Python文档批量翻译工具 用 Python 写的文档批量翻译工具效果竟然超出想象
程序员启航 人气:0大家好,我是启航。
本文将给大家分享一个实用的Python办公自动化脚本 「利用Python批量翻译英文Word文档并保留格式」,最终效果甚至比部分收费的软件还要好!先来看看具体的工作内容。
一、需求描述
手上有大量外文文档(本案例以5份为例,分别命名为 test1.docx test2.docx 以此类推),其中一份如下:

基本需求:「批量将这些文档的内容全部翻译成中文,并转存到新的文件中」,效果如下:

高级需求:基本需求满足的同时,要求 「保留原文档的格式」,效果如下:

二、逻辑梳理
1. 翻译 API
本需求的核心是翻译,策略是利用网络的翻译 API,这里推荐百度翻译开放平台,不考虑并发数的话可以用标准版,免费使用不限字符量!
“百度翻译开放平台:
”http://api.fanyi.baidu.com/api/trans/product/index
在使用百度的通用翻译 API 之前需要完成以下工作:
使用百度账号登录百度翻译开放平台(http://api.fanyi.baidu.com);
注册成为开发者,获得APPID;
进行开发者认证(如仅需标准版可跳过);
开通通用翻译API服务:开通链接
参考技术文档和Demo编写代码
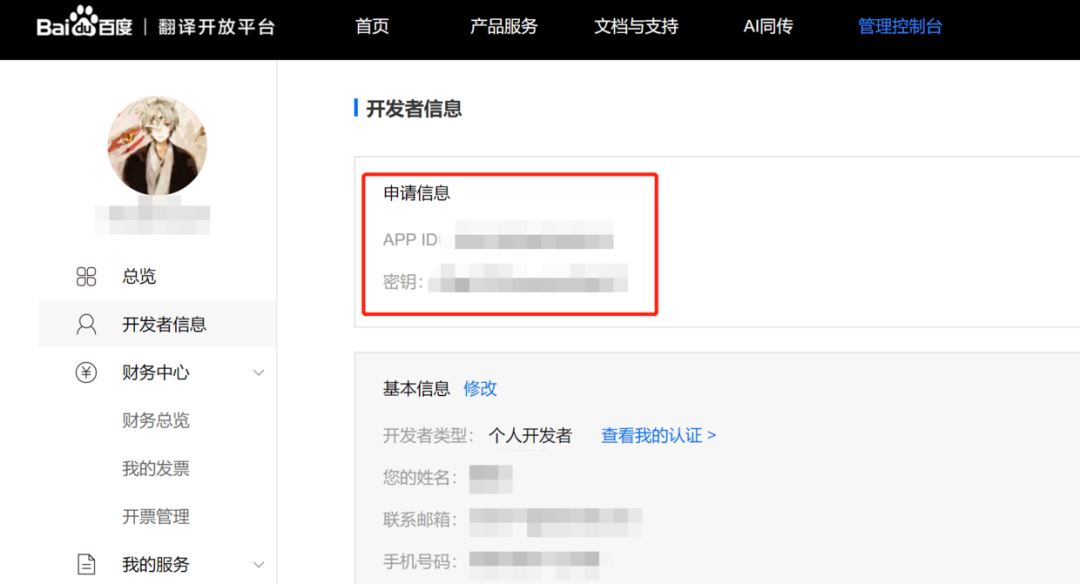
完成后在个人页面在即可看到 ID 和密钥,这个很重要!下面给出整理好的通用翻译 API 的 demo,已经对输出做简单修改,代码拿走就能用!
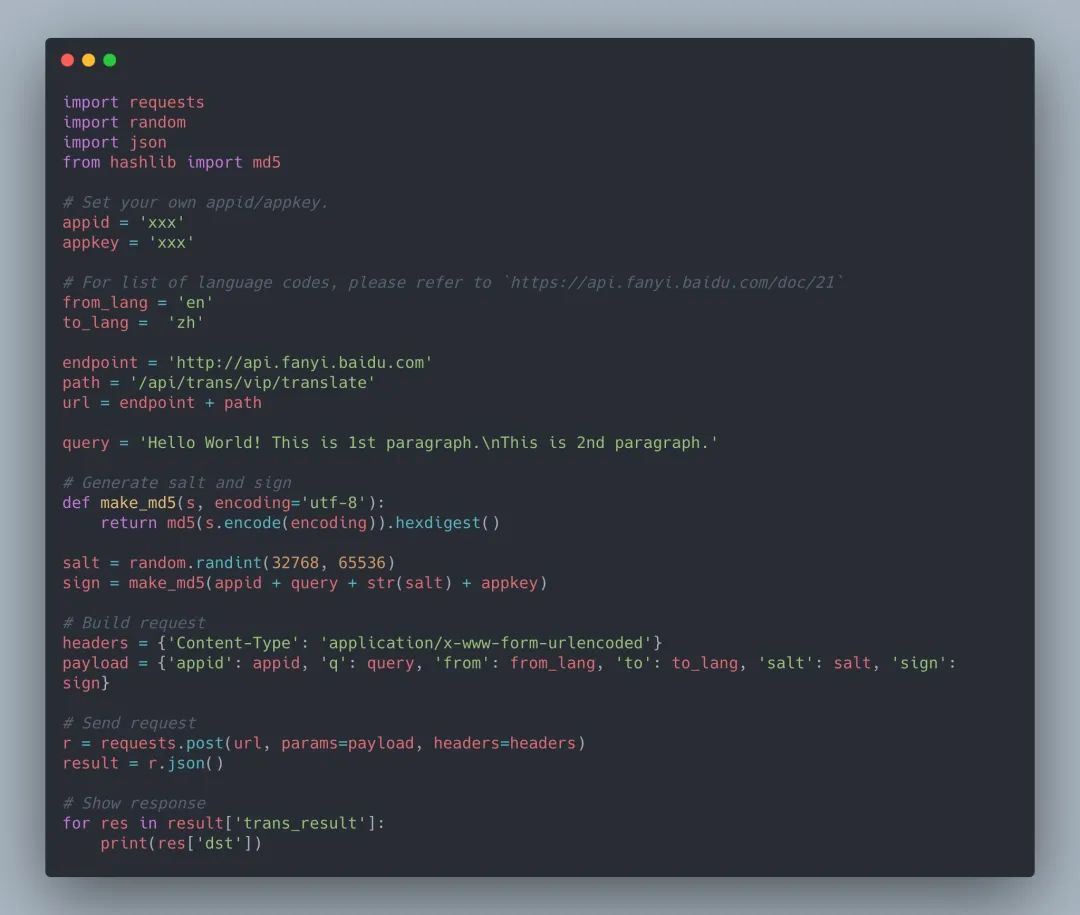
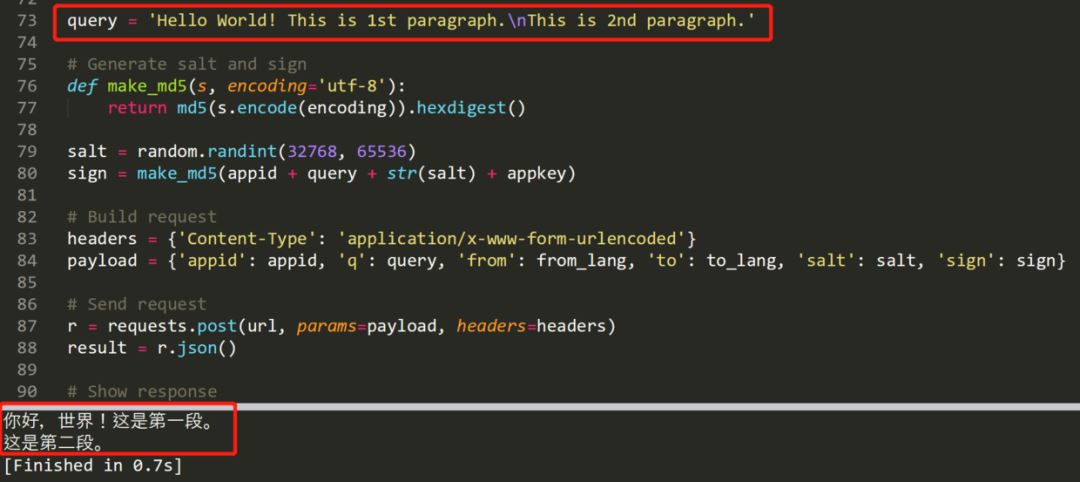
可以看到,测试内容准确的被翻译出来,注意如果需要多次访问 API,免费版有并发数和时间限制,可以用 time 模块睡眠一秒
2. 格式修改
高级需求的难点就是保留格式,简单来说原文档的页面格式和段落格式是什么,翻译后对应的部分就是什么。
基于上述的逻辑关系,只需要获取原文档的对应内容再赋值给新翻译的文档即可。(暂时只能满足页面设置和段落设置的统一,针对一段中特定词语的格式修改,保证精确性需要基于自然语言处理NLP,本文暂不涉及)
2.1 页面样式
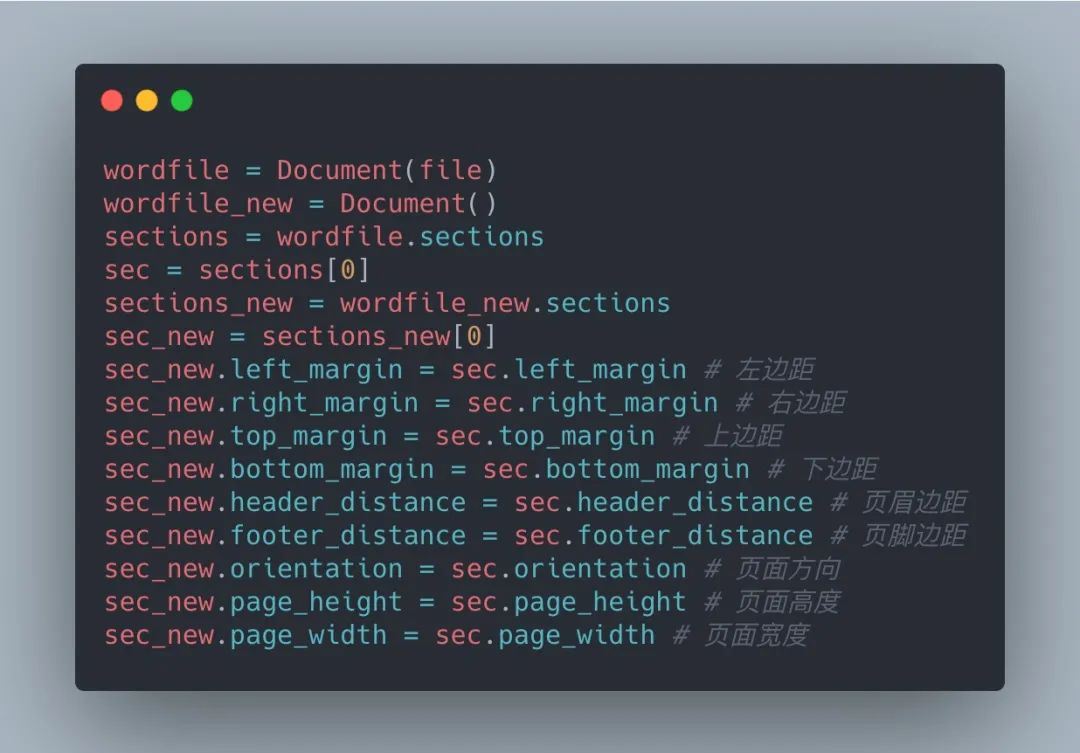
页面样式只要包括边距、方向、高度、宽度等等,从原文档中可以看到,采取的是窄边距。但我们无需知道窄边距四个方向应该如何设置,只需要在代码中呈现新旧文档的变量传递即可,具体如下
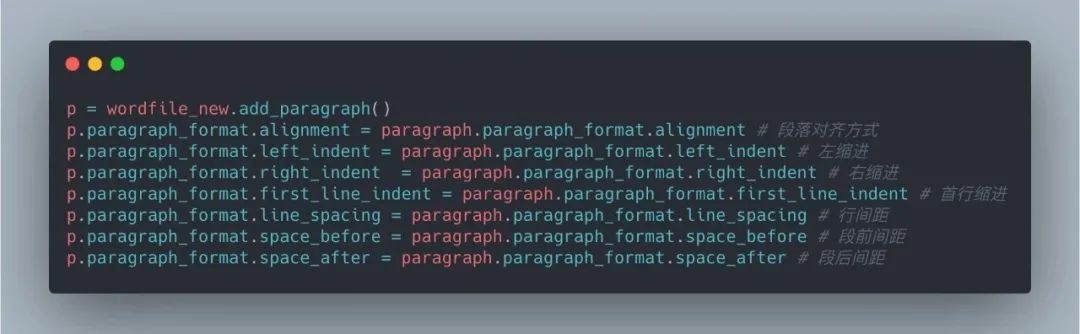
2.2 段落样式
段落样式包括对齐、缩进、间距等等,原文档中采取了段后缩进,标题是居中对齐。这些设置在变量传递中能够很好完成。如果原文档中没有设置的变量值为 None
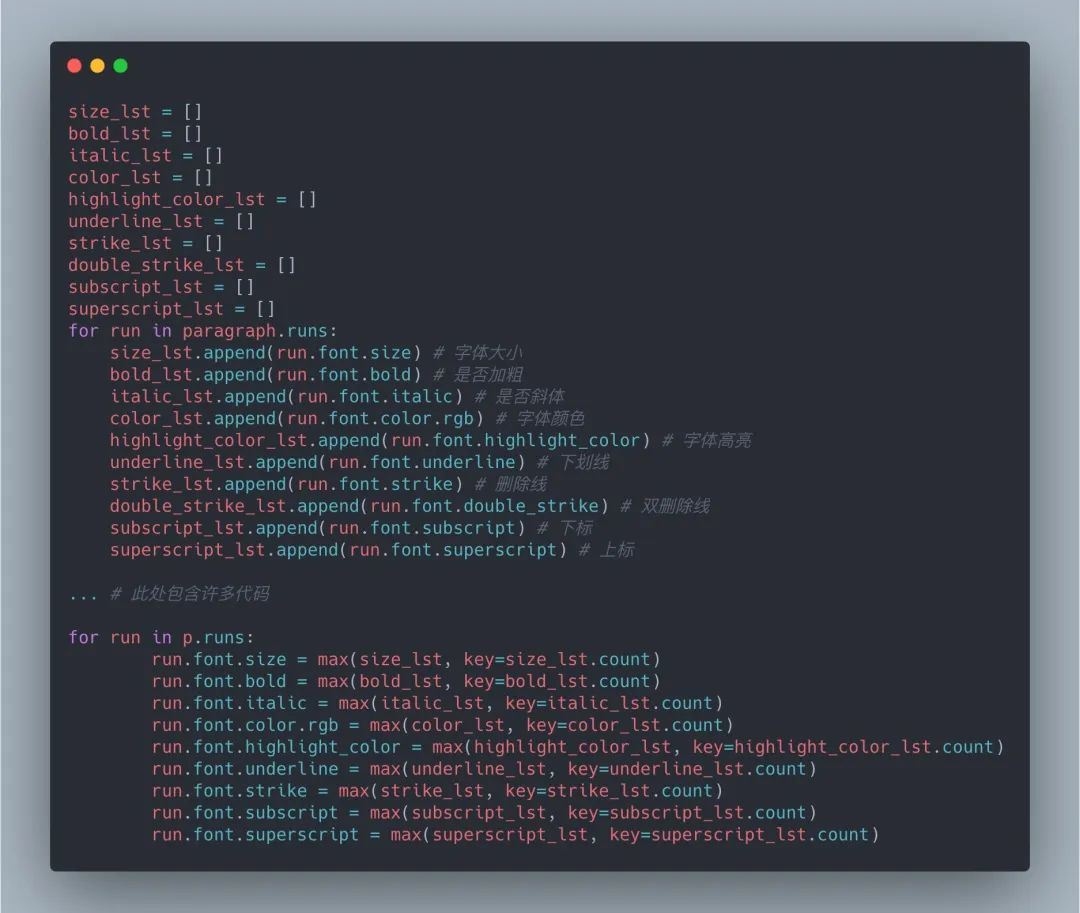
2.3 文字块样式修改
对于字号、加粗、斜体、颜色等样式调整,采取的策略是建立空列表,遍历原文档每一段每一个文字块,获取相应属性并放到各自的列表中,对同一段而言,其包含的文字块属性最多的选项赋值给翻译后文档的对应段落(如同一段全部或大部分的文字是加粗,则翻译后对应段落所有文字块均设置为加粗) 对NLP感兴趣的读者可自行尝试如何高度还原英文文档中某些特定词语的样式修改,并在翻译后的文档中体现出来
上面的代码不包含对字体的设置,因为没必要把英文的字体传递给中文文档。对中文字体的设置之前的文章有提到过,比较复杂,直接见代码:
from docx.oxml.ns import qn
run.font.name = '微软雅黑'
r = run._element.rPr.rFonts
r.set(qn('w:eastAsia'), '微软雅黑')
3. 整体实现步骤
现在每个部分操作均以完成,考虑到本例中有多个文档均需要翻译,故全部逻辑如下:
- 利用
glob模块批处理框架可获取某个文件的绝对路径 - 由
python-docx完成 Word 文件实例化后对段落进行解析 - 解析出的段落文本交给百度通用翻译 API,解析返回的 Json 格式结果(上面的修改 demo 中已经完成了这一步)并重新写入新的文件
- 同个文件全部解析、翻译并写入新文件后保存文件
三、代码实现
导入需要的模块,除翻译 demo 中需要的库外还需要 glob 库批量获取文件、python-docx 读取文件、time 模块控制访问并发。为什么要 os 模块见下文:
import requests import random import json from hashlib import md5 import time from docx import Document import glob import os
对原 demo 的部分内容进行保留,涉及到 query 参数的代码需要移动到后面的循环中。保留的部分:
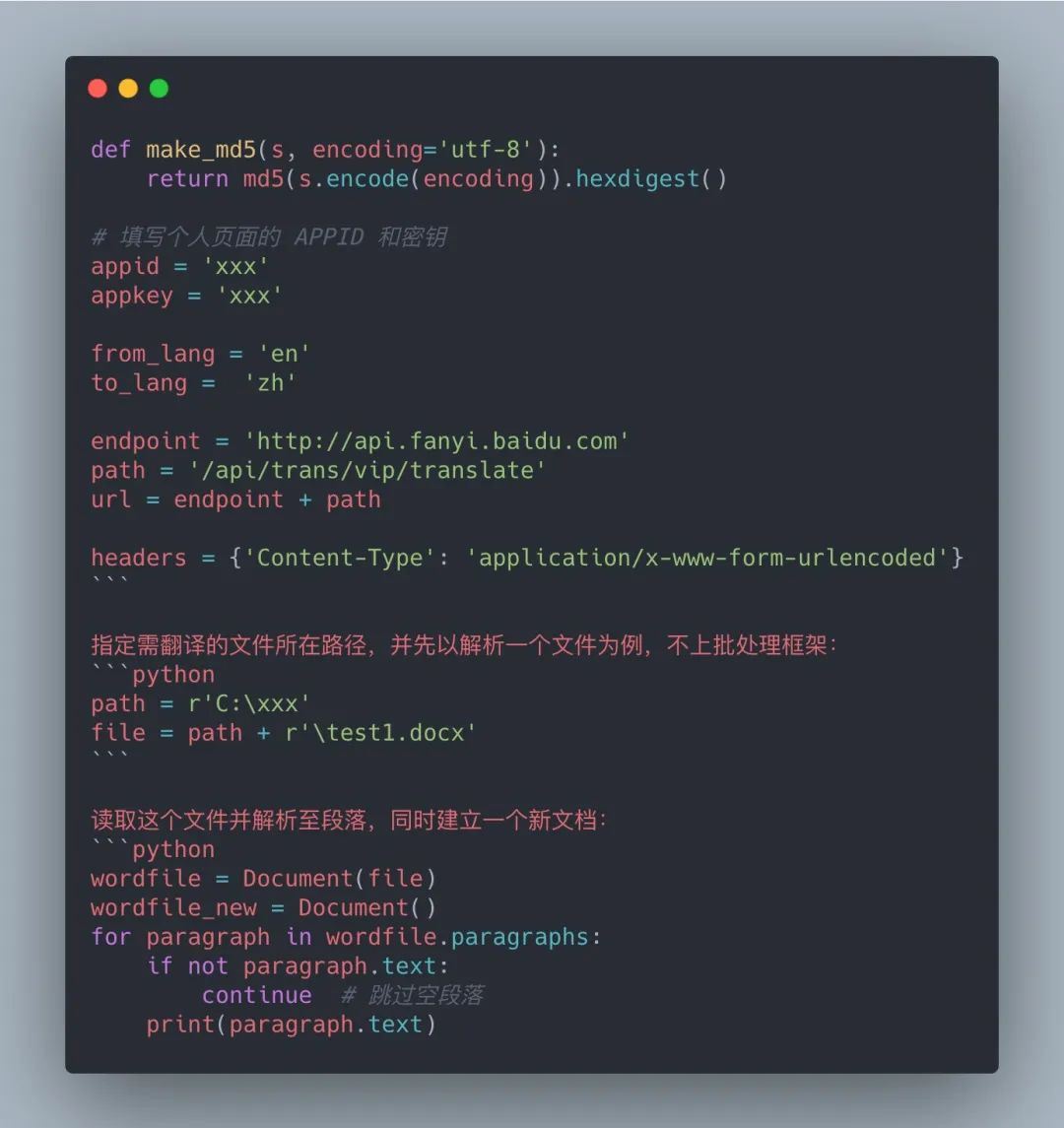
效果如下

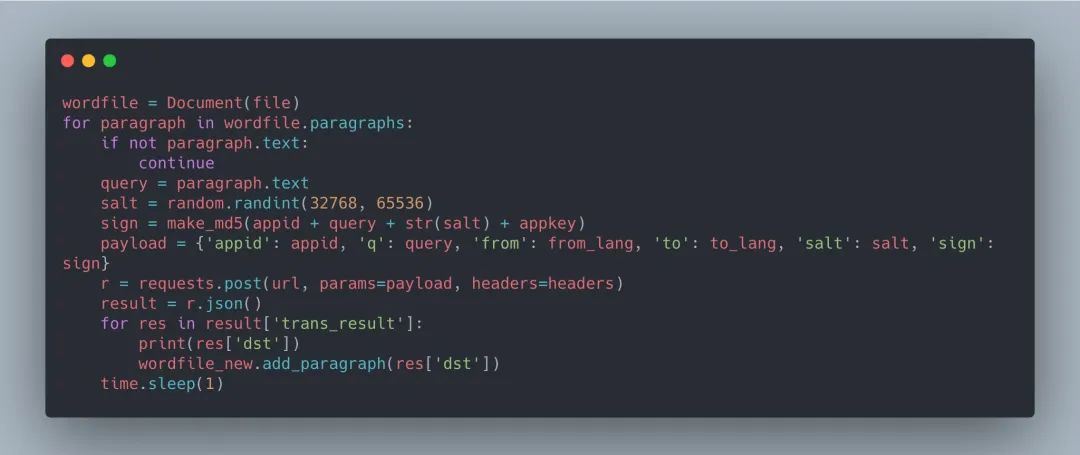
获取到段落文本后,可以将段落文本赋值给 query 参数,调用 API demo 的后续代码。输出结果的同时用 add_paragraph 将结果写入新文档:
最后保存成新文件,期望命名为 原文件名_translated 的形式,可用 os.path.basename 方法获取并经字符串拼接达到目的:
wordfile_new.save(path + r'\\' + os.path.basename(file)[:-5] + '_translated.docx')

单个文件操作完成后将读取和创建文件的代码块放到批处理框架内:
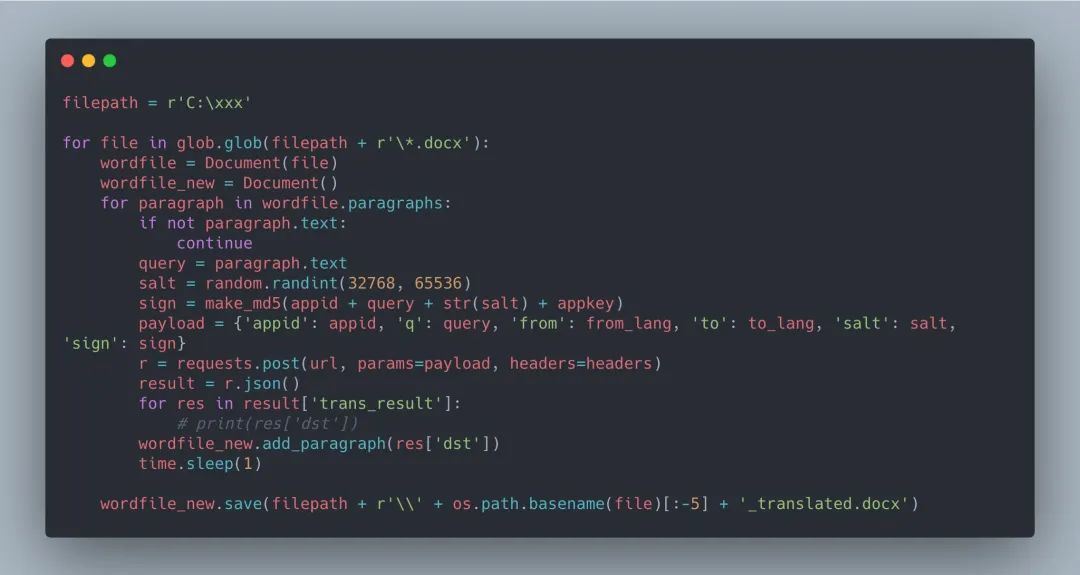
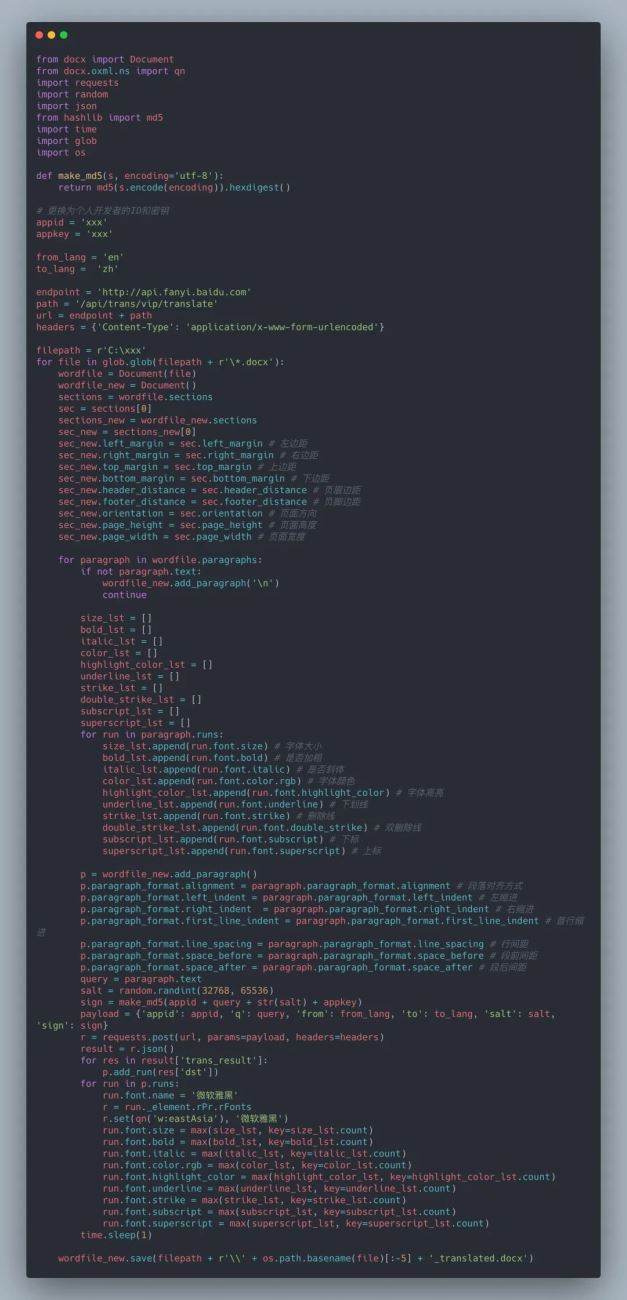
完成了上面的内容后,基本需求就完成了。根据我们梳理的对样式的修改知识,再把样式调整的代码加进来就行了,最终完整代码如下:
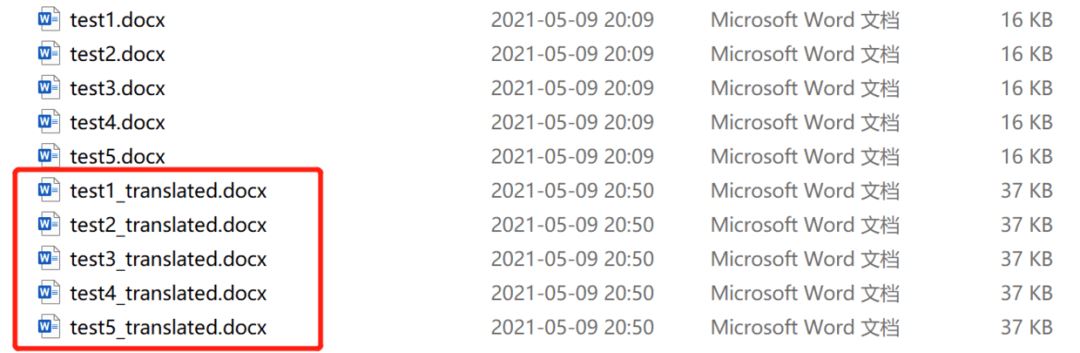
代码运行完毕后得到五个新的翻译后文件
翻译效果如下,可以看到英文被翻译成中文,并且样式大部分保留!

至此,所有文档都被成功翻译,当然这是机器翻译的,具体应用时还需要对关键部分进一步人工调整,不过整体来说还是一次成功的Python办公自动化尝试!
我已经将本文涉及的示例文档上传至GitHub,感兴趣的朋友可以通过连接获取
链接: http://pan.baidu.com/s/1StLIsZYNYpm54J7Er6dO1w 提取码: i8qu
加载全部内容