汇编语言 跳转指令 汇编语言 跳转指令与C语言的条件分支
无欲则刚 人气:0跳转指令
跳转指令也是一个组的指令,称为j组。其中jmp为无条件跳转,其余为条件跳转

上图为j组指令,可结合条件码访问指令加深理解
在机器指令水平上理解如何对跳转指令编码

- 如上图,通过反汇编软件得到机器指令与汇编语言,其中左边为机器指令编码,右边为对应汇编语言含义,最左边为每条机器指令地址
- jmp指令的对应机器指令有两个字节:eb表示这是jmp指令,03描述跳转信息。值得注意的是,跳转指令进行编码时,采用相对位置编码,如03描述的就是偏移量
- 结合实例进行理解:在未执行jmp指令时,rip寄存器存储的地址为4004d5(rip寄存器存放即将加载的指令地址);执行jmp指令后,rip寄存器的值改为新的目标位置地址,目标位置=原先位置+偏移量,在此例子中为4004d5+03=4004d8。jg指令同理
- 存放相对位置意义:可获得更高灵活度,若存放绝对地址,分配地址可能改变;而相对位置一定不変
使用汇编语言的跳转指令实现C语言的条件分支

如上图,左边的程序可以通过上边的指令翻译成汇编指令
对上边指令的理解:
- control.c为输入的文件
- -s表示把c语言程序翻译为汇编指令
- -og是一种程序优化形式。这种形式优化程度较低,但是是在不改变程序原有结构的前提下进行优化,故而能更加清楚的看到程序语言和汇编语言间的关系。在实际应用中,-o1、-o2优化程度更高,能更大程度提高程序性能,尤其-o2已经成为当前的主流标准。但是这两种形式可能改变原有高级语言的语句结构,难以建立高级语言和汇编指令间的映射关系,故在学习中不采用
- -fno-if-conversion告诉编译器,在编译时,不要把分支语句用条件传输指令去执行,而用跳转指令执行。在早期X86处理器中,分支语句只又跳转指令表示,但后来又加入了条件传输指令,现在许多处理器用条件传输指令表示分支语句
使用条件数据传输指令实现条件分支
- 条件数据传输指令,先计算条件结果,然后根据条件结果的具体状态,来决定是否把原操作数的值赋值到目标操作数
- 和传统mov指令相似,只不过相当于在mov指令前需要判断条件,若条件不符合要求,啥都不做;符合要求,进行赋值
- 既然已经有了跳转指令,为何要引入条件数据传输指令:跳转指令存在性能问题。处理器体系结构中有流水线技术,可实现对于指令执行的加速。但流水线须执行对指令的预先读取,预读的通常策略是顺序取址。若遇到跳转指令,无法事先判断是否进行跳转,导致跳转指令对流水线指令的预取有破坏意义。尽管流水线做了大量工作来避免破坏性(如分支预测),但无论如何弥补,都可能导致程序性能下降。而条件数据传输指令会预先将条件计算出来,然后判断是否进行赋值(即赋值指令是否执行),从而避免了对流水线的破坏。尽管增加了计算量,但对流水线性能优化要高于计算性能的代价
结合实例
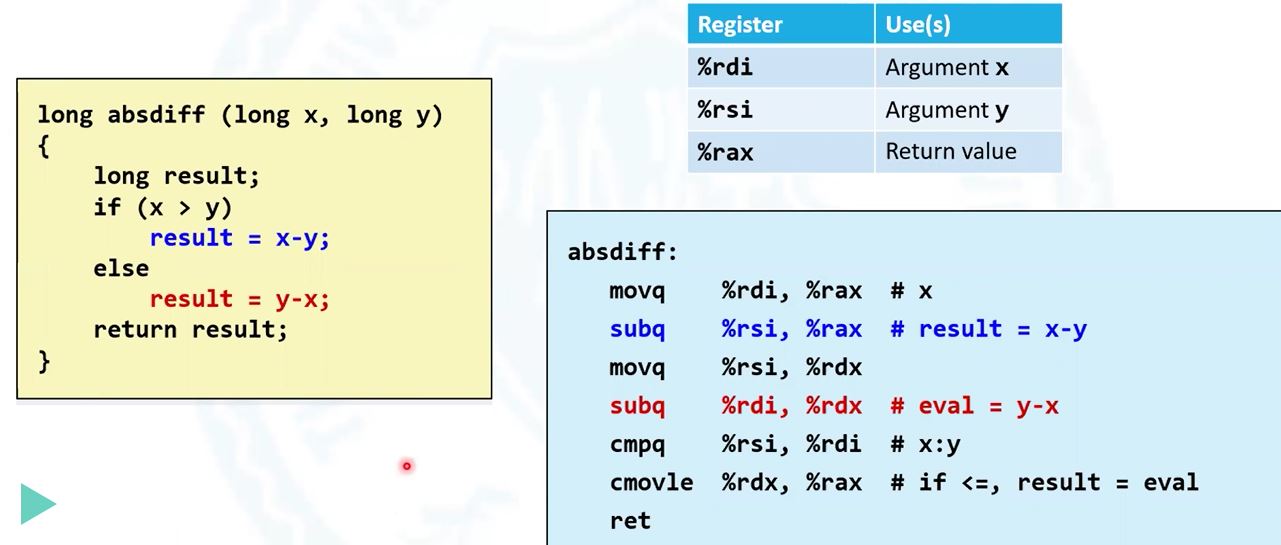
指令就是跳转指令去掉-fno-if-conversion
条件数据传输指令过程:
把一种情况的结果(x-y)先计算出来,放到rax寄存器;另一种同样计算出来,放到rdx寄存器;然后比较x与y大小
比较大小时用到cmov指令组,与set指令组类似。如cmovle是在小于等于的情况下,将rdx赋值给rax;大于则保持原状。
条件数据传输指令可对性能进行很好的优化,但不是所有条件数据分支都可用条件语句表达,如下图

分支语句块中包含非常重的计算,导致计算开销远大于对流水线性能的优化
具有一些临界风险情况。如取p指针指向地址的值的操作,必须在p不为0前提下进行。而条件数据传输指令会先将两个结果计算出来,再做取舍。此时若p指针不存在,会报错
计算中可能出现副作用,即使用变量互相间有关联。两种结果均会对x进行更新,若使用条件数据传输指令先计算结果的话,会使x值变化,与原逻辑不符
加载全部内容