Python chardet库 Python爬虫之必备chardet库
数据分析与统计学之美 人气:0想了解Python爬虫之必备chardet库的相关内容吗,数据分析与统计学之美在本文为您仔细讲解Python chardet库的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python,chardet库,python常用库,下面大家一起来学习吧。
一、chardet库的安装与介绍
玩儿过爬虫的朋友应该知道,在爬取不同的网页时,返回结果会出现乱码的情况。比如,在爬取某个中文网页的时候,有的页面使用GBK/GB2312,有的使用UTF8,如果你需要去爬一些页面,知道网页编码很重要的。
虽然HTML页面有charset标签,但是有些时候是不对的,那么chardet就能帮我们大忙了。使用 chardet 可以很方便的实现字符串/文件的编码检测。
如果你安装过Anaconda,那么可以直接使用chardet库。如果你只是安装了Python的话,就需要使用下面几行代码,完成chardet库的安装。
pip install chardet
接着,使用下面这行代码,导入chardet库。
import chardet
二、chardet库的使用
这个小节,我们分3部分讲解。
2.1 chardet.detect()函数
detect()函数接受一个参数,一个非unicode字符串。它返回一个字典,其中包含自动检测到的字符编码和从0到1的可信度级别。
- encoding:表示字符编码方式。
- confidence:表示可信度。
- language:语言。
光看这个解释,大多数朋友可能看不懂,下面我们就用例子来讲述这个函数。
2.2 使用该函数分别检测gbk、utf-8和日语
检测gbk编码的中文:
str1 = '大家好,我是黄同学'.encode('gbk')
chardet.detect(str1)
chardet.detect(str1)["encoding"]
结果如下:

检测的编码是GB2312,注意到GBK是GB2312的父集,两者是同一种编码,检测正确的概率是99%,language字段指出的语言是'Chinese'。
检测utf-8编码的中文:
str2 = '我有一个梦想'.encode('utf-8')
chardet.detect(str2)
chardet.detect(str2)["encoding"]
结果如下:

检测一段日文:
str3 = 'ありがとう'.encode('euc-jp')
chardet.detect(str3)
chardet.detect(str3)
结果如下:

2.3 如何在“爬虫”中使用chardet库呢?
我们以百度网页为例子,进行讲述。

这个网页的源代码,使用的是什么编码呢?我们看看源代码:

从图中可以看到,是utf-8字符编码。
如果不使用chardet库,获取网页源代码的时候,怎么指定字符编码呢?
import chardet
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get('https://www.baidu.com',headers=headers)
response.encoding = "utf-8"
response.text
结果如下:

你会发现:正确指定编码后,没有乱码。如果你将编码改为gbk,再看看结果。此时已经乱码。
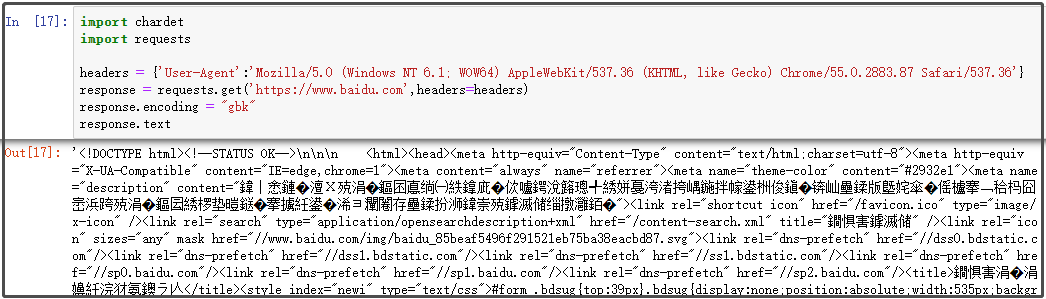
如果使用chardet库,获取网页源代码的时候,可以轻松指定字符编码!
import chardet
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get('https://www.baidu.com',headers=headers)
# 注意下面这行代码,是怎么写的?
response.encoding = chardet.detect(response.content)['encoding']
response.text
结果如下:

编码不用我们自己查找,也不用猜,直接交给chardet库去猜测,正确率还高。
加载全部内容