python dbscan python实现dbscan算法
克金森沐沐 人气:0想了解python实现dbscan算法的相关内容吗,克金森沐沐在本文为您仔细讲解python dbscan 的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:python,dbscan算法,下面大家一起来学习吧。
DBSCAN 算法是一种基于密度的空间聚类算法。该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其它空间对象)的数目不小于某一给定阀值。DBSCAN 算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。但是由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有两个比较明显的弱点:
1. 当数据量增大时,要求较大的内存支持 I/0 消耗也很大;
2. 当空间聚类的密度不均匀、聚类间距离相差很大时,聚类质量较差。
DBSCAN算法的聚类过程
DBSCAN算法基于一个事实:一个聚类可以由其中的任何核心对象唯一确定。等价可以表述为: 任一满足核心对象条件的数据对象p,数据库D中所有从p密度可达的数据对象所组成的集合构成了一个完整的聚类C,且p属于C。
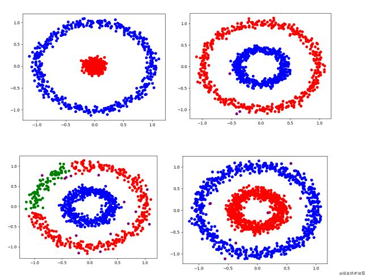
先上结果

大致流程
先根据给定的半径 r 确定中心点,也就是这类点在半径r内包含的点数量 n 大于我们的要求(n>=minPionts)
然后遍历所有的中心点,将互相可通达的中心点与其包括的点分为一组
全部分完组之后,没有被纳入任何一组的点就是离群点啦!
导入相关依赖
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets
求点跟点之间距离(欧氏距离)
def cuircl(pointA,pointB):
distance = np.sqrt(np.sum(np.power(pointA - pointB,2)))
return distance
求临时簇,即确定所有的中心点,非中心点
def firstCluster(dataSets,r,include):
cluster = []
m = np.shape(dataSets)[0]
ungrouped = np.array([i for i in range (m)])
for i in range (m):
tempCluster = []
#第一位存储中心点簇
tempCluster.append(i)
for j in range (m):
if (cuircl(dataSets[i,:],dataSets[j,:]) < r and i != j ):
tempCluster.append(j)
tempCluster = np.mat(np.array(tempCluster))
if (np.size(tempCluster)) >= include:
cluster.append(np.array(tempCluster).flatten())
#返回的是List
center=[]
n = np.shape(cluster)[0]
for k in range (n):
center.append(cluster[k][0])
#其他的就是非中心点啦
ungrouped = np.delete(ungrouped,center)
#ungrouped为非中心点
return cluster,center,ungrouped
将所有中心点遍历并进行聚集
def clusterGrouped(tempcluster,centers):
m = np.shape(tempcluster)[0]
group = []
#对应点是否遍历过
position = np.ones(m)
unvisited = []
#未遍历点
unvisited.extend(centers)
#所有点均遍历完毕
for i in range (len(position)):
coreNeihbor = []
result = []
#删除第一个
#刨去自己的邻居结点,这一段就类似于深度遍历
if position[i]:
#将邻结点填入
coreNeihbor.extend(list(tempcluster[i][:]))
position[i] = 0
temp = coreNeihbor
#按照深度遍历遍历完所有可达点
#遍历完所有的邻居结点
while len(coreNeihbor) > 0 :
#选择当前点
present = coreNeihbor[0]
for j in range(len(position)):
#如果没有访问过
if position[j] == 1:
same = []
#求所有的可达点
if (present in tempcluster[j]):
cluster = tempcluster[j].tolist()
diff = []
for x in cluster:
if x not in temp:
#确保没有重复点
diff.append(x)
temp.extend(diff)
position[j] = 0
# 删掉当前点
del coreNeihbor[0]
result.extend(temp)
group.append(list(set(result)))
i +=1
return group
核心算法完毕!
生成同心圆类型的随机数据进行测试
#生成非凸数据 factor表示内外圈距离比
X,Y1 = datasets.make_circles(n_samples = 1500, factor = .4, noise = .07)
#参数选择,0.1为圆半径,6为判定中心点所要求的点个数,生成分类结果
tempcluster,center,ungrouped = firstCluster(X,0.1,6)
group = clusterGrouped(tempcluster,center)
#以下是分类后对数据进行进一步处理
num = len(group)
voice = list(ungrouped)
Y = []
for i in range (num):
Y.append(X[group[i]])
flat = []
for i in range(num):
flat.extend(group[i])
diff = [x for x in voice if x not in flat]
Y.append(X[diff])
Y = np.mat(np.array(Y))
绘图~
color = ['red','blue','green','black','pink','orange']
for i in range(num):
plt.scatter(Y[0,i][:,0],Y[0,i][:,1],c=color[i])
plt.scatter(Y[0,-1][:,0],Y[0,-1][:,1],c = 'purple')
plt.show()
结果
紫色点就是离散点
加载全部内容