java面试常见问题 java面试常见问题---ConcurrentHashMap
兴趣使然の草帽路飞 人气:01、请你描述一下ConcurrentHashMap存储数据结构是什么样子呢?
- ConcurrentHashMap 内部的 map 结构和 HashMap 是一致的,都是由:数组 + 链表 + 红黑树 构成。
- ConcurrentHashMap 存储数据的单元和 HashMap 也是一致的,即,Node 结构:
static class Node<K,V> implements Map.Entry<K,V> { // hash值 final int hash; // key final K key; // value volatile V val; // 后驱节点 volatile Node<K,V> next; .... } - ConcurrentHashMap 和 HashMap 区别就在于前者支持并发扩容,其内部通过加锁(自旋锁 + CAS + synchronized + 分段锁)来保证线程安全。
2、请问ConcurrentHashMap的负载因子可以新指定吗?
- 普通的 HashMap 的负载因子可以修改,但是 ConcurrentHashMap 不可以,因为它的负载因子使用 final关键字修饰,值是固定的 0.75 :
// 负载因子:表示散列表的填满程度~ 在ConcurrentHashMap中,该属性是固定值0.75,不可修改~
private static final float LOAD_FACTOR = 0.75f;
3、请问节点的 Node.hash 字段一般情况下必须 >=0 这是为什么?
或者说,Node 节点的 hash 值有几种情况?针对不同情况分析一下?
- 如果
Node.hash = -1,表示当前节点是 **FWD(ForWardingNode) **节点(表示已经被迁移的节点)。 - 如果
Node.hash = -2,表示当前节点已经树化,且当前节点为 TreeBin 对象,TreeBin 对象代理操作红黑树。 - 如果
Node.hash > 0,表示当前节点是正常的 Node 节点,可能是链表,或者单个 Node。
4、请你简述 ConcurrentHashMap 中 sizeCtl 字段的作用(不同情况下的含义)?
sizeCtr 即 Size Control,这个字段一定要仔细去理解一下,这个字段看不懂,可能会整个 ConcurrentHashMap 源码都一脸懵逼。
① sizeCtl == 0 时,表示的是什么情况?
izeCtl == 0,是默认值,表示在真正第一次初始化散链表的时候使用默认容量 16 进行初始化。
② sizeCtl == -1 时,表示什么情况呢?
sizeCtl == -1表示当前散链表正处于初始化状态。有线程正在对当前散列表(table) 进行初始化操作。- ConcurrentHashMap 的散链表是延迟初始化的,在并发条件下必须确保只能初始化一次,所以
sizeCtl == -1就相当于一个"标识锁",防止多个线程去初始化散列表。 - 具体初始化操作就是在
initTable()方法中,会通过 CAS 的方式去修改 sizeCtl 的值为 -1,表示已经有线程正在对散链表进行初始化,其他线程不可以再次初始化,只能等待!
- 如果 CAS 修改
sizeCtl = -1操作成功的线程,可以接着执行对散链表初始化的逻辑。而 CAS 修改失败的线程,在这里会不断的自旋检查,直到散链表初始化结束。 - 这里 CAS 失败的线程会走如下逻辑,即自旋的线程会通过
Thread.yield();方法,短暂释放 CPU 资源,把 CPU 资源让给更饥饿的线程去使用。目的是为了减轻自旋对CPU 性能的消耗。
// SIZECTL:期望值,初始为0 // this 就表示当前 ConcurrentHashMap对象 // sc 表示要修改的 sizeCtrl // -1 表示将 sc 修改为 -1 U.compareAndSwapInt(this, SIZECTL, sc, -1);
③ 初始化完散列表后,map.sizeCtl > 0 时,表示什么情况呢?
sizeCtl > 0时,表示初始化或扩容完成后下一次触发扩容的阈值。比如,sizeCtl = 12 时,当散链表中数据的个数 >=12 时,就会触发扩容操作。
④ sizeCtl < 0 && sizeCtl != -1 时,代表什么情况呢?
- sizeCtl < 0 && sizeCtl != -1 时,表示当前散链表正处于扩容状态。
-(1 + nThreads),表示有n个线程正在一起扩容。这时候,sizeCtl 的高 16 位表示扩容标识戳,低 16 位表示参与并发扩容线程数:1 + nThread, 即当前参与并发扩容的线程数量为 n 个。
5、请你说一下扩容标识戳的作用及其计算方式?
- 根据老表的长度
tab.length去获取扩容唯一标识戳。 - 假设 16 -> 32 这样扩容,那么扩容标识戳的作用就是在多线程并发扩容条件下,所有 16 -> 32 扩容的线程都可以参与并发扩容。
sizeCtl < 0 && sizeCtl != -1时,这时候sizeCtl 的高 16 位就表示扩容标识戳,低 16 位表示参与并发扩容线程数:1 + nThread, 即当前参与并发扩容的线程数量为 n 个。
// 固定值16,与扩容相关,计算扩容时会根据该属性值生成一个扩容标识戳
private static int RESIZE_STAMP_BITS = 16;
/**
* table数组扩容时,计算出一个扩容标识戳,当需要并发扩容时,当前线程必须拿到扩容标识戳才能参与扩容:
*/
static final int resizeStamp(int n) {
// RESIZE_STAMP_BITS:固定值16,与扩容相关,计算扩容时会根据该属性值生成一个扩容标识戳
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
6、ConcurrentHashMap如何保证写数据线程安全?
这个问题其实就是问,向 ConcurrentHashMap 中添加数据确保线程安全是如何实现的。
- ConcurrentHashMap 内部通过加锁(自旋锁 + CAS + synchronized + 分段锁)来保证线程安全。
添加数据具体流程如下:
- ① 首先,先判断散链表是否已经初始化,如果没初始化则先初始化散链表,再进行写入操作。
- ② 当向桶位中写数据时,先判断桶中是否为空,如果是空桶,则直接通过 CAS 的方式将新增数据节点写入桶中。如果 CAS 写入失败,则说明有其他线程已经在当前桶位中写入数据,当前线程竞争失败,回到自旋位置,自旋等待。
- 如果当前桶中不为空,就需要判断当前桶中头结点的类型:
- ③ 如果桶中头结点的 hash 值 为 -1,表示当前桶位的头结点为 FWD 结点,目前散链表正处于扩容过程中。这时候当前线程需要去协助扩容。
- ④ 如果 ②、③ 条件不满足,则表示当前桶位的存放的可能是一条链表,也可能是红黑树的代理对象 TreeBin。这种情况下会使用 synchronized 锁住桶中的头结点,来保证桶内的写操作是线程安全的。
7、描述一下ConcurrentHashMap中的hash寻址算法
ConcurrentHashMap 的寻址算法和 HashMap 差别不大:
- 首先是通过 Node 节点的 Key 获取到它的 HashCode 值,再将 HashCode 值通过 spread(int h)方法进行绕道运算,进而得到最终的 Hash 值。
- 获取到最终的 hash 值后,再通过寻址公式:
index = (tab.length -1) & hash获得桶位下标。
/**
* 计算Node节点hash值的算法:参数h为hash值
* eg:
* h二进制为 --> 1100 0011 1010 0101 0001 1100 0001 1110
* (h >>> 16) --> 0000 0000 0000 0000 1100 0011 1010 0101
* (h ^ (h >>> 16)) --> 1100 0011 1010 0101 1101 1111 1011 1011
* 注:(h ^ (h >>> 16)) 目的是让h的高16位也参与寻址计算,使得到的hash值更分散,减少hash冲突产生~
* ------------------------------------------------------------------------------
* HASH_BITS --> 0111 1111 1111 1111 1111 1111 1111 1111
* (h ^ (h >>> 16)) --> 1100 0011 1010 0101 1101 1111 1011 1011
* (h ^ (h >>> 16)) & HASH_BITS --> 0100 0011 1010 0101 1101 1111 1011 1011
* 注: (h ^ (h >>> 16))得到的结果再& HASH_BITS,目的是为了让得到的hash值结果始终是一个正数
*/
static final int spread(int h) {
// 让原来的hash值异或^原来hash值的右移16位,再与&上HASH_BITS(0x7fffffff: 二进制为31个1)
return (h ^ (h >>> 16)) & HASH_BITS;
}
8、ConcurrentHashMap如何统计当前散列表中的数据量?
ConcurrentHashMap 统计存储数据的数量是通过 addCount(long x, int check) 方法实现的,本质上是借助了 LongAdder 原子类。
ConcurrentHashMap为什么不采用 ConcurrentHashMap为什么不采用 AtomicLong 统计散列表数据量呢?统计散列表数据量呢?
- 因为 AtomicLong 原子类自增操作是基于 CAS 实现的,基于 CAS 实现会导致一个问题,就是当大量线程同时执行 CAS 操作时,只能有一个线程执行成功,而其他所有线程都会因为失败而进入自旋状态,自旋本身就是一个 while(true) 的循环,非常耗费系统资源。
那么 LongAdder 是如何保证大并发量下,性能依旧高效呢?
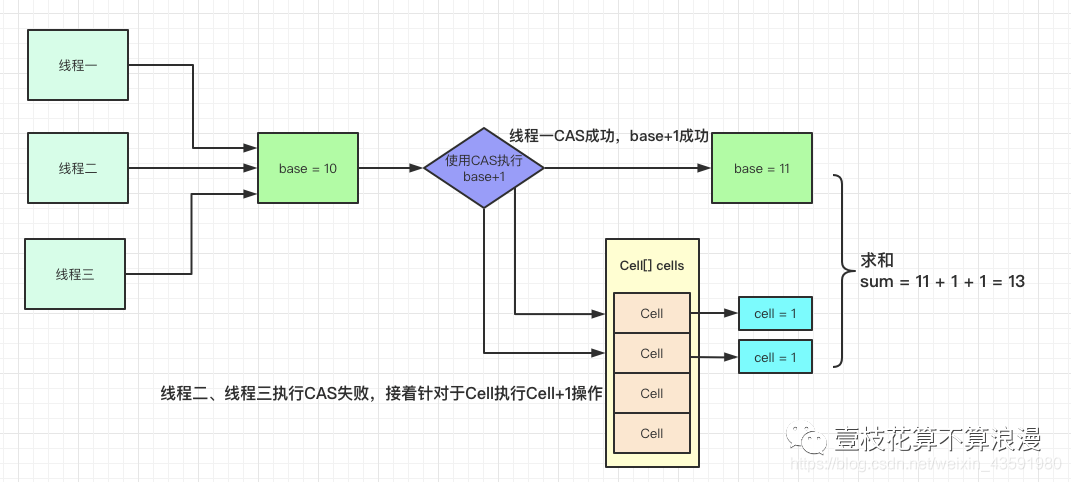
先看下LongAdder的操作原理图:

LongAdder采用"分段"的方式降低CAS失败的频次,典型的用空间换时间:
LongAdder有一个全局变量volatile long base;值,当并发不高的情况下都是通过CAS来直接操作base值,如果CAS失败,则针对LongAdder中的Cell[]数组中的Cell进行CAS操作,减少失败的概率。
如当前类中base = 10,有三个线程进行CAS原子性的 加1操作,线程一执行成功,此时base=11,线程二、线程三执行失败后开始针对于Cell[]数组中的Cell元素进行加1操作,同样也是CAS操作,此时数组index=1和index=2中Cell的value都被设置为了1。
执行完成后,统计累加数据:sum = 11 + 1 + 1 = 13,利用LongAdder进行累加的操作就执行完了,流程图如下:
9、触发扩容条件的线程,执行的预处理工作都有哪些?
- 首先,触发扩容条件的线程,要做的第一件事就是通过 CAS 的方式修改 sizeCtl 字段值,使其高 16 位为扩容唯一标识戳,低 16 位为(参与扩容的线程数 + 1),表示有线程正在进行扩容逻辑!
- 注意:这里高 16 位的扩容唯一标识戳是根据当前散链表的长度计算得来,其最高位是 1。那么最终得到的 sizeCtl 就应该是一个负数。
- 然后,当前触发扩容条件的线程会创建一个新的散链表,大小为原来旧散链表的 2 倍。并且将新散链表的引用赋给 map.nextTable 字段。
- 又因为 ConcurrentHashMap 是支持多线程并发扩容的,所以需要让协助扩容的线程知道旧散链表数据迁移到新散链表的进度。为此 ConcurrentHashMap 提供了一个
transferIndex字段,用于记录旧散链表数据的总迁移进度!迁移工作进度是从 高位桶开始,一直迁移到下标是 0 的桶位。
10、旧散链表中迁移完毕后的桶,如何做标记?
- 旧散链表中迁移完毕的桶,需要用
ForwardingNode对象表示桶内节点,这种 Node 比较特殊,是用来表示当前桶中的数据已经被迁移到新散链表的桶中去了。
ForwardingNode 有哪些作用?
- ForwardingNode 对象内部提供了一个用于向新散链表中查询目标数据的find()方法。
- 当此时某个线程刚好在旧散链表中查询目标元素时,刚好遇到当前桶位中存放的是 FWD 节点,那么就可以通过 FWD 节点的
find()方法重新定向到新散链表中去查询目标元素!
11、如果散列表正在库容时,再来新的写入请求该如何处理呢?
这里要分两种情况考虑:
- 如果当前线程执行写入操作时,根据寻址算法访问到的桶中不是 FWD 节点(即,当前桶中数据没有被迁移)。那么此时先判断桶中是否为空,如果为空则 CAS 方式写入数据。而如果桶不为空,则可能是链表或者 TreeBin,这时候需要通过 synchronized 关键字锁住桶的头结点再进行写入操作。
- 而如果如果当前线程执行写入操作时,根据寻址算法访问到的桶中是 FWD 节点(即,当前桶中数据已经被迁移)。
- 碰到 FWD 节点,说明此时散链表正在进行扩容,这时候需要当前线程也加入进去,去协助散链表扩容(helpTransfer(tab, f);协助扩容是为了尽量减少扩容所花费在数据迁移上的时间)。
- 当前线程加入到协助扩容中后,ConcurrentHashMap 会根据全局的transferIndex字段去给当前线程分配迁移工作任务(需要负责迁移旧散链表的桶位区间)。例如,让当前线程负责迁移旧散链表中 【0-4】桶位上的数据到新散链表。
- 一直到当前线程分配不到要负责迁移的任务时,则退出协助扩容,即扩容结束。这时候,当前线程就可以继续执行写入数据的逻辑了!
12、扩容期间,扩容工作线程如何维护sizeCtl的低16位呢?
- 每一个执行扩容任务的线程(包含协助扩容),它在开始工作之前,都会更新
sizeCtl的低 16 位,即让低 16 位 +1,说明又加入一个新的线程去执行扩容。 - 每个执行扩容的线程都会被分配一个迁移工作任务区间,如果当前线程所负责的任务区间迁移工作完成了,没有再被分配迁移任务区间,那么此时当前线程就可以退出协助扩容了,这时候更新
sizeCtl的低 16 位,即让低 16 位 -1,说明有一个线程退出并发扩容了。 - 如果
sizeCtl低 16 位-1后的值为 1,则说明当前线程是最后一个退出并发扩容的线程。
13、当桶位中链表升级为红黑树,且当前红黑树上有读线程正在访问,那么如果再来新的写线程请求该怎么处理?
写线程会被阻塞,因为红黑树比较特殊,新写入数据,可能会触发红黑树的自平衡,这就会导致树的结构发生变化,会影响读线程的读取结果!
在红黑树上读取数据和写入数据是互斥的,具体原理分析如下:
- 我们知道
ConcurrentHashMap中的红黑树由 TreeBin 来代理,TreeBin 内部有一个 Int 类型的 state 字段。 - 当读线程在读取数据时,会使用 CAS 的方式将 state 值 +4(表示加了读锁),读取数据完毕后,再使用CAS 的方式将 state 值 -4。
- 如果写线程去向红黑树中写入数据时,会先检查 state 值是否等于 0,如果是 0,则说明没有读线程在检索数据,这时候可以直接写入数据,写线程也会通过 CAS 的方式将 state 字段值设置为 1(表示加了写锁)。
- 如果写线程检查 state 值不是 0,这时候就会
park()挂起当前线程,使其等待被唤醒。挂起写线程时,写线程会先将state值的第 2 个 bit 位设置为 1(二进制为 10),转换成十进制就是 2,表示有写线程等待被唤醒。
反过来,当红黑树上有写线程正在执行写入操作,那么如果有新的读线程请求该怎么处理?
- TreeBin 对象内部保留了一个链表结构,就是为了这种情况而设计的。这时候会让新来的读线程到链表上去访问数据,而不经过红黑树。
14、挂起等待的写线程后,什么时候将其唤醒再继续执行写操作呢?
- 上一个问题中,我们分析了:当读线程在读取数据时,会使用 CAS 的方式将 state 值 +4(表示加了读锁),读取数据完毕后,再使用CAS 的方式将
state值 -4。 - 当 state 值减去 4 后,读线程会先检查一下 state 值是不是 2,如果是 2 ,则说明有等待被唤醒的写线程在挂起等候,这时候调用
unsafe.unpark()方法去唤醒该写线程。
15、总结
文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,后续会亿点点的更新!希望大家多多关注的其他内容!
加载全部内容