Python 拼音转换 Python实现拼音转换
一天一篇Python库 人气:2什么是拼音转换
在我们学习语言之前,我们一般会学习拼音来认识汉字,并学会如何读汉字。所以,拼音在对于我们语言的重要性不言而喻。
而拼音转换指的是将汉字转为拼音的过程。但是,我们中文博大精深,一般来说某个字并不仅仅只有一个读音,比如“翟”,它作为姓氏可以读作zhái,作为其他可读作di。这是就需要结合上下文,或者说结合与其组合的词汇进行转换拼音。不仅如此,拼音还有音调,比如一二三四声表示的意义有时候也是不一样的。
本篇博文将介绍字符串到拼音的转换。
拼音转换
首先,HanLP库提供的拼音转换为本位于data/dictionary/pinyin/pinyin.txt文件中。每行分别由=隔开汉字与拼音。其中多音字的拼音数量多余汉字数量。在实际的转换过程中,默认读取多音字的第一个拼音,除非匹配到更长的词语。
此外,HanLP库还支持声母,韵母,音调,音标以及输入法首字母与收声母功能。当然,也能给前文的繁体字转换为拼音。
下面,我们来看一段代码示例:
if __name__ == "__main__":
text = "重载不是重量"
pinyin_list = HanLP.convertToPinyinList(text)
print(pinyin_list)
运行之后,控制台输出如下:

可以看到,基本上每个字的拼音都输出了。如果程序判断不出来多音字是哪个声调,会输出其所有的声调。比如这里的体输出了3声和1声,重输出了3声与2声。
在python中,我们通过HanLP.convertToPinyinList进行汉字与拼音的转换。
输出音调
鉴于我们已经知道了如何转换汉字到拼音,那么我们现在需要实现的是单独获取每个汉字的音调,不需要声调。现在该如何去实现呢?不妨先来看看代码:
if __name__ == "__main__":
Pinyin = JClass("com.hankcs.hanlp.dictionary.py.Pinyin")
text = "重载不是体重"
pinyin_list = HanLP.convertToPinyinList(text)
print(pinyin_list)
print("输出音调")
for pinyin in pinyin_list:
print("%s," % pinyin.getPinyinWithToneMark(), end=" ")
如上面代码所示,我们获取了Java的HanLP库中的Pinyin类,这个类可以帮我们处理很多的拼音相关的问题,比如这里的获取音调。
运行之后,效果如下:
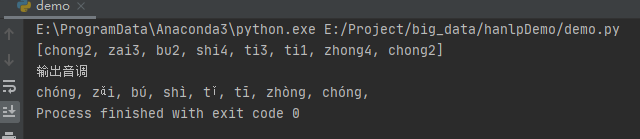
需要注意的是,前面博文已经说过了,通过python进行HanLP库使用时,尽量调用Java类进行处理,因为Java类的处理时间比python快很多。这里我们通过Pinyin类的getPinyinWithToneMark()方法获取声调。
输出声调
既然可以只输出音调,那么肯定也可以单独输出声调。具体代码如下:
if __name__ == "__main__":
Pinyin = JClass("com.hankcs.hanlp.dictionary.py.Pinyin")
text = "重载不是体重"
pinyin_list = HanLP.convertToPinyinList(text)
print(pinyin_list)
print("输出声调")
for pinyin in pinyin_list:
print("%s," % pinyin.getTone(), end=" ")
运行之后,效果如下:
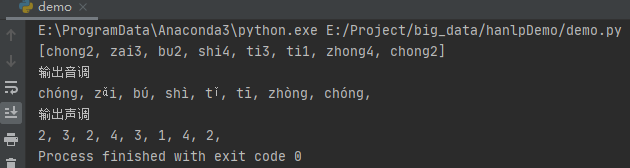
这里我们通过Pinyin类的getTone()方法获取声调。
输出声母
同样的,我们还可以输出声母。代码如下:
if __name__ == "__main__":
Pinyin = JClass("com.hankcs.hanlp.dictionary.py.Pinyin")
text = "重载不是体重"
pinyin_list = HanLP.convertToPinyinList(text)
print(pinyin_list)
print("\r\n输出声母")
for pinyin in pinyin_list:
print("%s," % pinyin.getShengmu(), end=" ")
运行之后,效果如下:
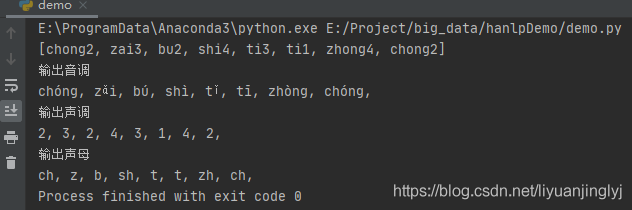
这里我们用getShengmu()方法输出声母,方法名就是中文意思,很好理解。
输出韵母
接着,我们再来输出韵母。代码如下:
if __name__ == "__main__":
Pinyin = JClass("com.hankcs.hanlp.dictionary.py.Pinyin")
text = "重载不是体重"
pinyin_list = HanLP.convertToPinyinList(text)
print(pinyin_list)
print("\r\n输出韵母")
for pinyin in pinyin_list:
print("%s," % pinyin.getYunmu(), end=" ")
运行之后,效果如下:
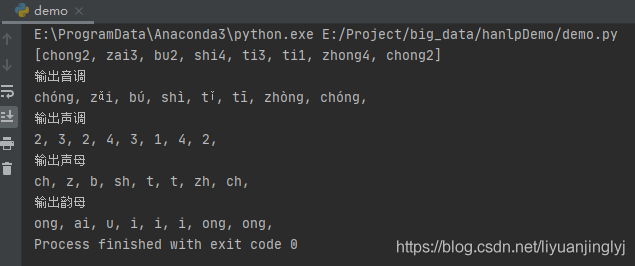
这里我们用getYunmu()方法输出韵母,方法名就是中文意思,很好理解。
处理数字拼音
除此之外,上面因为都是汉字,所以大家肯定都很好处理成拼音。但是现在很多时候,中文文本里面并不仅仅只有汉字,也有数字和英文。但是拼音是汉字独有的,那怎么办呢?
我们先来看看按上面直接处理带数字与英文时,效果怎么样。代码如下所示:
if __name__ == "__main__":
Pinyin = JClass("com.hankcs.hanlp.dictionary.py.Pinyin")
text = "我们到2035年就会称为世界第一"
pinyin_list = HanLP.convertToPinyinList(text)
print(pinyin_list)
运行之后,效果如下:

可以看到数字都直接替换为none5,也就是缺失的意义。拼音文件找不到与其匹配的汉语拼音。
而我们实际在处理中文文档时,都是保留数字与英文的并不直接翻译。其实这里我们想保留其数字的话,HanLP.convertToPinyinString()方法就能实现,我们来看看这个方法的完整定义:
convertToPinyinString(转换为拼音的字符串文本,输出间隔符,布尔类型)
相信看了上面方法的读者应该很快就知道了,第3个布尔类型就是转换数字与保留数字的关键参数,这里我们再来变换代码:
if __name__ == "__main__":
Pinyin = JClass("com.hankcs.hanlp.dictionary.py.Pinyin")
text = "我们到2035年就会称为世界第一"
pinyin_list = HanLP.convertToPinyinString(text," ",False)
print(pinyin_list)
运行之后,我们的英文与数字就会原封不动的保留下来。效果如下:

加载全部内容