Python获取公众号文章 使用Python获取公众号下所有的文章
一天一篇Python库 人气:4导出公众号所有文章
随着互联网的不断发展,网络上兴起了很多的自媒体平台。不用我说,相信大家也能知道当下非常流行的平台都有哪些。
可以说凡是比较知名的自媒体,都有自己的公众号。但是平台的创新与出现可谓层出不穷,如果需要入住平台,肯定需要获取原平台的历史资源。
比如说微信公众号,我们就需要获取微信公众号的文章,将其导出后,入住其他的平台,那么如何获取自己公众号下的所有文章呢?
开发者ID与开发者密码
其实,公众号给我们开发中提供了非常友好的接口,并不需要我们一个一个去爬,就可以获取文章的所有链接。

如上图所示,我们需要进入公众号主页,然后通过设置与开发-基本配置,找到开发者ID与开发者密码。
因为微信给我们提供了接口专门用于我们获取公众号的文章,具体的接口网址,如下面代码所示:
https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=APPID&secret=APPSECRET
这里的APPID就是开发中ID,APPSECRET就是开发者密码,如下图所示进行获取。
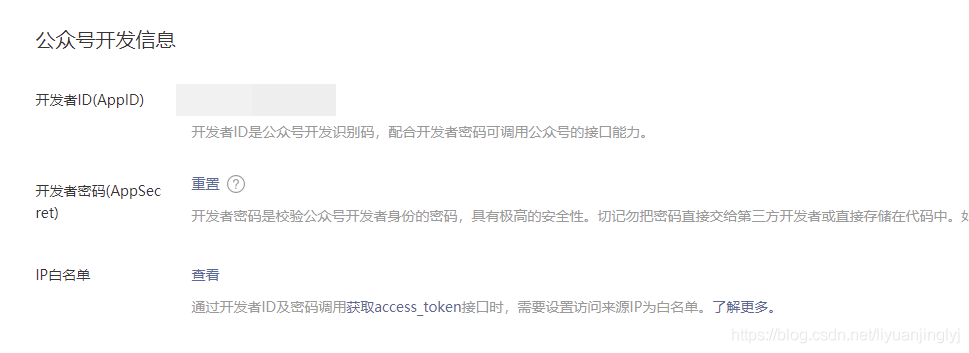
不过,这里有一个IP白名需要注意,为了公众号文章的安全,必须设置IP地址才能获取。如果后面的代码并没有在IP下运行,那么肯定会报错。
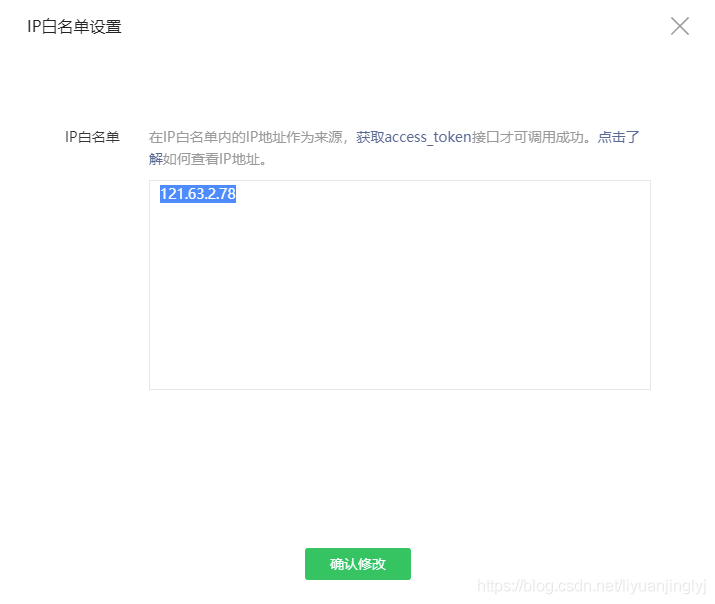
如上图所示,IP白名单是直接设置你的IP地址,设置完成之后点击修改,弹出二维码后用微信扫描即可。
https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=
这样还不行,因为该网址接口只是获取access_token,也就是访问公众号的令牌,而获取公众号文章的链接是上面这个。
获取Json格式的公众号文章信息
既然已经基本了解了原理,下面我们来通过实战获取所有的公众号标题,链接,描述以及文章的展示图。示例如下:
import requests
import json
import csv
def getGZHJson(appid, secret):
path = " https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential"
url = path + "&appid=" + appid + "&secret=" + secret
result = requests.get(url)
token = json.loads(result.text)
access_token = token['access_token']
data = {
"type": "news",
"offset": 0,
"count": 1,
}
headers = {
'content-type': "application/json",
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=' + access_token
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
count = int(result['total_count'])
gzh_dict = {"news_item": []}
for i in range(0, count):
data['offset'] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result['item'][0]['content']['news_item']:
temp_dict = {}
temp_dict['title'] = item["title"]
temp_dict['digest'] = item["digest"]
temp_dict['url'] = item["url"]
temp_dict['thumb_url'] = item["thumb_url"]
print(temp_dict)
gzh_dict['news_item'].append(temp_dict)
return json.dumps(gzh_dict)
getGZHJson('开发者ID', '开发者密码')
这里,我们先来看一下result的原始文本数据,具体如下所示:

原始的JSON数据中,有一个非常重要的数据也就是total_count,也就是公众号成立以来,推送的次数。
但是需要注意,公众号可以单次推送一篇,或者单次推送2,3,4篇,并不一直都是一模一样。
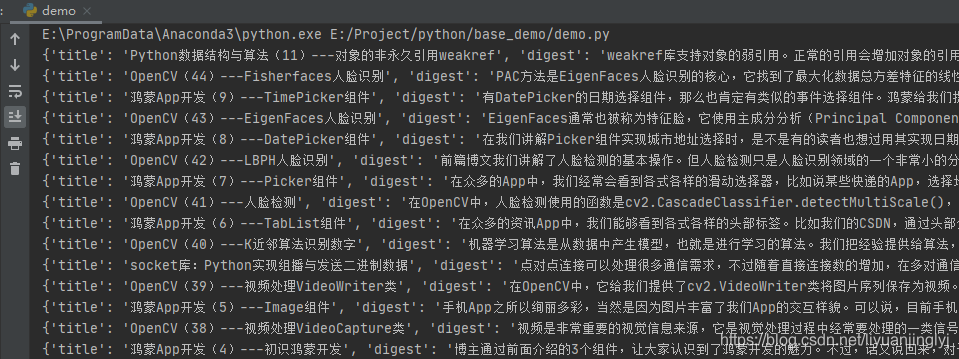
而获取哪次推送的数据,你可以通过offset逆向溯源,至于每次是多少篇,则需要通过返回的Json数据news_item有多少个决定。如下图所示:

所以,我们还有在里面加上一次遍历,第1层遍历的是微信公众号推送的哪天数据,第2层遍历,遍历的是当天发送的篇数。运行之后,效果如下:
| 参数 | 含义 |
|---|---|
| title | 文章标题 |
| digest | 文章描述 |
| url | 文章链接 |
| thumb_url | 文章展示图 |
保存数据到CSV文件
当然,我们获取数据并不是为了在控制台去打印,而是为了导出数据。所以,我们将上面的数据打包到CSV文件中保存起来。
示例如下:
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
print(result.encoding)
result = json.loads(result.text)
count = int(result['total_count'])
#替换下面的代码
ulist = ["_id", "title", 'digest', 'url', 'thumb_url']
# 保存数据到csv文件
new_item_csv = 'week'
with open('{}.csv'.format(new_item_csv), 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f, dialect='excel')
writer.writerow(ulist)
for i in range(0, count):
data['offset'] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result['item'][0]['content']['news_item']:
writer.writerow([count_id, item["title"], item["digest"], item["url"], item["thumb_url"]])
count_id += 1
这里,只需要改count = int(result[‘total_count'])代码下面的所有数据即可。上面的代码保持不变。
需要额外注意的是,之所以设置result.encoding = result.apparent_encoding,是因为返回数据的编码事先我们并不知道,这样做能保证任何编码都能有效的解析。
运行之后,如下图所示,所有的公众号文章的基本详情就全部获取到了。
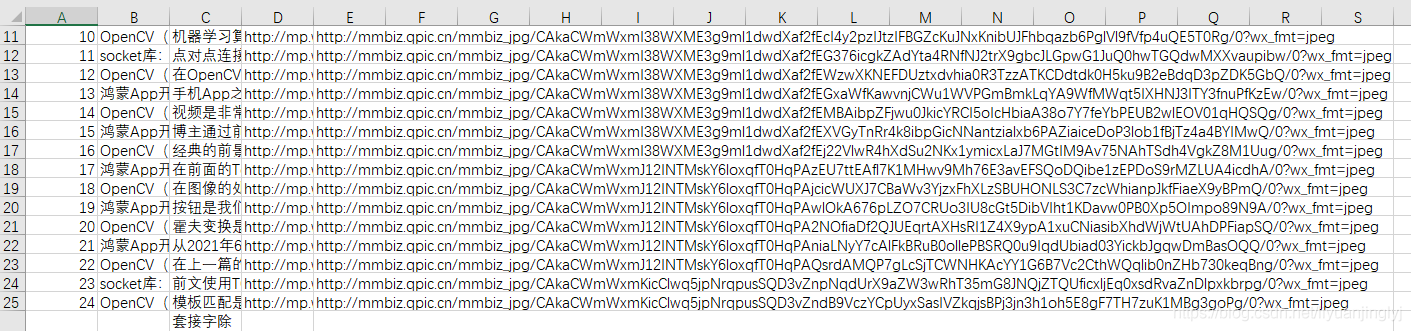
加载全部内容