python 自动下载图片 python自动下载图片的方法示例
^_^影 人气:0近日闲来无事,总有一种无形的力量萦绕在朕身边,让朕精神涣散,昏昏欲睡。

可是,像朕这么有职业操守的社畜怎么能在上班期间睡瞌睡呢,我不禁陷入了沉思。。。。

突然旁边的IOS同事问:‘嘿,兄弟,我发现一个网站的图片很有意思啊,能不能帮我保存下来提升我的开发灵感?'
作为一个坚强的社畜怎么能说自己不行呢,当时朕就不假思索的答应:‘oh, It's simple. Wait for me a few minute.'

点开同事给的图片网站,
网站大概长这样:
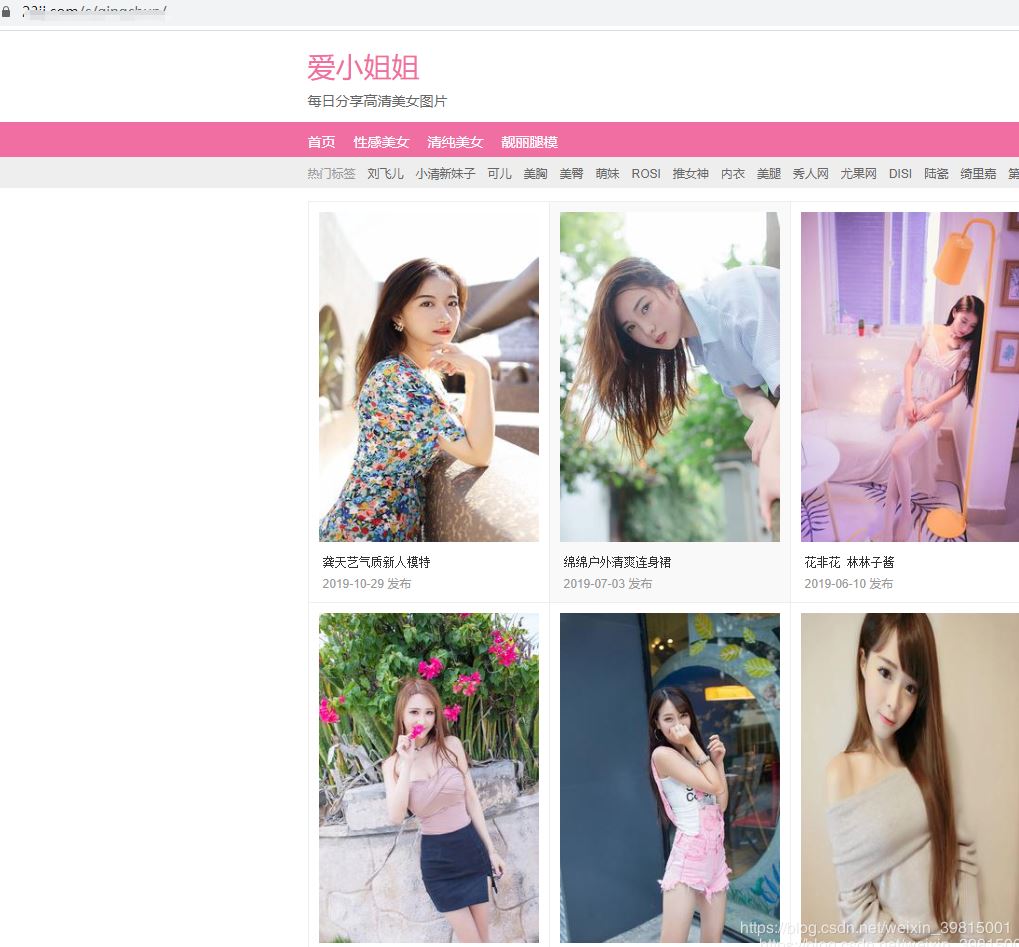
在朕翻看了几十页之后,朕突然觉得有点上头。心中一想'不对啊,朕不是来学习的吗?可是看美女图片这个事情怎么才可以和学习关联起来呢‘

冥思苦想一番之后,突然脑中灵光一闪,'要不用python写个爬虫吧,将此网站的图片一网打尽‘。

说干就干,身体力行,要问爬虫哪家强,‘人生苦短,我用python'。
首先找到我的电脑里面半年前下载的python安装包,无情的点击了安装,环境装好之后,略一分析网页结构。先撸一个简易版爬虫
#抓取爱小姐姐网图片保存到本地
import requests
from lxml import etree as et
import os
#请求头
headers = {
#用户代理
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
#待抓取网页基地址
base_url = ''
#保存图片基本路径
base_dir = 'D:/python/code/aixjj/'
#保存图片
def savePic(pic_url):
#如果目录不存在,则新建
if not os.path.exists(base_dir):
os.makedirs(base_dir)
arr = pic_url.split('/')
file_name = base_dir+arr[-2]+arr[-1]
print(file_name)
#获取图片内容
response = requests.get(pic_url, headers = headers)
#写入图片
with open(file_name,'wb') as fp:
for data in response.iter_content(128):
fp.write(data)
#观察此网站总共只有62页,所以循环62次
for k in range(1,63):
#请求页面地址
url = base_url+str(k)
response = requests.get(url = url, headers = headers)
#请求状态码
code = response.status_code
if code == 200:
html = et.HTML(response.text)
#获取页面所有图片地址
r = html.xpath('//li/a/img/@src')
#获取下一页url
#t = html.xpath('//div[@class="page"]/a[@class="ch"]/@href')[-1]
for pic_url in r:
a = 'http:'+pic_url
savePic(a)
print('第%d页图片下载完成' % (k))
print('The End!')
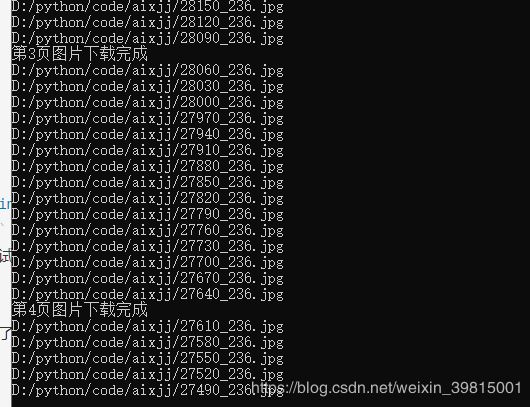
尝试运行爬虫,嘿,没想到行了:

过了一会儿,旁边的哥们儿又来:‘嘿 bro 你这个可以是可以,就是速度太慢了啊,我的灵感会被长时间的等待磨灭,你给改进改进?'

怎么提升爬虫的效率呢?略一思索,公司的电脑可是伟大的四核CPU啊,要不撸个多进程版本试试。然后就产生了下面这个多进程版本
#多进程版——抓取爱小姐姐网图片保存到本地
import requests
from lxml import etree as et
import os
import time
from multiprocessing import Pool
#请求头
headers = {
#用户代理
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
#待抓取网页基地址
base_url = ''
#保存图片基本路径
base_dir = 'D:/python/code/aixjj1/'
#保存图片
def savePic(pic_url):
#如果目录不存在,则新建
if not os.path.exists(base_dir):
os.makedirs(base_dir)
arr = pic_url.split('/')
file_name = base_dir+arr[-2]+arr[-1]
print(file_name)
#获取图片内容
response = requests.get(pic_url, headers = headers)
#写入图片
with open(file_name,'wb') as fp:
for data in response.iter_content(128):
fp.write(data)
def geturl(url):
#请求页面地址
#url = base_url+str(k)
response = requests.get(url = url, headers = headers)
#请求状态码
code = response.status_code
if code == 200:
html = et.HTML(response.text)
#获取页面所有图片地址
r = html.xpath('//li/a/img/@src')
#获取下一页url
#t = html.xpath('//div[@class="page"]/a[@class="ch"]/@href')[-1]
for pic_url in r:
a = 'http:'+pic_url
savePic(a)
if __name__ == '__main__':
#获取要爬取的链接列表
url_list = [base_url+format(i) for i in range(1,100)]
a1 = time.time()
#利用进程池方式创建进程,默认创建进程数量=电脑核数
#自己定义进程数量方式 pool = Pool(4)
pool = Pool()
pool.map(geturl,url_list)
pool.close()
pool.join()
b1 = time.time()
print('运行时间:',b1-a1)
抱着试一试的心态,运行了多进程版本爬虫,嘿没想到又行了,在朕伟大的四核CPU的加持下,爬虫速度提升了3~4倍。
又过了一会儿,那哥们儿又偏过头来:‘你这个快是快了不少,但是还不是最理想的状态,能不能一眨眼就能爬取百八十个图片,毕竟我的灵感来的快去的也快'
我:‘…'
悄悄打开Google,搜索如何提升爬虫效率,给出结论:
多进程:密集CPU任务,需要充分使用多核CPU资源(服务器,大量的并行计算)的时候,用多进程。
多线程:密集I/O任务(网络I/O,磁盘I/O,数据库I/O)使用多线程合适。
呵,我这可不就是I/O密集任务吗,赶紧写一个多线程版爬虫先。于是,又诞生了第三款:
import threading # 导入threading模块
from queue import Queue #导入queue模块
import time #导入time模块
import requests
import os
from lxml import etree as et
#请求头
headers = {
#用户代理
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
#待抓取网页基地址
base_url = ''
#保存图片基本路径
base_dir = 'D:/python/code/aixjj/'
#保存图片
def savePic(pic_url):
#如果目录不存在,则新建
if not os.path.exists(base_dir):
os.makedirs(base_dir)
arr = pic_url.split('/')
file_name = base_dir+arr[-2]+arr[-1]
print(file_name)
#获取图片内容
response = requests.get(pic_url, headers = headers)
#写入图片
with open(file_name,'wb') as fp:
for data in response.iter_content(128):
fp.write(data)
# 爬取文章详情页
def get_detail_html(detail_url_list, id):
while True:
url = detail_url_list.get() #Queue队列的get方法用于从队列中提取元素
response = requests.get(url = url, headers = headers)
#请求状态码
code = response.status_code
if code == 200:
html = et.HTML(response.text)
#获取页面所有图片地址
r = html.xpath('//li/a/img/@src')
#获取下一页url
#t = html.xpath('//div[@class="page"]/a[@class="ch"]/@href')[-1]
for pic_url in r:
a = 'http:'+pic_url
savePic(a)
# 爬取文章列表页
def get_detail_url(queue):
for i in range(1,100):
#time.sleep(1) # 延时1s,模拟比爬取文章详情要快
#Queue队列的put方法用于向Queue队列中放置元素,由于Queue是先进先出队列,所以先被Put的URL也就会被先get出来。
page_url = base_url+format(i)
queue.put(page_url)
print("put page url {id} end".format(id = page_url))#打印出得到了哪些文章的url
#主函数
if __name__ == "__main__":
detail_url_queue = Queue(maxsize=1000) #用Queue构造一个大小为1000的线程安全的先进先出队列
#A线程负责抓取列表url
thread = threading.Thread(target=get_detail_url, args=(detail_url_queue,))
html_thread= []
#另外创建三个线程负责抓取图片
for i in range(20):
thread2 = threading.Thread(target=get_detail_html, args=(detail_url_queue,i))
html_thread.append(thread2)#B C D 线程抓取文章详情
start_time = time.time()
# 启动四个线程
thread.start()
for i in range(20):
html_thread[i].start()
# 等待所有线程结束,thread.join()函数代表子线程完成之前,其父进程一直处于阻塞状态。
thread.join()
for i in range(20):
html_thread[i].join()
print("last time: {} s".format(time.time()-start_time))#等ABCD四个线程都结束后,在主进程中计算总爬取时间。
粗略测试一下,得出结论: ‘Oh my god,这也太快了吧'。
将多线程版本爬虫扔到同事QQ头像的脸上,并附文:‘拿去,速滚'
加载全部内容