django rest framework serializers django rest framework serializers序列化实例
asamm 人气:0serializers是将复杂的数据结构变成json或者xml这个格式的
serializers有以下几个作用:
- 将queryset与model实例等进行序列化,转化成json格式,返回给用户(api接口)。
- 将post与patch/put的上来的数据进行验证。
- 对post与patch/put数据进行处理。
实现序列化二个类:Serializer与ModelSerializer 比较
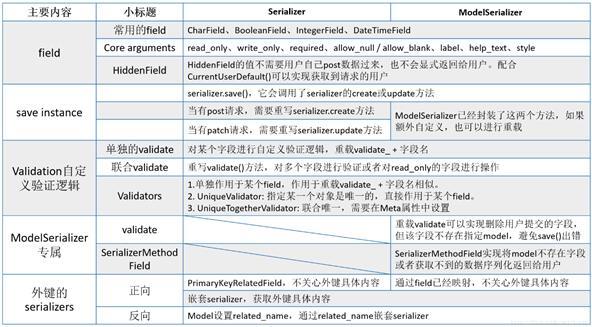
ModelSerializer(Serializer) 即 ModelSerializer继承了Serializer的相关功能,是对model实现序列化的封装
一、serializers.fieild
我们知道在django中,form也有许多field,那serializers其实也是drf中发挥着这样的功能。我们先简单了解常用的几个field。
1. 常用的field
CharField、BooleanField、IntegerField、DateTimeField这几个用得比较多
# 举例子 mobile = serializers.CharField(max_length=11, min_length=11) age = serializers.IntegerField(min_value=1, max_value=100) # format可以设置时间的格式,下面例子会输出如:2018-1-24 12:10 pay_time = serializers.DateTimeField(read_only=True,format='%Y-%m-%d %H:%M') is_hot = serializers.BooleanField()
serializer的field不仅在进行数据验证时起着至关重要的作用,在将数据进行序列化后返回也发挥着重要作用
2. Core arguments参数
read_only:True表示不允许用户自己上传,只能用于api的输出。如果某个字段设置了read_only=True,那么就不需要进行数据验证,只会在返回时,将这个字段序列化后返回
举个简单的例子:在用户进行购物的时候,用户post订单时,肯定会产生一个订单号,而这个订单号应该由后台逻辑完成,而不应该由用户post过来,如果不设置read_only=True,那么验证的时候就会报错。
order_sn = serializers.CharField(readonly=True)
write_only: 与read_only对应
required: 顾名思义,就是这个字段是否必填。
allow_null/allow_blank:是否允许为NULL/空 。
error_messages:出错时,信息提示。
name = serializers.CharField(required=True, min_length=6,
error_messages={
'min_length': '名字不能小于6个字符',
'required': '请填写名字'})
label: 字段显示设置,如 label='验证码'
help_text: 在指定字段增加一些提示文字,这两个字段作用于api页面比较有用
style: 说明字段的类型,这样看可能比较抽象,看下面例子:
# 在api页面,输入密码就会以*显示
password = serializers.CharField(
style={'input_type': 'password'})
# 会显示选项框
color_channel = serializers.ChoiceField(
choices=['red', 'green', 'blue'],
style={'base_template': 'radio.html'})
3. HiddenField
HiddenField的值不依靠输入,而需要设置默认的值,不需要用户自己post数据过来,也不会显式返回给用户,最常用的就是user!!
我们在登录情况下,进行一些操作,假设一个用户去收藏了某一门课,那么后台应该自动识别这个用户,然后用户只需要将课程的id post过来,那么这样的功能,我们配合CurrentUserDefault()实现。
# 这样就可以直接获取到当前用户 user = serializers.HiddenField( default=serializers.CurrentUserDefault())
二、save instance
save instance这是为post和patch所设置的。
post请求对应create方法,而patch请求对应update方法,这里提到的create方法与update方法,是指mixins中特定类中的方法。
我们看一下源代码:
# 只截取一部分
class CreateModelMixin(object):
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
headers = self.get_success_headers(serializer.data)
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def perform_create(self, serializer):
serializer.save()
class UpdateModelMixin(object):
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(serializer.data)
def perform_update(self, serializer):
serializer.save()
可以看出,无论是create与update都写了一行:serializer.save( ),那么,这一行,到底做了什么事情,分析一下源码。
# serializer.py def save(self, **kwargs): # 略去一些稍微无关的内容 ··· if self.instance is not None: self.instance = self.update(self.instance, validated_data) ··· else: self.instance = self.create(validated_data) ··· return self.instance
显然,serializer.save的操作,它去调用了serializer的create或update方法,不是mixins中的!!!我们看一下流程图(以post为例)
讲了那么多,我们到底需要干什么!重载这两个方法!!
如果你的viewset含有post,那么你需要重载create方法,如果含有patch,那么就需要重载update方法。
# 假设现在是个博客,有一个创建文章,与修改文章的功能, model为Article。
class ArticleSerializer(serializers.Serializer):
user = serializers.HiddenField(
default=serializers.CurrentUserDefault())
name = serializers.CharField(max_length=20)
content = serializers.CharField()
def create(self, validated_data):
# 除了用户,其他数据可以从validated_data这个字典中获取
# 注意,users在这里是放在上下文中的request,而不是直接的request
user = self.context['request'].user
name = validated_data['name ']
content = validated_data['content ']
return Article.objects.create(**validated_data)
def update(self, instance, validated_data):
# 更新的特别之处在于你已经获取到了这个对象instance
instance.name = validated_data.get('name')
instance.content = validated_data.get('content')
instance.save()
return instance
可能会有人好奇,系统是怎么知道,我们需要调用serializer的create方法,还是update方法,我们从save( )方法可以看出,判断的依据是:
if self.instance is not None:pass
那么我们的mixins的create与update也已经在为开发者设置好了
# CreateModelMixin serializer = self.get_serializer(data=request.data) # UpdateModelMixin serializer = self.get_serializer(instance, data=request.data, partial=partial)
也就是说,在update通过get_object( )的方法获取到了instance,然后传递给serializer,serializer再根据是否有传递instance来判断来调用哪个方法!
三、Validation自定义验证逻辑
1、单独的validate
在上面提到field,它能起到一定的验证作用,但很明显,它存在很大的局限性,举个简单的例子,我们要判断我们手机号码,如果使用CharField(max_length=11, min_length=11),它只能确保我们输入的是11个字符,那么我们需要自定义!
mobile_phone = serializers.CharField(max_length=11, min_length=11)
def validate_mobile_phone(self, mobile_phone):
# 注意参数,self以及字段名
# 注意函数名写法,validate_ + 字段名字
if not re.match(REGEX_MOBILE, mobile):
# REGEX_MOBILE表示手机的正则表达式
raise serializers.ValidationError("手机号码非法")
return mobile_phone
当然,这里面还可以加入很多逻辑,例如,还可以判断手机是否原本就存在数据库等等。
2、联合validate
上面验证方式,只能验证一个字段,如果是两个字段联合在一起进行验证,那么我们就可以重载validate( )方法。
start = serializers.DateTimeField()
finish = serializers.DateTimeField()
def validate(self, attrs):
# 传进来什么参数,就返回什么参数,一般情况下用attrs
if data['start'] > data['finish']:
raise serializers.ValidationError("finish must occur after start")
return attrs
这个方法非常的有用,我们还可以再这里对一些read_only的字段进行操作,我们在read_only提及到一个例子,订单号的生成,我们可以在这步生成一个订单号,然后添加到attrs这个字典中。
order_sn = serializers.CharField(readonly=True) def validate(self, attrs): # 调用一个方法生成order_sn attrs['order_sn'] = generate_order_sn() return attrs
这个方法运用在modelserializer中,可以剔除掉write_only的字段,这个字段只验证,但不存在与指定的model当中,即不能save( ),可以在这delete掉!
3、Validators
validators可以直接作用于某个字段,这个时候,它与单独的validate作用差不多
def multiple_of_ten(value):
if value % 10 != 0:
raise serializers.ValidationError('Not a multiple of ten')
class GameRecord(serializers.Serializer):
score = IntegerField(validators=[multiple_of_ten])
当然,drf提供的validators还有很好的功能:UniqueValidator,UniqueTogetherValidator等
UniqueValidator: 指定某一个对象是唯一的,如,用户名只能存在唯一:
username = serializers.CharField( max_length=11, min_length=11, validators=[UniqueValidator(queryset=UserProfile.objects.all()) )
UniqueTogetherValidator: 联合唯一,如用户收藏某个课程,这个时候就不能单独作用于某个字段,我们在Meta中设置。
class Meta:
validators = [
UniqueTogetherValidator(
queryset=UserFav.objects.all(),
fields=('user', 'course'),
message='已经收藏'
)]
四、ModelSerializer
讲了很多Serializer的,在这个时候,我还是强烈建议使用ModelSerializer,因为在大多数情况下,我们都是基于model字段去开发。
好处:
ModelSerializer已经重载了create与update方法,它能够满足将post或patch上来的数据进行进行直接地创建与更新,除非有额外需求,那么就可以重载create与update方法。
ModelSerializer在Meta中设置fields字段,系统会自动进行映射,省去每个字段再写一个field。
class UserDetailSerializer(serializers.ModelSerializer):
"""
用户详情序列化
"""
class Meta:
model = User
fields = ("name", "gender", "birthday", "email", "mobile")
# fields = '__all__': 表示所有字段
# exclude = ('add_time',): 除去指定的某些字段
# 这三种方式,存在一个即可
ModelSerializer需要解决的2个问题:
1,某个字段不属于指定model,它是write_only,需要用户传进来,但我们不能对它进行save( ),因为ModelSerializer是基于Model,这个字段在Model中没有对应,这个时候,我们需要重载validate!
如在用户注册时,我们需要填写验证码,这个验证码只需要验证,不需要保存到用户这个Model中:
def validate(self, attrs): del attrs["code"] return attrs
2,某个字段不属于指定model,它是read_only,只需要将它序列化传递给用户,但是在这个model中,没有这个字段!我们需要用到SerializerMethodField。
假设需要返回用户加入这个网站多久了,不可能维持这样加入的天数这样一个数据,一般会记录用户加入的时间点,然后当用户获取这个数据,我们再计算返回给它。
class UserSerializer(serializers.ModelSerializer): days_since_joined = serializers.SerializerMethodField() # 方法写法:get_ + 字段 def get_days_since_joined(self, obj): # obj指这个model的对象 return (now() - obj.date_joined).days class Meta: model = User
这个的SerializerMethodField用法还相对简单一点,后面还会有比较复杂的情况。
关于外键的serializers
讲了那么多,终于要研究一下外键啦~
其实,外键的field也比较简单,如果我们直接使用serializers.Serializer,那么直接用PrimaryKeyRelatedField就解决了。
假设现在有一门课python入门教学(course),它的类别是python(catogory)。
# 指定queryset
category = serializers.PrimaryKeyRelatedField(queryset=CourseCategory.objects.all(), required=True)
ModelSerializer就更简单了,直接通过映射就好了
不过这样只是用户获得的只是一个外键类别的id,并不能获取到详细的信息,如果想要获取到具体信息,那需要嵌套serializer
category = CourseCategorySerializer()
注意:上面两种方式,外键都是正向取得,下面介绍怎么反向去取,如,我们需要获取python这个类别下,有什么课程。
首先,在课程course的model中,需要在外键中设置related_name
class Course(model.Model): category = models.ForeignKey(CourseCategory, related_name='courses') # 反向取课程,通过related_name # 一对多,一个类别下有多个课程,一定要设定many=True courses = CourseSerializer(many=True)
有一个小问题:我们在上面提到ModelSerializer需要解决的第二个问题中,其实还有一种情况,就是某个字段属于指定model,但不能获取到相关数据。
假设现在是一个多级分类的课程,例如,编程语言–>python–>python入门学习课程,编程语言与python属于类别,另外一个属于课程,编程语言类别是python类别的一个外键,而且属于同一个model,实现方法:
parent_category = models.ForeignKey('self', null=True, blank=True,
verbose_name='父类目别',
related_name='sub_cat')
现在获取编程语言下的课程,显然无法直接获取到python入门学习这个课程,因为它们两没有外键关系。SerializerMethodField( )也可以解决这个问题,只要在自定义的方法中实现相关的逻辑即可!
courses = SerializerMethodField()
def get_courses(self, obj):
all_courses = Course.objects.filter(category__parent_category_id=obj.id)
courses_serializer = CourseSerializer(all_course, many=True,
context={'request': self.context['request']})
return courses_serializer.data
上面的例子看起来有点奇怪,因为我们在SerializerMethodField()嵌套了serializer,就需要自己进行序列化,然后再从data就可以取出json数据。
可以看到传递的参数是分别是:queryset,many=True多个对象,context上下文。这个context十分关键,如果不将request传递给它,在序列化的时候,图片与文件这些Field不会再前面加上域名,也就是说,只会有/media/img…这样的路径!
以上这篇django rest framework serializers序列化实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容