C语言 内存对齐和位段 C语言重难点之内存对齐和位段
快乐江湖 人气:0一:结构体内存对齐
(1)为什么要存在内存对齐
平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些平台只能在某些地址处取得某些特定类型的数据,否则抛出硬件异常。
比如,当一个平台要取一个整型数据时只能在地址为4的倍数的位置取得,那么这时就需要内存对齐,否则无法访问到该整型数据。
性能原因:
数据结构(尤其是栈)应该尽可能的在自然边界上对齐。原因在于,为了访问未对齐内存,处理器需要作两次内存访问;而对齐的内存访问仅需一次。
核心思想就是:以空间换取时间
struct s1
{
char c1;
int i;
char c2;
}
由于c1占1个字节,i占4个字节,c2占1个字节,所以计算机在读取时候,会先读取c1和i的3个字节(共四个字节)、再读取i的最后一个字节和c2。因此计算器不但需要进行两次内存读取,并且还需要对i的数据进行拼接,无形中浪费了运行的时间。所以为了减少时间的浪费,就采用了内存对齐的方式。
(2)结构体对齐规则
- 第一个成员在与结构体变量偏移量为0的地址处。(即结构体的首地址处,即对齐到0处)
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
- 结构体的总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
- 如果嵌套了结构体,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
其中对齐数=编译器默认的一个对齐数与该成员大小的较小值。vs中默认为8。Linux中默认值为4。
(3)结构体对齐演示
以下面的构体为例
struct S
{
double d;
char c;
int i;
};
第一步:把结构体中每个成员变量的大小与编译器的默认对齐数进行比较,取小的作为该成员的对齐数

第二步:从0位开始,画出这些成员的位置,注意对齐到自己的对齐数
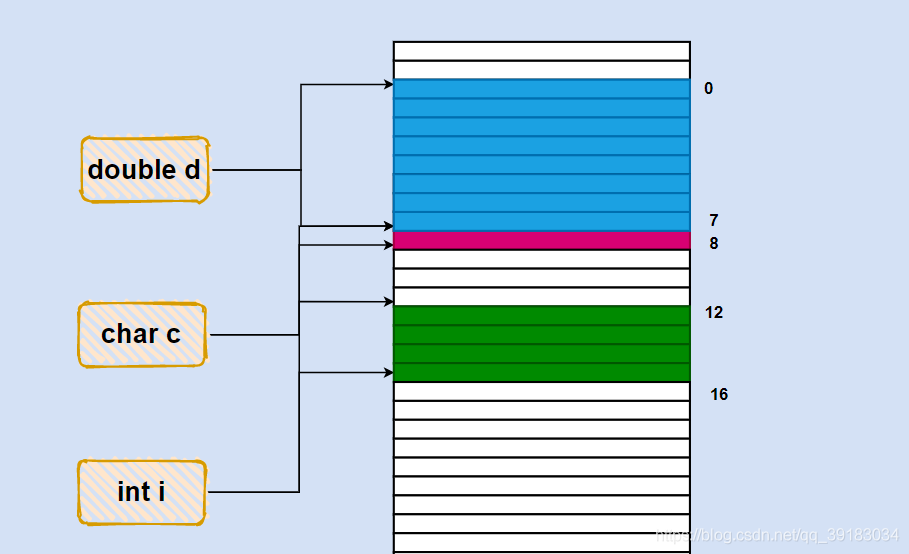
故为16个字节
(4)练习
//练习1
struct S1{
char c1;
int i;
char c2;
};
printf("%d\n", printf(struct S1);//12
//练习2
struct S2 {
char c1;
char c2;
int i;
};
printf("%d\n", sizeof(struct S2));//8
//练习3
struct S3 {
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));//16
//练习4-结构体嵌套问题
struct S4 {
char c1;
struct S3 s3;
double d;
};
printf("%d\n", sizeof(struct S4));//32
二:位段
(1)什么是位段
“节省空间”这四个字可以直截了当的点名位段的作用。
在结构体设计中,我们一般用int来存年龄这样的数据,但是年龄这个东西再大也不会达到几百几千,也就是它的范围一般是1-100,反应在整形数据的内存上,使用的可能就是32个比特位中的个别几个,也就说剩余的很多比特位就是根本不会用到的,而如果明知道这样,还要不管三七二十一直接抛出一个整形,四个字节,32个比特位存储这么小的数,未免显的有点浪费了。所以正式鉴于此,位段就能合理的进行内存设计
(2)位段怎么写
位段的基本格式如下,和结构体十分相似,其内部的数据类型一般要求是一致的
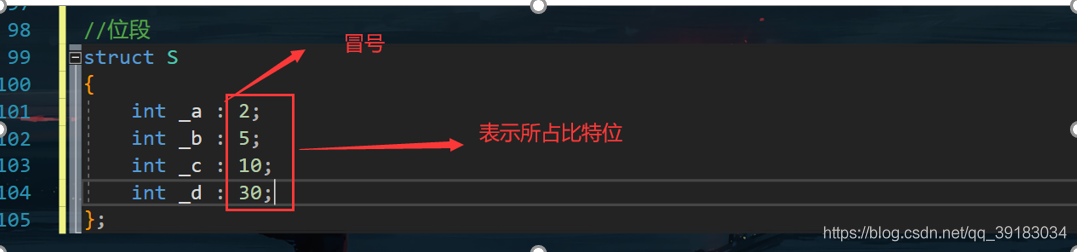
(3)位段结构体对齐怎么算
上述这个结构体所占空间大小为八个字节,在实际分配时,会一上来先分配四个字节,其中a,b,c占据2+5+10共17个比特位,剩余d需要30个比特位存储但是不够,所以再分配四个字节,拿出其中30个比特位存储。可以看出相比之前暴力的直接16个字节,现在的8个字节大大的节省了空间。
再比如下面位段
struct A
{
unsigned a : 19;
unsigned b : 11;
unsigned c : 4;
unsigned d : 29;
char index;
};
其中a和b共占据4个字节,c和d占据八个字节,index对齐对齐1个字节,最终就是16
位段的跨平台问题
- int 位段被当成有符号数还是无符号数是不确定的。
- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机
- 器会出问题。
- 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
加载全部内容