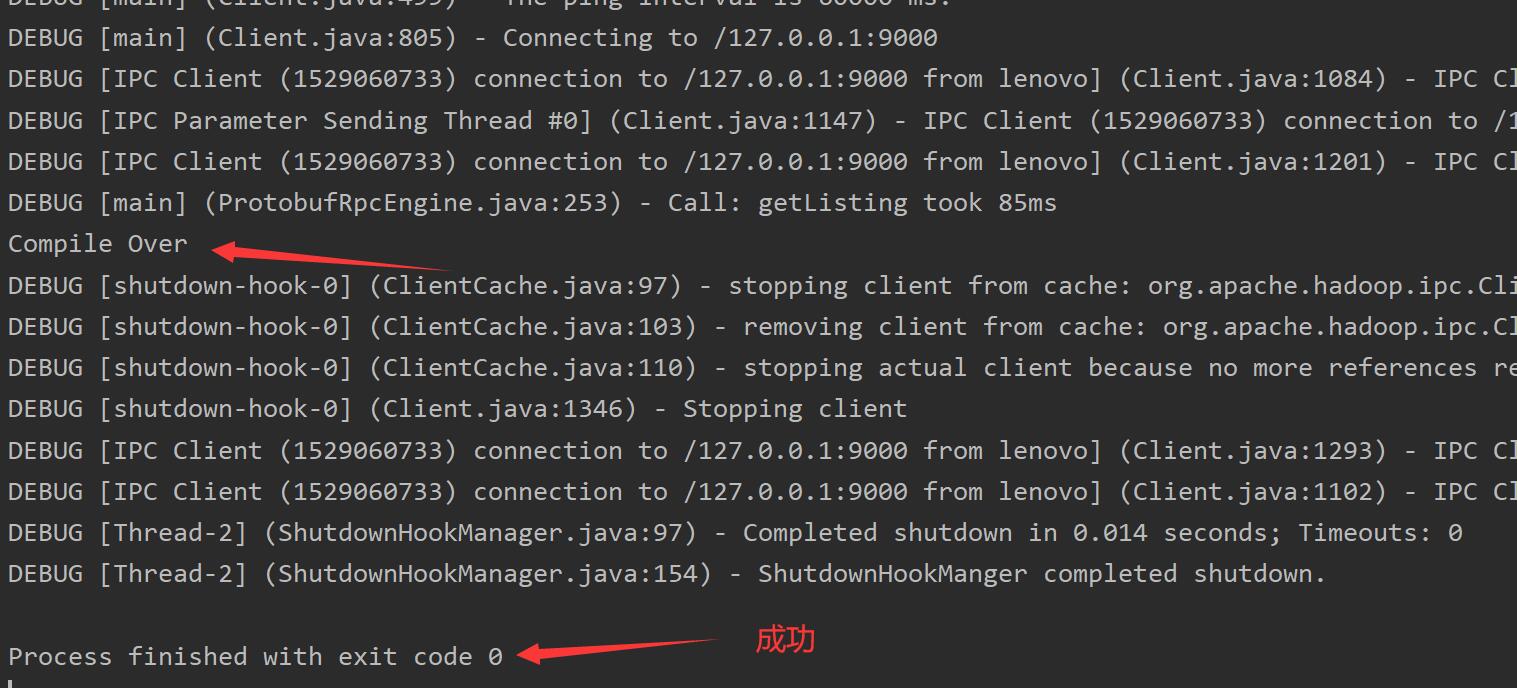
完成以后在cmd输入%HADOOP_HOME%/sbin/start-all.cmd关闭伪集群
为了方便可以配置%HADOOP_HOME%/sbin/start-all.cmd和%HADOOP_HOME%/sbin/start-all.cmd
的环境变量,这里不再赘述,留给读者发挥。
到这里Window10下使用IDEA搭建开发环境就完成了,撒花!!!
加载全部内容