keras h5 load_weights,load keras读取h5文件load_weights、load代码操作
CVer_holic 人气:1关于保存h5模型、权重网上的示例非常多,也非常简单。主要有以下两个函数:
1、keras.models.load_model() 读取网络、权重
2、keras.models.load_weights() 仅读取权重
load_model代码包含load_weights的代码,区别在于load_weights时需要先有网络、并且load_weights需要将权重数据写入到对应网络层的tensor中。
下面以resnet50加载h5权重为例,示例代码如下
import keras from keras.preprocessing import image import numpy as np from network.resnet50 import ResNet50 #修改过,不加载权重(默认官方加载亦可) model = ResNet50() # 参数默认 by_name = Fasle, 否则只读取匹配的权重 # 这里h5的层和权重文件中层名是对应的(除input层) model.load_weights(r'\models\resnet50_weights_tf_dim_ordering_tf_kernels_v2.h5')
模型通过 model.summary()输出

一、模型加载权重 load_weights()
def load_weights(self, filepath, by_name=False, skip_mismatch=False, reshape=False):
if h5py is None:
raise ImportError('`load_weights` requires h5py.')
with h5py.File(filepath, mode='r') as f:
if 'layer_names' not in f.attrs and 'model_weights' in f:
f = f['model_weights']
if by_name:
saving.load_weights_from_hdf5_group_by_name(
f, self.layers, skip_mismatch=skip_mismatch,reshape=reshape)
else:
saving.load_weights_from_hdf5_group(f, self.layers, reshape=reshape)
这里关心函数saving.load_weights_from_hdf5_group(f, self.layers, reshape=reshape)即可,参数 f 传递了一个h5py文件对象。
读取h5文件使用 h5py 包,简单使用HDFView看一下resnet50的权重文件。
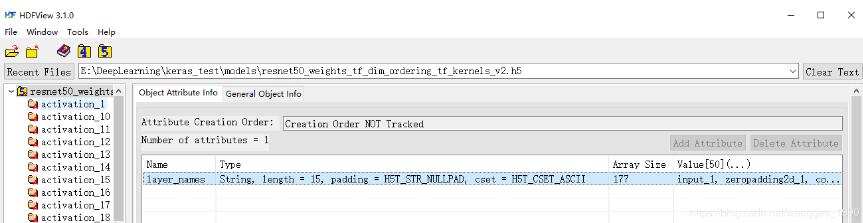
resnet50_v2 这个权重文件,仅一个attr “layer_names”, 该attr包含177个string的Array,Array中每个元素就是层的名字(这里是严格对应在keras进行保存权重时网络中每一层的name值,且层的顺序也严格对应)。
对于每一个key(层名),都有一个属性"weights_names",(value值可能为空)。
例如:
conv1的"weights_names"有"conv1_W:0"和"conv1_b:0",
flatten_1的"weights_names"为null。
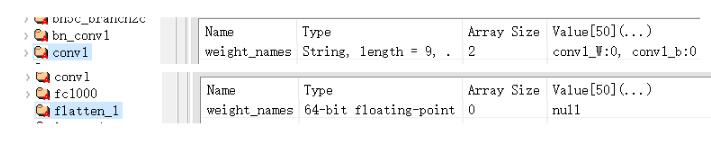
这里就简单介绍,后面在代码中说明h5py如何读取权重数据。
二、从hdf5文件中加载权重 load_weights_from_hdf5_group()
1、找出keras模型层中具有weight的Tensor(tf.Variable)的层
def load_weights_from_hdf5_group(f, layers, reshape=False): # keras模型resnet50的model.layers的过滤 # 仅保留layer.weights不为空的层,过滤掉无学习参数的层 filtered_layers = [] for layer in layers: weights = layer.weights if weights: filtered_layers.append(layer)
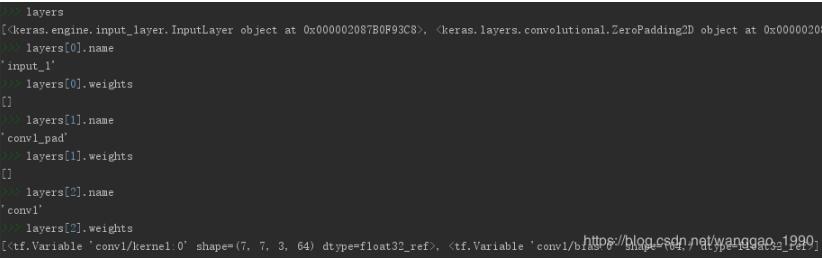
filtered_layers为当前模型resnet50过滤(input、paddind、activation、merge/add、flastten等)层后剩下107层的list
2、从hdf5文件中获取包含权重数据的层的名字
前面通过HDFView看过每一层有一个[“weight_names”]属性,如果不为空,就说明该层存在权重数据。
先看一下控制台对h5py对象f的基本操作(需要的去查看相关数据结构定义):
>>> f <HDF5 file "resnet50_weights_tf_dim_ordering_tf_kernels_v2.h5" (mode r)> >>> f.filename 'E:\\DeepLearning\\keras_test\\models\\resnet50_weights_tf_dim_ordering_tf_kernels_v2.h5' >>> f.name '/' >>> f.attrs.keys() # f属性列表 # <KeysViewHDF5 ['layer_names']> >>> f.keys() #无顺序 <KeysViewHDF5 ['activation_1', 'activation_10', 'activation_11', 'activation_12', ...,'activation_8', 'activation_9', 'avg_pool', 'bn2a_branch1', 'bn2a_branch2a', ...,'res5c_branch2a', 'res5c_branch2b', 'res5c_branch2c', 'zeropadding2d_1']> >>> f.attrs['layer_names'] #*** 有顺序, 和summary()对应 **** array([b'input_1', b'zeropadding2d_1', b'conv1', b'bn_conv1', b'activation_1', b'maxpooling2d_1', b'res2a_branch2a', ..., b'res2a_branch1', b'bn2a_branch2c', b'bn2a_branch1', b'merge_1', b'activation_47', b'res5c_branch2b', b'bn5c_branch2b', ..., b'activation_48', b'res5c_branch2c', b'bn5c_branch2c', b'merge_16', b'activation_49', b'avg_pool', b'flatten_1', b'fc1000'], dtype='|S15') >>> f['input_1'] <HDF5 group "/input_1" (0 members)> >>> f['input_1'].attrs.keys() # 在keras中,每一个层都有‘weight_names'属性 # <KeysViewHDF5 ['weight_names']> >>> f['input_1'].attrs['weight_names'] # input层无权重 # array([], dtype=float64) >>> f['conv1'] <HDF5 group "/conv1" (2 members)> >>> f['conv1'].attrs.keys() <KeysViewHDF5 ['weight_names']> >>> f['conv1'].attrs['weight_names'] # conv层有权重w、b # array([b'conv1_W:0', b'conv1_b:0'], dtype='|S9')
从文件中读取具有权重数据的层的名字列表
# 获取后hdf5文本文件中层的名字,顺序对应
layer_names = load_attributes_from_hdf5_group(f, 'layer_names')
#上一句实现 layer_names = [n.decode('utf8') for n in f.attrs['layer_names']]
filtered_layer_names = []
for name in layer_names:
g = f[name]
weight_names = load_attributes_from_hdf5_group(g, 'weight_names')
#上一句实现 weight_names = [n.decode('utf8') for n in f[name].attrs['weight_names']]
#保留有权重层的名字
if weight_names:
filtered_layer_names.append(name)
layer_names = filtered_layer_names
# 验证模型中有有权重tensor的层 与 从h5中读取有权重层名字的 数量 保持一致。
if len(layer_names) != len(filtered_layers):
raise ValueError('You are trying to load a weight file '
'containing ' + str(len(layer_names)) +
' layers into a model with ' +
str(len(filtered_layers)) + ' layers.')
3、从hdf5文件中读取的权重数据、和keras模型层tf.Variable打包对应
先看一下权重数据、层的权重变量(Tensor tf.Variable)对象,以conv1为例
>>> f['conv1']['conv1_W:0'] # conv1_W:0 权重数据数据集 <HDF5 dataset "conv1_W:0": shape (7, 7, 3, 64), type "<f4"> >>> f['conv1']['conv1_W:0'].value # conv1_W:0 权重数据的值, 是一个标准的4d array array([[[[ 2.82526277e-02, -1.18737184e-02, 1.51488732e-03, ..., -1.07003953e-02, -5.27982824e-02, -1.36667420e-03], [ 5.86827798e-03, 5.04415408e-02, 3.46324709e-03, ..., 1.01423981e-02, 1.39493728e-02, 1.67549420e-02], [-2.44090753e-03, -4.86173332e-02, 2.69966386e-03, ..., -3.44439060e-04, 3.48098315e-02, 6.28910400e-03]], [[ 1.81872323e-02, -7.20698107e-03, 4.80302610e-03, ..., …. ]]]]) >>> conv1_w = np.asarray(f['conv1']['conv1_W:0']) # 直接转换成numpy格式 >>> conv1_w.shape (7, 7, 3, 64) # 卷积层 >>> filtered_layers[0] <keras.layers.convolutional.Conv2D object at 0x000001F7487C0E10> >>> filtered_layers[0].name 'conv1' >>> filtered_layers[0].input <tf.Tensor 'conv1_pad/Pad:0' shape=(?, 230, 230, 3) dtype=float32> #卷积层权重数据 >>> filtered_layers[0].weights [<tf.Variable 'conv1/kernel:0' shape=(7, 7, 3, 64) dtype=float32_ref>, <tf.Variable 'conv1/bias:0' shape=(64,) dtype=float32_ref>]
将模型权重数据变量Tensor(tf.Variable)、读取的权重数据打包对应,便于后续将数据写入到权重变量中.
weight_value_tuples = []
# 枚举过滤后的层
for k, name in enumerate(layer_names):
g = f[name]
weight_names = load_attributes_from_hdf5_group(g, 'weight_names')
# 获取文件中当前层的权重数据list, 数据类型转换为numpy array
weight_values = [np.asarray(g[weight_name]) for weight_name in weight_names]
# 获取keras模型中层具有的权重数据tf.Variable个数
layer = filtered_layers[k]
symbolic_weights = layer.weights
# 权重数据预处理
weight_values = preprocess_weights_for_loading(layer, weight_values,
original_keras_version, original_backend,reshape=reshape)
# 验证权重数据、tf.Variable数据是否相同
if len(weight_values) != len(symbolic_weights):
raise ValueError('Layer #' + str(k) + '(named "' + layer.name +
'" in the current model) was found to correspond to layer ' + name +
' in the save file. However the new layer ' + layer.name + ' expects ' +
str(len(symbolic_weights)) + 'weights, but the saved weights have ' +
str(len(weight_values)) + ' elements.')
# tf.Variable 和 权重数据 打包
weight_value_tuples += zip(symbolic_weights, weight_values)
4、将读取的权重数据写入到层的权重变量中
在3中已经对应好每一层的权重变量Tensor和权重数据,后面将使用tensorflow的sess.run方法进新写入,后面一行代码。
K.batch_set_value(weight_value_tuples)
实际实现
def batch_set_value(tuples):
if tuples:
assign_ops = []
feed_dict = {}
for x, value in tuples:
# 获取权重数据类型
value = np.asarray(value, dtype=dtype(x))
tf_dtype = tf.as_dtype(x.dtype.name.split('_')[0])
if hasattr(x, '_assign_placeholder'):
assign_placeholder = x._assign_placeholder
assign_op = x._assign_op
else:
# 权重的tf.placeholder
assign_placeholder = tf.placeholder(tf_dtype, shape=value.shape)
# 对权重变量Tensor的赋值 assign的operation
assign_op = x.assign(assign_placeholder)
x._assign_placeholder = assign_placeholder # 用处?
x._assign_op = assign_op # 用处?
assign_ops.append(assign_op)
feed_dict[assign_placeholder] = value
# 利用tensorflow的tf.Session().run()对tensor进行assign批次赋值
get_session().run(assign_ops, feed_dict=feed_dict)
至此,先有网络模型,后从h5中加载权重文件结束。后面就可以直接利用模型进行predict了。
三、模型加载 load_model()
这里基本和前面类似,多了一个加载网络而已,后面的权重加载方式一样。
首先将前面加载权重的模型使用 model.save()保存为res50_model.h5,使用HDFView查看
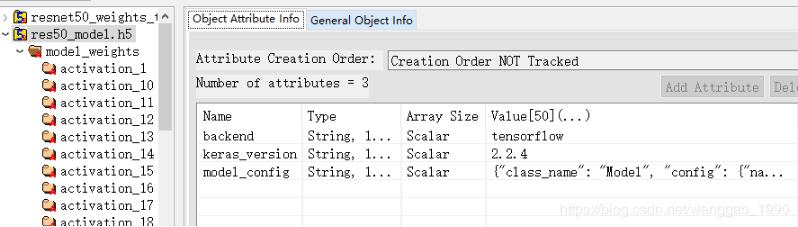
属性成了3个,backend, keras_version和model_config,用于说明模型文件由某种后端生成,后端版本,以及json格式的网络模型结构。
有一个key键"model_weights", 相较于属性有前面的h5模型,属性多了2个为['backend', 'keras_version', 'layer_names'] 该key键下面的键值是一个list, 和前面的h5模型的权重数据完全一致。
类似的,先利用python代码查看下文件结构
>>> ff <HDF5 file "res50_model.h5" (mode r)> >>> ff.attrs.keys() <KeysViewHDF5 ['backend', 'keras_version', 'model_config']> >>> ff.keys() <KeysViewHDF5 ['model_weights']> >>> ff['model_weights'].attrs.keys() ## ff['model_weights']有三个属性 <KeysViewHDF5 ['backend', 'keras_version', 'layer_names']> >>> ff['model_weights'].keys() ## 无顺序 <KeysViewHDF5 ['activation_1', 'activation_10', 'activation_11', 'activation_12', …, 'avg_pool', 'bn2a_branch1', 'bn2a_branch2a', 'bn2a_branch2b', …, 'bn5c_branch2c', 'bn_conv1', 'conv1', 'conv1_pad', 'fc1000', 'input_1', …, 'c_branch2a', 'res5c_branch2b', 'res5c_branch2c']> >>> ff['model_weights'].attrs['layer_names'] ## 有顺序 array([b'input_1', b'conv1_pad', b'conv1', b'bn_conv1', b'activation_1', b'pool1_pad', b'max_pooling2d_1', b'res2a_branch2a', b'bn2a_branch2a', b'activation_2', b'res2a_branch2b', ... 省略 b'activation_48', b'res5c_branch2c', b'bn5c_branch2c', b'add_16', b'activation_49', b'avg_pool', b'fc1000'], dtype='|S15')
1、加载模型主函数load_model
def load_model(filepath, custom_objects=None, compile=True):
if h5py is None:
raise ImportError('`load_model` requires h5py.')
model = None
opened_new_file = not isinstance(filepath, h5py.Group)
# h5加载后转换为一个 h5dict 类,编译通过键取值
f = h5dict(filepath, 'r')
try:
# 序列化并compile
model = _deserialize_model(f, custom_objects, compile)
finally:
if opened_new_file:
f.close()
return model
2、序列化并编译_deserialize_model
函数def _deserialize_model(f, custom_objects=None, compile=True)的代码显示主要部分
第一步,加载网络结构,实现完全同keras.models.model_from_json()
# 从h5中读取网络结构的json描述字符串
model_config = f['model_config']
model_config = json.loads(model_config.decode('utf-8'))
# 根据json构建网络模型结构
model = model_from_config(model_config, custom_objects=custom_objects)
第二步,加载网络权重,完全同model.load_weights()
# 获取有顺序的网络层名, 网络层 model_weights_group = f['model_weights'] layer_names = model_weights_group['layer_names'] layers = model.layers # 过滤 有权重Tensor的层 for layer in layers: weights = layer.weights if weights: filtered_layers.append(layer) # 过滤有权重的数据 filtered_layer_names = [] for name in layer_names: layer_weights = model_weights_group[name] weight_names = layer_weights['weight_names'] if weight_names: filtered_layer_names.append(name) # 打包数据 weight_value_tuples weight_value_tuples = [] for k, name in enumerate(layer_names): layer_weights = model_weights_group[name] weight_names = layer_weights['weight_names'] weight_values = [layer_weights[weight_name] for weight_name in weight_names] layer = filtered_layers[k] symbolic_weights = layer.weights weight_values = preprocess_weights_for_loading(...) weight_value_tuples += zip(symbolic_weights, weight_values) # 批写入 K.batch_set_value(weight_value_tuples)
第三步,compile并返回模型
正常情况,模型网路建立、加载权重后 compile之后就完成。若还有其他设置,则可以再进行额外的处理。(模型训练后save会有额外是参数设置)。
例如,一个只有dense层的网路训练保存后查看,属性多了"training_config",键多了"optimizer_weights",如下图。
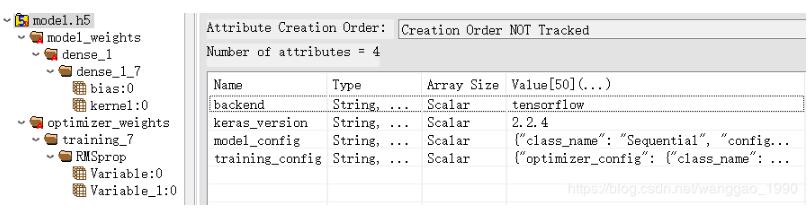
当前res50_model.h5没有额外的参数设置。
处理代码如下
if compile:
training_config = f.get('training_config')
if training_config is None:
warnings.warn('No training configuration found in save file: '
'the model was *not* compiled. Compile it manually.')
return model
training_config = json.loads(training_config.decode('utf-8'))
optimizer_config = training_config['optimizer_config']
optimizer = optimizers.deserialize(optimizer_config, custom_objects=custom_objects)
# Recover loss functions and metrics.
loss = convert_custom_objects(training_config['loss'])
metrics = convert_custom_objects(training_config['metrics'])
sample_weight_mode = training_config['sample_weight_mode']
loss_weights = training_config['loss_weights']
# Compile model.
model.compile(optimizer=optimizer, loss=loss, metrics=metrics,
loss_weights=loss_weights, sample_weight_mode=sample_weight_mode)
# Set optimizer weights.
if 'optimizer_weights' in f:
# Build train function (to get weight updates).
model._make_train_function()
optimizer_weights_group = f['optimizer_weights']
optimizer_weight_names = [
n.decode('utf8') for n in ptimizer_weights_group['weight_names']]
optimizer_weight_values = [
optimizer_weights_group[n] for n in optimizer_weight_names]
try:
model.optimizer.set_weights(optimizer_weight_values)
except ValueError:
warnings.warn('Error in loading the saved optimizer state. As a result,'
'your model is starting with a freshly initialized optimizer.')
以上这篇keras读取h5文件load_weights、load代码操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容