变长双向rnn的用法 变长双向rnn的正确使用姿势教学
代码医生 人气:0如何使用双向RNN
在《深度学习之TensorFlow入门、原理与进阶实战》一书的9.4.2中的第4小节中,介绍过变长动态RNN的实现。
这里在来延伸的讲解一下双向动态rnn在处理变长序列时的应用。其实双向RNN的使用中,有一个隐含的注意事项,非常容易犯错。
本文就在介绍下双向RNN的常用函数、用法及注意事项。
动态双向rnn有两个函数:
stack_bidirectional_dynamic_rnn bidirectional_dynamic_rnn
二者的实现上大同小异,放置的位置也不一样,前者放在contrib下面,而后者显得更加根红苗正,放在了tf的核心库下面。在使用时二者的返回值也有所区别。下面就来一一介绍。
示例代码
先以GRU的cell代码为例:
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
# 创建输入数据
X = np.random.randn(2, 4, 5)# 批次 、序列长度、样本维度
# 第二个样本长度为3
X[1,2:] = 0
seq_lengths = [4, 2]
Gstacked_rnn = []
Gstacked_bw_rnn = []
for i in range(3):
Gstacked_rnn.append(tf.contrib.rnn.GRUCell(3))
Gstacked_bw_rnn.append(tf.contrib.rnn.GRUCell(3))
#建立前向和后向的三层RNN
Gmcell = tf.contrib.rnn.MultiRNNCell(Gstacked_rnn)
Gmcell_bw = tf.contrib.rnn.MultiRNNCell(Gstacked_bw_rnn)
sGbioutputs, sGoutput_state_fw, sGoutput_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([Gmcell],[Gmcell_bw], X,sequence_length=seq_lengths, dtype=tf.float64)
Gbioutputs, Goutput_state_fw = tf.nn.bidirectional_dynamic_rnn(Gmcell,Gmcell_bw, X,sequence_length=seq_lengths,dtype=tf.float64)
上面例子中是创建双向RNN的方法示例。可以看到带有stack的双向RNN会输出3个返回值,而不带有stack的双向RNN会输出2个返回值。
这里面还要注意的是,在没有未cell初始化时必须要将dtype参数赋值。不然会报错。
代码:BiRNN输出
下面添加代码,将输出的值打印出来,看一下,这两个函数到底是输出的是啥?
#建立一个会话
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
sgbresult,sgstate_fw,sgstate_bw=sess.run([sGbioutputs,sGoutput_state_fw,sGoutput_state_bw])
print("全序列:\n", sgbresult[0])
print("短序列:\n", sgbresult[1])
print('Gru的状态:',len(sgstate_fw[0]),'\n',sgstate_fw[0][0],'\n',sgstate_fw[0][1],'\n',sgstate_fw[0][2])
print('Gru的状态:',len(sgstate_bw[0]),'\n',sgstate_bw[0][0],'\n',sgstate_bw[0][1],'\n',sgstate_bw[0][2])
先看一下带有stack的双向RNN输出的内容:

我们输入的数据的批次是2,第一个序列长度是4,第二个序列长度是2.
图中共有4部分输出,可以看到,第一部分(全序列)就是序列长度为4的结果,第二部分(短序列)就是序列长度为2的结果。由于没一层都是由3个RNN的GRU cell组成,所以每个序列的输出都为3.很显然,对于这样的结果输出,必须要将短序列后面的0去掉才可以用。
好在该函数还有第二个输出值,GRU的状态。可以直接使用状态里的值,而不需要对原始结果进行去0的变化。
由于单个GRU本来就是没有状态的。所以该函数将最后的输出作为状态返回。该函数有两个状态返回,分别代表前向和后向。每一个方向的状态都会返回3个元素。这是因为每个方向的网络都有3层GRU组成。在使用时,一般都会取最后一个状态。图中红色部分为前向中,两个样本对应的输出,这个很好理解。
重点要看蓝色的部分,即反向的状态值对应的是原始数据中最其实的序列输入。因为是反向RNN,在反向循环时,是会把序列中最后的放在最前面,所以反向网络的生成结果就会与最开始的序列相对应。
对于特征提取任务处理时,正向与反向的最后值都为该序列的特征,需要合并起来统一处理。但是对于下一个序列预测任务时,建议直接使用正向的RNN网络就可以了。
如果要获取双向RNN的结果,尤其是变长情况下,通过状态拿到值直接拼接起来才是正确的做法。即便不是变长。直接使用输出值来拼接,会损失掉反向的一部分特征结果。这是需要值得注意的地方。
代码:BiRNN输出
好了。在接着看下不带stack的函数输出是什么样子的
gbresult,state_fw=sess.run([Gbioutputs,Goutput_state_fw])
print("正向:\n", gbresult[0])
print("反向:\n", gbresult[1])
print('状态:',len(state_fw),'\n',state_fw[0],'\n',state_fw[1]) #state_fw[0]:【层,批次,cell个数】 重头到最后一个序列
print(state_fw[0][-1],state_fw[1][-1])
out = np.concatenate((state_fw[0][-1],state_fw[1][-1]),axis = 1)
print("拼接",out)
这次,在输出基本内容基础上,直接将结果拼接起来。上面代码运行后会输出如下内容。
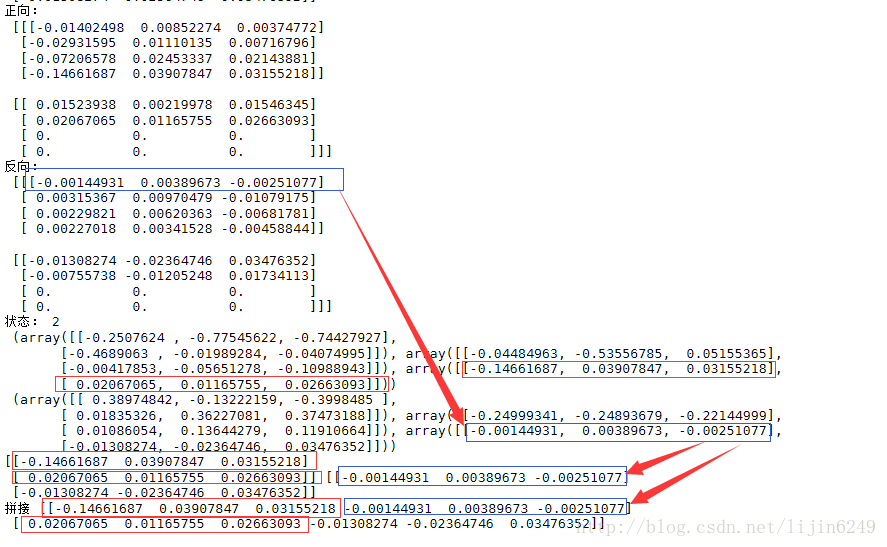
同样正向用红色,反向用蓝色。改函数返回的输出值,没有将正反向拼接。输出的状态虽然是一个值,但是里面有两个元素,一个代表正向状态,一个代表反向状态.
从输出中可以看到,最后一行实现了最终结果的真正拼接。在使用双向rnn时可以按照上面的例子代码将其状态拼接成一条完整输出,然后在进行处理。
代码:LSTM的双向RNN
类似的如果想使用LSTM cell。将前面的GRU部分替换即可,代码如下:
stacked_rnn = []
stacked_bw_rnn = []
for i in range(3):
stacked_rnn.append(tf.contrib.rnn.LSTMCell(3))
stacked_bw_rnn.append(tf.contrib.rnn.LSTMCell(3))
mcell = tf.contrib.rnn.MultiRNNCell(stacked_rnn)
mcell_bw = tf.contrib.rnn.MultiRNNCell(stacked_bw_rnn)
bioutputs, output_state_fw, output_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([mcell],[mcell_bw], X,sequence_length=seq_lengths,
dtype=tf.float64)
bioutputs, output_state_fw = tf.nn.bidirectional_dynamic_rnn(mcell,mcell_bw, X,sequence_length=seq_lengths,
dtype=tf.float64)
至于输出的内容是什么,可以按照前面GRU的输出部分显示出来自己观察。如何拼接,也可以参照GRU的例子来做。
通过将正反向的状态拼接起来才可以获得双向RNN的最终输出特征。千万不要直接拿着输出不加处理的来进行后续的运算,这会损失一大部分的运算特征。
该部分内容属于《深度学习之TensorFlow入门、原理与进阶实战》一书的内容补充。关于RNN的更多介绍可以参看书中第九章的详细内容。
我对双向RNN 的理解
1、双向RNN使用的场景:有些情况下,当前的输出不只依赖于之前的序列元素,还可能依赖之后的序列元素; 比如做完形填空,机器翻译等应用。
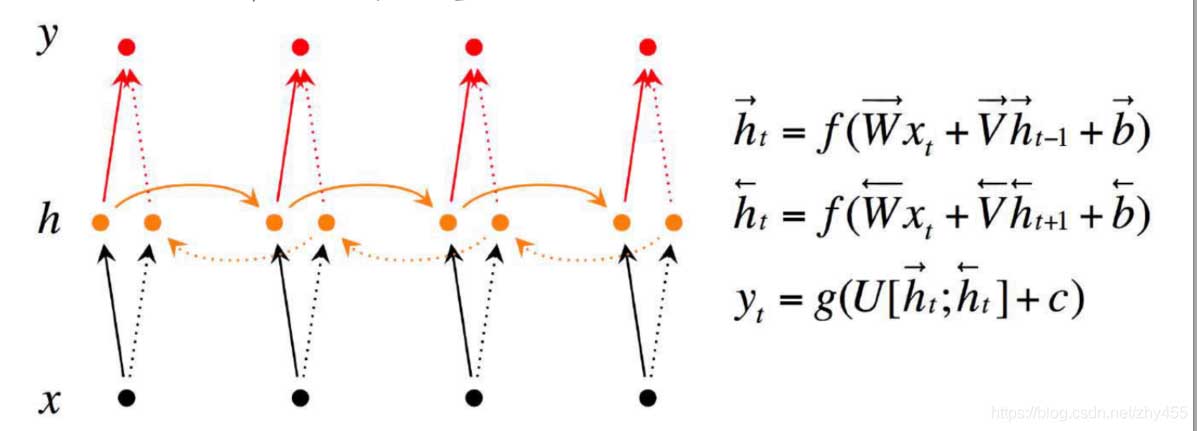
2、Tensorflow 中实现双向RNN 的API是:bidirectional_dynamic_rnn; 其本质主要是做了两次reverse:
第一次reverse:将输入序列进行reverse,然后送入dynamic_rnn做一次运算.
第二次reverse:将上面dynamic_rnn返回的outputs进行reverse,保证正向和反向输出的time是对上的.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容