R语言数据框负索引 R语言数据框中的负索引介绍
易水潇潇vc 人气:0想了解R语言数据框中的负索引介绍的相关内容吗,易水潇潇vc在本文为您仔细讲解R语言数据框负索引的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:R语言,数据框,负索引,索引,下面大家一起来学习吧。
以R语言自带的mtcars数据框为例:
这是原始的mtcars数据:

这里只列出了前面几行数据。
然后负索引mtcars[,-2:-3],得到的结果
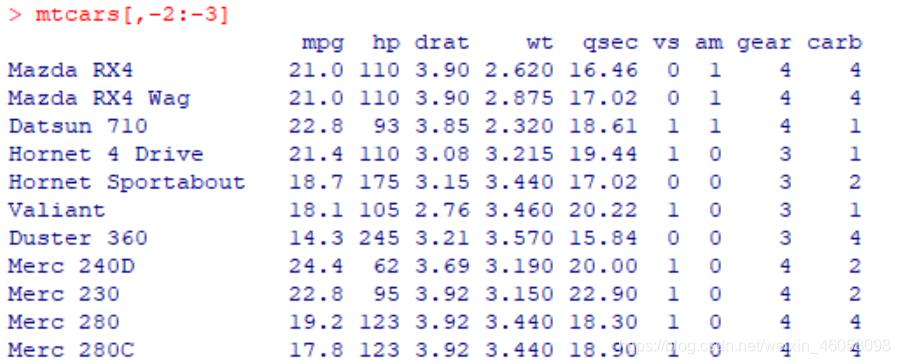
删除了第二列和第三列数据
所以R语言数据框中的负索引是指删除数据框中对应的列(或者行)
ps:这和Python里面的规则好像不太一样,Python里的负索引好像是指倒数第几列(或者第几行),这里这两个软件区别还挺大的~~写个笔记提醒一下自己~
补充:R语言中的负整数索引
看代码吧~
> x<-matrix(c(1,2,3,4,5,6,7,8,9),nrow = 3,ncol = 3,byrow = TRUE)
> x
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> x[-1,]
[,1] [,2] [,3]
[1,] 4 5 6
[2,] 7 8 9
这在R中称为负整数索引向量,这种索引向量指定被排除的元素而不是包括进来,因此x[-1,]表示取出矩阵x的除了第一行元素外的其他元素。
补充:R语言-基本语法、数据类型及索引
1. 基本语法
print() 、cat()打印输出
#单行注释
if(FALSE){code block}多行注释
2. 数据类型
class():查看数据类型
2.1 基本数据类型
| 基本数据类型 | 示例 |
|---|---|
| 逻辑值(logical) | 真:TRUE、T,假:FALSE、F |
| 数字(numeric) | 123、5 |
| 整型(integer) | 2L、34L |
| 复数(complex) | 3+2i |
| 字符(character) | 'good' |
2.2 向量Vector
c()函数创建向量。
注意:必须保证元素类型相同,否则会默认进行类型转换。
> x <- c(1, 2)
> class(x)
[1] "numeric"
> x <- c('s')
> class(x)
[1] "character"
> x <- c(1, 2, 's')
> class(x)
[1] "character"
2.3 列表List
列表可以包含许多不同类型的元素,如向量、函数、嵌套列表。
注意:[]与[[]]的区别。[]取出来的仍是一个列表,[[]]取出来的是本身的数据类型。
> list1 <- list(c(2,3), 21, 's', sin) # 分别包含列表、数字、字符、函数
> class(list1)
[1] "list"
> list1[1] # 取出来的仍是一个列表
[[1]]
[1] 2 3
> list1[[1]] # 取出来的是子列表中的元素
[1] 2 3
> class(list1[1])
[1] "list"
> class(list1[[1]])
[1] "numeric"
> list1[[2]]
[1] 21
> list1[2] + 2
Error in list1[2] + 2 : non-numeric argument to binary operator
> list1[[2]] + 2
[1] 23
> list1[[4]]
function (x) .Primitive("sin")
> class(list1[[4]])
[1] "function"
2.4 矩阵Matrix
矩阵是二维数据集,它可以使用矩阵函数的向量输入创建。
byrow参数决定元素存放的顺序。
> M <- matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
> M
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"
> M[,1] # 取出第一列数据
[1] "a" "c"
> M[1,] # 取出第一行数据
[1] "a" "a" "b"
> M[2,1] # 取出单个元素
[1] "c"
2.5 数组Array
利用数组可以创建任意维度的数据。
> array1 <- array(c('green','yellow'), dim=c(3,3,2))
> array1
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"
2.6 因子Factor
因子是使用向量创建的对象。它将向量与向量中元素的不同值一起存储为标签。 标签是字符类型。 它们在统计建模中非常有用。
使用factor()函数创建因子。nlevels函数给出级别计数。
> apple_colors <- c('green','green','yellow','red','red','red','green')
> factor_apple <- factor(apple_colors)
> factor_apple
[1] green green yellow red red red green
Levels: green red yellow
> nlevels(factor_apple)
[1] 3
2.7 数据框Data Frame
表格数据对象。每列可以包含不同的数据类型。 第一列可以是数字,而第二列可以是字符,第三列可以是逻辑的。 它是等长度的向量的列表。
使用data.frame()函数创建数据框。
# 创建数据框,表格对象
> BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
> BMI
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26
# 获取第二列
> BMI[2]
height
1 152.0
2 171.5
3 165.0
# 获取第一行
> BMI[1,]
gender height weight Age
1 Male 152 81 42
# 获取第一列数据,类型为DataFrame
> BMI[1]
gender
1 Male
2 Male
3 Female
> class(BMI[1])
[1] "data.frame"
# 获取第一列,并将其转换为factor类型
> BMI[,1]
[1] Male Male Female
Levels: Female Male
# 获取第一个元素,转换为factor类型
> BMI[1,1]
[1] Male
Levels: Female Male
# 获取第二列,不改变数据类型
> BMI[2]
height
1 152.0
2 171.5
3 165.0
# 获取第二列,改变数据类型
> BMI[,2]
[1] 152.0 171.5 165.0
# 根据列的名称获取factor类型数据
data_frame$col_name
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
加载全部内容