Java线程同步 Java多线程之线程同步
IT烂笔头 人气:0volatile
先看个例子
class Test {
// 定义一个全局变量
private boolean isRun = true;
// 从主线程调用发起
public void process() {
test();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
stop();
}
// 启动一个子线程循环读取isRun
private void test() {
new Thread(new Runnable() {
@Override
public void run() {
while (isRun) {
// 疑问,如果我这里有一些打印的语句或者线程睡眠的语句,子线程在
// 主线程将isRun改为false的时候,就会跳出死循环,反之,如果循环体
// 内是空的,就算在主线程改了isRun的值,也无法及时跳出循环,why?
// 当然,如果将isRun变量使用volatile修饰就没有此问题
}
}
}).start();
}
private void stop() {
isRun = false;
}
}
有一点是一定的,就是子线程访问isRun的时候会拷贝一份放到自己的线程(工作内存)里,这样在读写的时候可能就不会和外面isRun的值实时是匹配上的。所以就会出现意想不到的问题。
所以我们使用volatile修饰,这样当有多线程同时访问一个变量时,都会自动同步一下。显然这样会带来一定的性能损失,但是如果确实需要还是要这么做的。
但是,有一个问题来了,使用volatile一定能就可解决多线程同步的问题了吗?那我们看下面这个例子:
class TestSynchronize {
// 使用volatile修饰的变量
private volatile int x = 0;
private void add() {
x++;
}
public void test() {
// 启动第一个线程,进行100万次自加
new Thread(new Runnable() {
@Override
public void run() {
for (int i=0; i< 1_000_000; i++) {
add();
}
System.out.println("第一个线程x=" + x);
}
}).start();
// 启动第二个线程,进行100万次自加
new Thread(new Runnable() {
@Override
public void run() {
for (int i=0; i< 1_000_000; i++) {
add();
}
System.out.println("第二个线程x=" + x);
}
}).start();
}
}
我们希望的结果是,最后一个执行完的线程应该是在2_000_000,但是只要你实际测下就发现并不是这样,因为volatile只能保证可见性,但是只要涉及多线程我们一定还听说过原子性这个概念。什么是可见性:
可见性:对于多个线程都在访问的变量,当有个线程在修改的时候,它会保证会将修改的值更新到内存中,而不是只在工作线程中修改,这样当别的线程访问的时候也会去内存中取最新的值,这样就能保证访问到的值是最新的。
那什么又是原子性呢:
原子性:就是一个操作或者多个操作要么都执行,要么都不执行,不会存在执行一半会被打断。
在Java中,对基本数据类型变量的读取和赋值操作是原子性的。但是上述代码中的x++;显然不是原子操作,可以拆解为:
int temp = x + 1; x = temp;
那么这就为多线程操作带来不确定性,
1、开始x初始值为0,
2、当线程A调用add()函数时,执行到temp=x+1;这一行时被中断了,
3、此时切换到线程B的add()函数,线程B完整执行完两行代码后,x = 1了,
4、这个时候线程B又完整的执行了一遍add方法,那么x=2了,
5、此时发生了线程切换,切换到A执行,A接着上次的执行的语句,temp = 1了,接下来执行x = temp;语句将1赋值给了x。
可是本来x都被B线程加到2了,这下又回去了,经历A和B线程一共三次add()操作,结果x的值只是1。
这就解释了上面那段代码中,两个线程分别加了100万次后,结果最后一个执行完的线程打印的却并不是200万。原因就是add()里面的操作并不是原子性的,而volatile只能保证可见性,不能保证原子性
当然,仅针对上面的按理我们可以将int x = 0;换一种类型声明,比如使用AtomicInteger x = new AtomicInteger(0);然后将x++改成x.incrementAndGet();这样也能保证原子性,确保多线程操作后数据是符合期望的。
除了针对基本数据类型的,还有对引用操作原子化的,AtomicReference<V>
synchronized
当synchronized修饰一个方法时,那么同一时间只有一个线程可以访问此方法,如果有多个方法都被synchronized修饰的话,当一个线程访问了其中一个方法,别的线程就无法访问其他被synchronized修饰的方法。

相当于有一个监视器,当一个线程访问某个方法,其他线程想访问别的方法时,需要和同一个监视器做确认,这么做看起来不太合理,其实也是合理的,比如有两方法都可能对同一个变量做操作,两个线程能同时访问两个方法,这样数据还是会发生错乱。
当然,我们就有两个方法支持同步访问的场景的,只要我们自己确认两个方法不会存在数据上的错乱,我们可以为每个方法指定自己的监视器,在默认情况下是当前类的对象(this)。
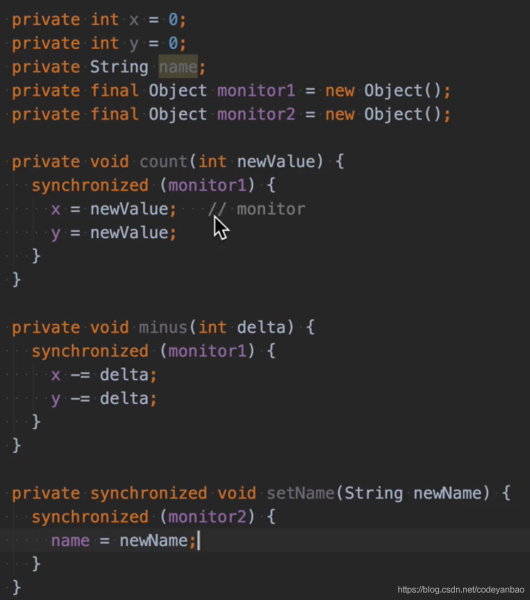
我们分别为setName();和其他两个方法指定了不同的monitor(监视器),这样当线程A访问上面两个方法的时候,线程B想访问方法setName也是不受影响的:
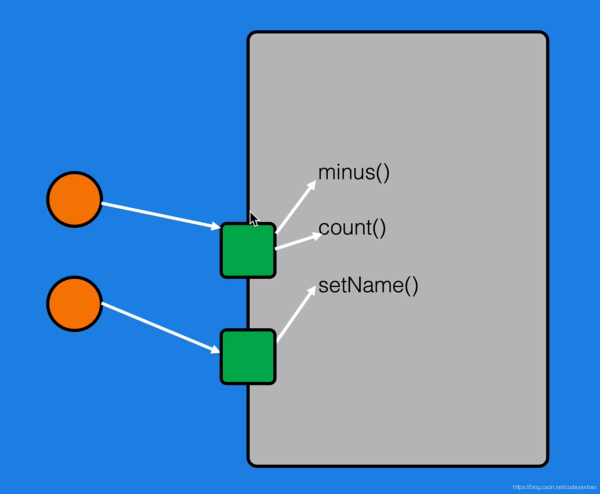
接下来我们看我们经常写的另一个例子,单例模式:
class TestInstance {
private TestInstance(){}
private static TestInstance sInstance;
public static TestInstance newInstance() {
**// ② 这里判空的目的?**
if (sInstance == null) {
**// ① 为什么锁加在这里?**
synchronized (TestInstance.class) {
**// ③ 这里判空的目的?**
if (sInstance == null) {
sInstance = new TestInstance();
}
}
}
return sInstance;
}
}
我们来依次搞清楚上面的三个问题,
①锁为什么加在里面而不是在方法上加锁,因为加锁后会带来性能上的损失的,单例对象只会创建一次,没必要在实例已经有的时候获取单例时还加锁,对性能是浪费。
②第一个判空的目的就是在已经创建过实例之后的获取操作,不用再经过synchronized判断,这样更快。
③最后一个判空就是防止多个线程都会调到创建实例的操作。
加载全部内容