Python工具包 七个非常实用的Python工具包总结
Python学习与数据挖掘 人气:0一、Faker
生产环境通常具有实时数据。把它放到测试环境中并不容易。我们必须对从生产到测试环境的数据进行标记化,这通常会将数据转换为乱码。
此外,在欺诈行业,我们需要找出欺诈身份。为了生成假PII(个人可识别信息),我使用了一个名为Faker的包,这是一个很酷的软件包,可以让你创建一个带有地址、名字等的假PII。

以上是一些虚假数据的例子。带有 GAN 假图像的假数据可以给出一个真实的人。
二、Pywebio
我们知道 Flask 适用于 Python 端的表单、UI 和 restapi。然而,如果想要一个简单的表单,Flask就不太适用了。通常用 Pywebio 来创建,它会创建了一个简单、干净的UI。所有的代码都是用普通的python编写的,并且我们不用额外学新东西!
# A simple script to calculate BMI
from pywebio.input import input, FLOAT
from pywebio.output import put_text
def bmi():
height = input("Input your height(cm):", type=FLOAT)
weight = input("Input your weight(kg):", type=FLOAT)
BMI = weight / (height / 100) ** 2
top_status = [(16, 'Severely underweight'), (18.5, 'Underweight'),
(25, 'Normal'), (30, 'Overweight'),
(35, 'Moderately obese'), (float('inf'), 'Severely obese')]
for top, status in top_status:
if BMI <= top:
put_text('Your BMI: %.1f. Category: %s' % (BMI, status))
break
if __name__ == '__main__':
bmi()
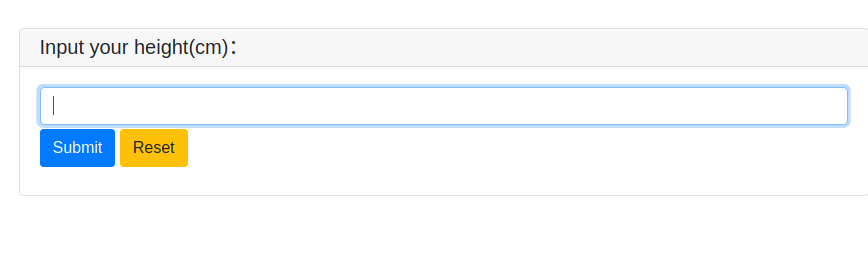
在几秒钟内,它转换为一个前端 UI 网页。我们还可以编写一些会话并处理输入和输出,查看他们的文档以获取详细信息。
三、Airflow
Airflow 是我最喜欢的软件包之一,它是一种工作流管理工具,在 MLOPS 中经常被低估和较少使用,它还可以用于特定的执行间隔、重新训练模型、批处理、网站抓取、投资组合跟踪、自定义新闻提要等。
在工作流程方面,选项是无限的,它还可以连接到特定服务的云服务商。代码可以用 python 写,在 UI 上可以看到执行,非常棒。工作流也可以按特定时间间隔进行安排。
四、Loguru
Logger 是我讨厌但又不得不使用的工具,它是调试应用程序的最佳方法之一。但是,logger 里面的日志太多了,让人比较烦。而 Loguru 在某种程度上就比较友好,它虽不能解决所有挑战,但是它很容易添加日志语句并为其添加更多调试。
from loguru import logger
logger.debug("That's it, beautiful and simple logging!")
它还有助于拆分文件并执行清理,因此我们不需要查看所有历史日志。
logger.add("file_1.log", rotation="500 MB") # Automatically rotate too big file
logger.add("file_2.log", rotation="12:00") # New file is created each day at noon
logger.add("file_3.log", rotation="1 week") # Once the file is too old, it's rotated
logger.add("file_X.log", retention="10 days") # Cleanup after some time
logger.add("file_Y.log", compression="zip") # Save some loved space
你还可以使用参数 backtrace 来回溯执行。
简而言之,在生产环境中使用这个包来调试应用程序或 AI 模型训练是值得的。
五、Pydash
通常在数据清洗或处理中,我们要处理大量的数据清洗。这些是一些较小的项目,需要时间。例如,如何展平列表?当然,你可以写一个清单,但是如果有一个快速功能来执行这些操作呢?
这就是Pydash闪耀的地方,它成为了我的快速转到库,其中包含一系列python实用程序。

以上只是一个小例子,它包含很多功能,绝对值得一看。
六、Weights & Biases
WANDB是跟踪和可视化机器学习管道最有用的包之一,我最喜欢的部分是他们的central dashboard,它类似于记录器,但可以做更多的事情。
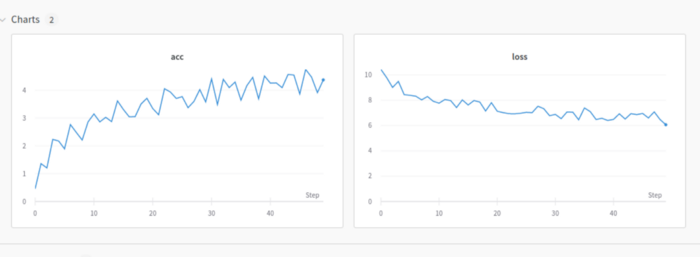
它易于使用,并集成了最流行的库,如 Tensorflow、PyTorch、fastai、huggingface 等。但是,在商业领域使用它时有一些限制,你必须付费订阅。除此之外,它是一个很棒的库。
七、PyCaret
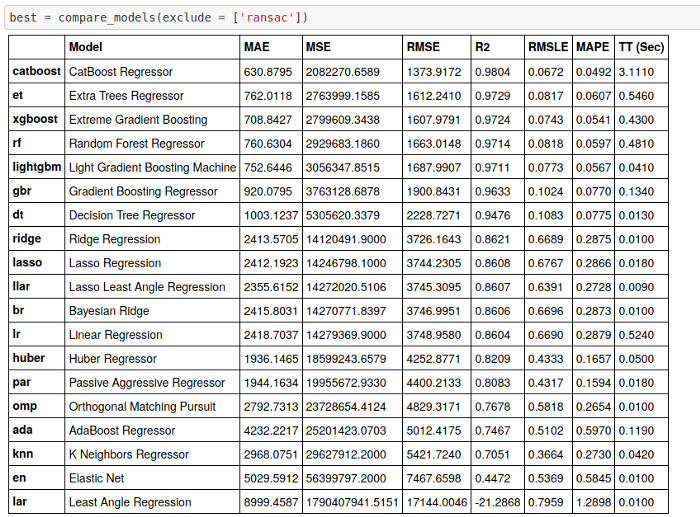
在R中我最喜欢的一个包是caret 包,当我看到 PyCaret 包时,我很兴奋。因为它简化了许多编码,当你想快速做某件事情时可以使用。这个包有很多关于默认参数的选项,可以用不同的度量点运行不同的模型。
Summary
正如本文所说的,我们看到在应用程序开发或数据分析中使用了不同的包,这并不是一份详尽的清单,我会继续为大家分享更多的实用的工具包。
加载全部内容