Java byte & 0xff作用 Java中的byte & 0xff到底有什么作用?
小楼夜听雨QAQ 人气:0如果写过通信类的代码,比如socket编程,应该对这个问题不陌生。
先说结论
byte & 0xff 是将byte从(-128 至 127)转化成 int(转化后的数值范围: 0 至 255)。
其实就是1个byte有两种表示方法,我们既可以用-128 - 127这段范围来表示一个字节,也可以用 0 - 255这个范围的数来表示一个字节。
看一个demo
用Java中的InetAddress类来获取我当前的ip
public class InetAddressTest {
public static void main(String[] args) throws UnknownHostException {
InetAddress localHost = InetAddress.getLocalHost();
byte[] address = localHost.getAddress();
for (byte b : address) {
System.out.print(b + " ");
}
}
}
输出结果
-64 -88 2 119
本机ip

好像不太一样,我们ip地址只用 0 - 255来表示,不会出现负数。
所以再换一种写法,将取出来的字节 & 0xff
public class InetAddressTest {
public static void main(String[] args) throws UnknownHostException {
InetAddress localHost = InetAddress.getLocalHost();
byte[] address = localHost.getAddress();
for (byte b : address) {
System.out.print( ( b & 0xff ) + " ");
}
}
}
结果
192 168 2 119
Process finished with exit code 0
果然就是我们想要的结果
为什么需要转换
因为Java中的byte是有符号的,他的范围只能是 -128 - 127。
我们在使用tcp等协议的时候,首先要把传输的消息转化成字节流,然后再传输,在编程语言中字节流通常用十进制的byte数组来表示。
假如我们就想用 0-255来表示一个字节,不想用负数,该怎么办呢?
可惜Java中没有 无符号字节(unsigned byte), 我们只能用 int 来存储0-255。
而int的范围是(-2^31 ~ 2^31-1),只用了256个,剩下的空间都被浪费了,得不偿失啊。
所以我们存储的时候、传输的时候可以用byte,但是使用的时候就需要做一个转换了,那为什么0xff就可以得到无符号byte呢。
& 0xff的作用
作为一个十六进制数,0xff在Java中是用什么类型存储的呢?
应该显而易见吧,0xff是整型。
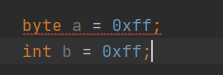
假设我现在要转化 字节 -1
-1的原码、反码、补码分别如下:
原码 1 0 0 0 0 0 0 1 反码 0 1 1 1 1 1 1 0 补码 0 1 1 1 1 1 1 1
现在和 0xff做运算, ff 就是(1111 11111),而因为他是整型,占4个字节,32为,所以0Xff的前面还有24个0。
用 -1 的补码进行计算
-1 0 1 1 1 1 1 1 1 0xff 000000000 000000000 000000000 1 1 1 1 1 1 1 1 = 000000000 000000000 000000000 0 1 1 1 1 1 1 1 = 255
其实在Java中,”任何数 & 0Xff等于那个数本身“ 这句话就显得不那么正确了
”任意整型 & 0xff = 本身“ 是没有问题的
但是字节 & 0xff 就被拖到了另一个次元,从byte进化成了int。
关于byte[ ] & 0xFF的问题
最近在写有关SHA256加密解密的问题,发现有一段代码是这样的,处于好奇理解了一下。
private static String byte2Hex(byte[] bytes){
StringBuffer stringBuffer = new StringBuffer();
String temp = null;
for (int i=0;i<bytes.length;i++){
temp = Integer.toHexString(bytes[i] & 0xFF);
if (temp.length()==1){
//1得到一位的进行补0操作
stringBuffer.append("0");
}
stringBuffer.append(temp);
}
return stringBuffer.toString();
}
Integer类中toHexString方法的参数是int类型,为什么byte[ ] & 0xFF可以表示int类型呢?
byte[i]是8位二进制,0xFF转化为8位二进制为11111111,& 之后的结果还是本身啊,这是怎么回事?
我们都知道计算机内的存储都是利用二进制的补码进行存储的。
复习一下,原码反码补码这三个概念
对于一个字节的最高位,计算机中是有规定的,正数的最高位为0,负数的最高位为1。
对于正数(00000001)原码来说,首位表示符号位,反码 补码都是本身
对于负数(100000001)原码来说,反码是对原码除了符号位之外作取反运算即(111111110),补码是对反码作+1运算即(111111111)
下面写段代码测试下
public static void main(String[] args) {
byte[] a=new byte[10];
a[0]=-127;
System.out.println("a[0]:"+a[0]);
int b=a[0] & 0xFF;
System.out.println("b:"+b);
}
得到的结果为:
a[0]:-127
b:129
现在针对这个结果进行分析:
byte类型的a[0]的值为-127,在计算机中存储的补码为:10000001,这个补码是8位的,而int类型是32位的,所以a[0]作为int类型来输出的时候jvm给做了个补位便成了 111111111111111111111111 10000001(-127),虽然补码转换了,但是这两个补码表示的十进制数字是相同的。
为了保证二进制数据的一致性,当byte要转化为int的时候,高的24位必然会补1,这样,其二进制补码其实已经不一致了,如果二进制被当作byte和int来解读,其10进制的值必然是不同的,因为符号位位置已经发生了变化,而&0xFF可以将高的24位置为0,低8位保持原样。
int b = a[0]&0xff; a[0]&0xff=1111111111111111111111111 10000001&11111111=000000000000000000000000 10000001 ,这个值就是129
所以最后显示的b的值为129
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容