JDK Vector与HashSet JDK源码之Vector与HashSet解析
兴趣使然的草帽路飞 人气:0想了解JDK源码之Vector与HashSet解析的相关内容吗,兴趣使然的草帽路飞在本文为您仔细讲解JDK Vector与HashSet的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:JDK,Vector解析,JDK,HashSet解析,下面大家一起来学习吧。
Vector简介
ArrayList 和 Vector 其实大同小异,基本结构都差不多,但是一些细节上有区别:比如线程安全与否,扩容的大小等,Vector的线程安全通过在方法上直接加synchronized实现。扩容默认扩大为原来的2倍。
继承体系

从图中我们可以看出:Vector继承了AbstractList,实现了List,RandomAccess,Cloneable,Serializable接口,因此Vector支持快速随机访问,可以被克隆,支持序列化。
Vector的成员变量(属性)
// Object类型的数组 // 注意:访问修饰符有所不同,Vector用protected修饰,而ArrayList用private修饰。 // JavaSe中:private变量只能被当前类的方法访问,而protected可以被同一包中的所有类和其他包的子类访问 protected Object[] elementData; // 动态数组的实际有效大小,即数组中存储的元素个数 protected int elementCount; // 动态数组的增长系数:若开始事先没有指定,则默认是增加一倍的大小 protected int capacityIncrement; // 序列版本号 private static final long serialVersionUID = -2767605614048989439L;
Vector的构造函数
Vector的构造函数有四个:
// 默认空参构造函数
public Vector() {
// 调用指定初始容量的构造函数,初始容量为10
this(10);
}
// 可以指定初始容量的构造函数
public Vector(int initialCapacity) {
// 调用指定初始容量和增长系数的构造函数,增长系数设置为0
this(initialCapacity, 0);
}
// 可以指定初始容量和增长系数的构造函数
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
// 根据初始容量创建一个Object类型的数组
this.elementData = new Object[initialCapacity];
// 给增长系数赋值
this.capacityIncrement = capacityIncrement;
}
// 参数为集合类型的构造函数
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
// 将参数集合c 中的数据拷贝到elementData
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
Vector成员方法
get方法
// 获得指定下标的元素数据
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
set方法
// 修改指定下标的元素数据
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
remove方法
// 删除某个元素数据
public boolean remove(Object o) {
return removeElement(o);
}
//
public synchronized boolean removeElement(Object obj) {
modCount++;
// 找到指定元素的下标
int i = indexOf(obj);
if (i >= 0) {
// 根据下标删除元素
removeElementAt(i);
return true;
}
return false;
}
// 根据下标删除元素
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
// index之后的有效元素数量
int j = elementCount - index - 1;
if (j > 0) {
// 旧数组替换新数组
System.arraycopy(elementData, index + 1, elementData, index, j);
}
// 有效元素数量--
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
add方法
// 在数组末尾添加指定元素
public synchronized boolean add(E e) {
modCount++;
// 判断是否需要扩容
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
其他方法
// 将数组Vector中的全部元素都拷贝到数组anArray中去,调用本地方法arraycopy
public synchronized void copyInto(Object[] anArray) {
System.arraycopy(elementData, 0, anArray, 0, elementCount);
}
public synchronized void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (elementCount < oldCapacity) {
elementData = Arrays.copyOf(elementData, elementCount);
}
}
// 设置Vector数组的大小
public synchronized void setSize(int newSize) {
// 修改次数++
modCount++;
// 判断设置的数组大小是否大于Vector中有存储的效元素的个数
// 若 newSize > Vector中有存储的效元素的个数,则调整Vector的大小
if (newSize > elementCount) {
// 调用判断是否扩容的方法,如果需要扩容则该方法内部调用扩容方法grow()
ensureCapacityHelper(newSize);
} else {
// 如果上述判断不成立,则将newSize位置之后开始的元素都设置为null
for (int i = newSize ; i < elementCount ; i++) {
elementData[i] = null;
}
}
// 更新有效元素个数
elementCount = newSize;
}
// 获取Vector的当前容量
public synchronized int capacity() {
return elementData.length;
}
// 获取Vector里面的有效元素个数
public synchronized int size() {
return elementCount;
}
// 判断Vecotor中是否包含元素 o
public boolean contains(Object o) {
return indexOf(o, 0) >= 0;
}
// 获取Vector数组中第一次出现对象o的下标,如果不存在,那么返回-1
public int indexOf(Object o) {
return indexOf(o, 0);
}
// 返回从index出开始第一次出现对象o的下标,如果不存在,那么返回-1
public synchronized int indexOf(Object o, int index) {
if (o == null) {
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
......
Vector的扩容方法
// 确定数组当前的容量大小
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity > 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
// 如果:当前容量 > 当前数组长度,就调用grow(minCapacity)方法进行扩容
// 由于该方法是在ensureCapacity()中被调用的,而ensureCapacity()方法中已经加上了synchronized锁,所以
// 该方法不需要再加锁
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 最大上限的数组容量大小
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE
// Vector集合中的核心扩容方法
private void grow(int minCapacity) {
// overflow-conscious code
// 获取旧数组的容量
int oldCapacity = elementData.length;
// 得到扩容后(如果需要扩容的话)的新数组容量
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
// 如果新容量 < 数组实际所需容量,则令newCapacity = minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果当前所需容量 > MAX_ARRAY_SIZE,则新容量设为 Integer.MAX_VALUE,否则设为 MAX_ARRAY_SIZE
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 最大容量
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
完整源码
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
private static final long serialVersionUID = -2767605614048989439L;
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
public synchronized void copyInto(Object[] anArray) {
System.arraycopy(elementData, 0, anArray, 0, elementCount);
}
public synchronized void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (elementCount < oldCapacity) {
elementData = Arrays.copyOf(elementData, elementCount);
}
}
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity > 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
public synchronized void setSize(int newSize) {
modCount++;
if (newSize > elementCount) {
ensureCapacityHelper(newSize);
} else {
for (int i = newSize ; i < elementCount ; i++) {
elementData[i] = null;
}
}
elementCount = newSize;
}
public synchronized int capacity() {
return elementData.length;
}
public synchronized int size() {
return elementCount;
}
public synchronized boolean isEmpty() {
return elementCount == 0;
}
public Enumeration<E> elements() {
return new Enumeration<E>() {
int count = 0;
public boolean hasMoreElements() {
return count < elementCount;
}
public E nextElement() {
synchronized (Vector.this) {
if (count < elementCount) {
return elementData(count++);
}
}
throw new NoSuchElementException("Vector Enumeration");
}
};
}
public boolean contains(Object o) {
return indexOf(o, 0) >= 0;
}
public int indexOf(Object o) {
return indexOf(o, 0);
}
public synchronized int indexOf(Object o, int index) {
if (o == null) {
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public synchronized int lastIndexOf(Object o) {
return lastIndexOf(o, elementCount-1);
}
public synchronized int lastIndexOf(Object o, int index) {
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
if (o == null) {
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}
public synchronized E firstElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(0);
}
public synchronized E lastElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(elementCount - 1);
}
public synchronized void setElementAt(E obj, int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
elementData[index] = obj;
}
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
public synchronized void removeAllElements() {
modCount++;
// Let gc do its work
for (int i = 0; i < elementCount; i++)
elementData[i] = null;
elementCount = 0;
}
public synchronized Object clone() {
try {
@SuppressWarnings("unchecked")
Vector<E> v = (Vector<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, elementCount);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
public synchronized Object[] toArray() {
return Arrays.copyOf(elementData, elementCount);
}
@SuppressWarnings("unchecked")
public synchronized <T> T[] toArray(T[] a) {
if (a.length < elementCount)
return (T[]) Arrays.copyOf(elementData, elementCount, a.getClass());
System.arraycopy(elementData, 0, a, 0, elementCount);
if (a.length > elementCount)
a[elementCount] = null;
return a;
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public boolean remove(Object o) {
return removeElement(o);
}
public void add(int index, E element) {
insertElementAt(element, index);
}
public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--elementCount] = null; // Let gc do its work
return oldValue;
}
public void clear() {
removeAllElements();
}
// Bulk Operations
public synchronized boolean containsAll(Collection<?> c) {
return super.containsAll(c);
}
public synchronized boolean addAll(Collection<? extends E> c) {
modCount++;
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityHelper(elementCount + numNew);
System.arraycopy(a, 0, elementData, elementCount, numNew);
elementCount += numNew;
return numNew != 0;
}
public synchronized boolean removeAll(Collection<?> c) {
return super.removeAll(c);
}
public synchronized boolean retainAll(Collection<?> c) {
return super.retainAll(c);
}
public synchronized boolean addAll(int index, Collection<? extends E> c) {
modCount++;
if (index < 0 || index > elementCount)
throw new ArrayIndexOutOfBoundsException(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityHelper(elementCount + numNew);
int numMoved = elementCount - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
elementCount += numNew;
return numNew != 0;
}
public synchronized boolean equals(Object o) {
return super.equals(o);
}
public synchronized int hashCode() {
return super.hashCode();
}
public synchronized String toString() {
return super.toString();
}
public synchronized List<E> subList(int fromIndex, int toIndex) {
return Collections.synchronizedList(super.subList(fromIndex, toIndex),
this);
}
protected synchronized void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = elementCount - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// Let gc do its work
int newElementCount = elementCount - (toIndex-fromIndex);
while (elementCount != newElementCount)
elementData[--elementCount] = null;
}
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField gfields = in.readFields();
int count = gfields.get("elementCount", 0);
Object[] data = (Object[])gfields.get("elementData", null);
if (count < 0 || data == null || count > data.length) {
throw new StreamCorruptedException("Inconsistent vector internals");
}
elementCount = count;
elementData = data.clone();
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
final java.io.ObjectOutputStream.PutField fields = s.putFields();
final Object[] data;
synchronized (this) {
fields.put("capacityIncrement", capacityIncrement);
fields.put("elementCount", elementCount);
data = elementData.clone();
}
fields.put("elementData", data);
s.writeFields();
}
public synchronized ListIterator<E> listIterator(int index) {
if (index < 0 || index > elementCount)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
public synchronized ListIterator<E> listIterator() {
return new ListItr(0);
}
public synchronized Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
// Racy but within spec, since modifications are checked
// within or after synchronization in next/previous
return cursor != elementCount;
}
public E next() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor;
if (i >= elementCount)
throw new NoSuchElementException();
cursor = i + 1;
return elementData(lastRet = i);
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
synchronized (Vector.this) {
checkForComodification();
Vector.this.remove(lastRet);
expectedModCount = modCount;
}
cursor = lastRet;
lastRet = -1;
}
@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
synchronized (Vector.this) {
final int size = elementCount;
int i = cursor;
if (i >= size) {
return;
}
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) Vector.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
action.accept(elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
/**
* An optimized version of AbstractList.ListItr
*/
final class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
public E previous() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
cursor = i;
return elementData(lastRet = i);
}
}
public void set(E e) {
if (lastRet == -1)
throw new IllegalStateException();
synchronized (Vector.this) {
checkForComodification();
Vector.this.set(lastRet, e);
}
}
public void add(E e) {
int i = cursor;
synchronized (Vector.this) {
checkForComodification();
Vector.this.add(i, e);
expectedModCount = modCount;
}
cursor = i + 1;
lastRet = -1;
}
}
@Override
public synchronized void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int elementCount = this.elementCount;
for (int i=0; modCount == expectedModCount && i < elementCount; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public synchronized boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final int size = elementCount;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
elementCount = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}
@Override
@SuppressWarnings("unchecked")
public synchronized void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = elementCount;
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
@SuppressWarnings("unchecked")
@Override
public synchronized void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, elementCount, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
@Override
public Spliterator<E> spliterator() {
return new VectorSpliterator<>(this, null, 0, -1, 0);
}
/** Similar to ArrayList Spliterator */
static final class VectorSpliterator<E> implements Spliterator<E> {
private final Vector<E> list;
private Object[] array;
private int index; // current index, modified on advance/split
private int fence; // -1 until used; then one past last index
private int expectedModCount; // initialized when fence set
/** Create new spliterator covering the given range */
VectorSpliterator(Vector<E> list, Object[] array, int origin, int fence,
int expectedModCount) {
this.list = list;
this.array = array;
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
private int getFence() { // initialize on first use
int hi;
if ((hi = fence) < 0) {
synchronized(list) {
array = list.elementData;
expectedModCount = list.modCount;
hi = fence = list.elementCount;
}
}
return hi;
}
public Spliterator<E> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null :
new VectorSpliterator<E>(list, array, lo, index = mid,
expectedModCount);
}
@SuppressWarnings("unchecked")
public boolean tryAdvance(Consumer<? super E> action) {
int i;
if (action == null)
throw new NullPointerException();
if (getFence() > (i = index)) {
index = i + 1;
action.accept((E)array[i]);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> action) {
int i, hi; // hoist accesses and checks from loop
Vector<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null) {
if ((hi = fence) < 0) {
synchronized(lst) {
expectedModCount = lst.modCount;
a = array = lst.elementData;
hi = fence = lst.elementCount;
}
}
else
a = array;
if (a != null && (i = index) >= 0 && (index = hi) <= a.length) {
while (i < hi)
action.accept((E) a[i++]);
if (lst.modCount == expectedModCount)
return;
}
}
throw new ConcurrentModificationException();
}
public long estimateSize() {
return (long) (getFence() - index);
}
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
}
HashSet简介
HashSet的特点
- 无序性(存储元素无序)
- 唯一性(允许使用null)
- 本质上,HashSet底层是通过HashMap来保证唯一性
- HashSet没有提供get()方法,同HashMap一样,因为Set内部是无序的,所以只能通过迭代的方式获得
HashSet的继承体系
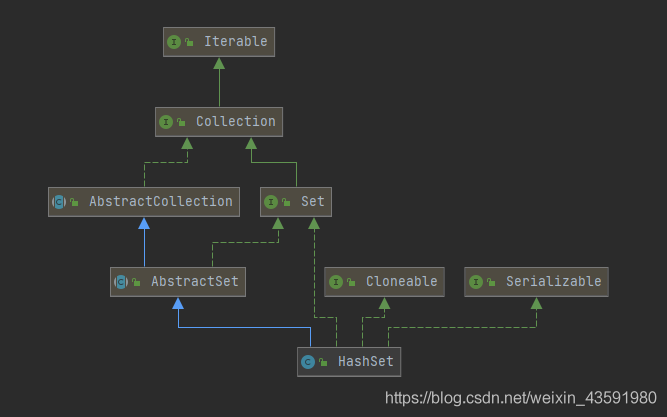
HashSet源码分析
1. 属性(成员变量)
// HashSet内部使用HashMap来存储元素,因此本质上是HashMap private transient HashMap<E,Object> map; // 虚拟对象,用来作为value放到map中(在HashSet底层的HashMap中,key为要存储的元素,value统一为PRESENT) private static final Object PRESENT = new Object();
2. 构造方法
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
// 注意:这里未用public修饰,主要是给LinkedHashSet使用的
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
构造方法都是调用HashMap对应的构造方法。最后一个构造方法有点特殊,它不是public的,意味着它只能被同一个包或者子类调用,这是LinkedHashSet专属的方法。
3. 成员方法
3.1 添加元素add(E e)
// HashSet添加元素的时候,直接调用的是HashMap中的put()方法,
// 把元素本身作为key,把PRESENT作为value,也就是这个map中所有的value都是一样的。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
3.2 删除元素remove(Object o)
// HashSet删除元素,直接调用HashMap的remove方法
public boolean remove(Object o) {
// 注意:map的remove返回是删除元素的value,而Set的remov返回的是boolean类型
// 如果是null的话说明没有该元素,如果不是null肯定等于PRESENT
return map.remove(o)==PRESENT;
}
3.3 查找元素contains(Object o)
// Set中没有get()方法,不像List那样可以按index获取元素
public boolean contains(Object o) {
return map.containsKey(o);
}
4. 完整代码
HashSet是基于HashMap的,所以其源码较少:
package java.util;
import java.io.InvalidObjectException;
import sun.misc.SharedSecrets;
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// 内部元素存储在HashMap中
private transient HashMap<E,Object> map;
// 虚拟元素,用来存到map元素的value中的,没有实际意义
private static final Object PRESENT = new Object();
// 空构造方法
public HashSet() {
map = new HashMap<>();
}
// 把另一个集合的元素全都添加到当前Set中
// 注意,这里初始化map的时候是计算了它的初始容量的
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
// 指定初始容量和装载因子
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
// 只指定初始容量
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
// LinkedHashSet专用的方法
// dummy是没有实际意义的, 只是为了跟上上面那个操持方法签名不同而已
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
// 迭代器
public Iterator<E> iterator() {
return map.keySet().iterator();
}
// 元素个数
public int size() {
return map.size();
}
// 检查是否为空
public boolean isEmpty() {
return map.isEmpty();
}
// 检查是否包含某个元素
public boolean contains(Object o) {
return map.containsKey(o);
}
// 添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 删除元素
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
// 清空所有元素
public void clear() {
map.clear();
}
// 克隆方法
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
// 序列化写出方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// 写出非static非transient属性
s.defaultWriteObject();
// 写出map的容量和装载因子
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// 写出元素个数
s.writeInt(map.size());
// 遍历写出所有元素
for (E e : map.keySet())
s.writeObject(e);
}
// 序列化读入方法
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// 读入非static非transient属性
s.defaultReadObject();
// 读入容量, 并检查不能小于0
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
}
// 读入装载因子, 并检查不能小于等于0或者是NaN(Not a Number)
// java.lang.Float.NaN = 0.0f / 0.0f;
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
// 读入元素个数并检查不能小于0
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " +
size);
}
// 根据元素个数重新设置容量
// 这是为了保证map有足够的容量容纳所有元素, 防止无意义的扩容
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
// 再次检查某些东西, 不重要的代码忽视掉
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
// 创建map, 检查是不是LinkedHashSet类型
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// 读入所有元素, 并放入map中
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
// 可分割的迭代器, 主要用于多线程并行迭代处理时使用
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}
小结
- HashSet内部使用HashMap的key存储元素,以此来保证元素不重复;
- HashSet是无序的,因为HashMap的key是无序的;
- HashSet中允许有一个null元素,因为HashMap允许key为null;
- HashSet是非线程安全的;HashSet是没有get()方法的;
扩展:
当向HashMap中存储n个元素时,它的初始化容量应指定为:((n/0.75f) + 1),如果这个值小于16,就直接使用16为容量。初始化时指定容量是为了减少扩容的次数,提高效率。
LinkedHashSet分析
package java.util;
// LinkedHashSet继承自HashSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
// 传入容量和装载因子
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
// 只传入容量, 装载因子默认为0.75
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
// 使用默认容量16, 默认装载因子0.75
public LinkedHashSet() {
super(16, .75f, true);
}
// 将集合c中的所有元素添加到LinkedHashSet中
// 好奇怪, 这里计算容量的方式又变了
// HashSet中使用的是Math.max((int) (c.size()/.75f) + 1, 16)
// 这一点有点不得其解, 是作者偷懒?
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
// 可分割的迭代器, 主要用于多线程并行迭代处理时使用
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
- LinkedHashSet继承自HashSet,它的添加、删除、查询等方法都是直接用的HashSet的,唯一的不同就是它使用LinkedHashMap存储元素。
- LinkedHashSet是有序的,它是按照插入的顺序排序的。
- LinkedHashSet是不支持按访问顺序对元素排序的,只能按插入顺序排序。
因为,LinkedHashSet所有的构造方法都是调用HashSet的同一个构造方法,如下:
// HashSet的构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
通过调用LinkedHashMap的构造方法初始化map,如下所示:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
总结
这样可以看到,这里把accessOrder写死为false了,所以,LinkedHashSet是不支持按访问顺序对元素排序的,只能按插入顺序排序。还请大家多多关注的其他文章!
加载全部内容