集成spring data elasticsearch Springboot集成spring data elasticsearch过程详解
滚动的蛋 人气:0版本对照
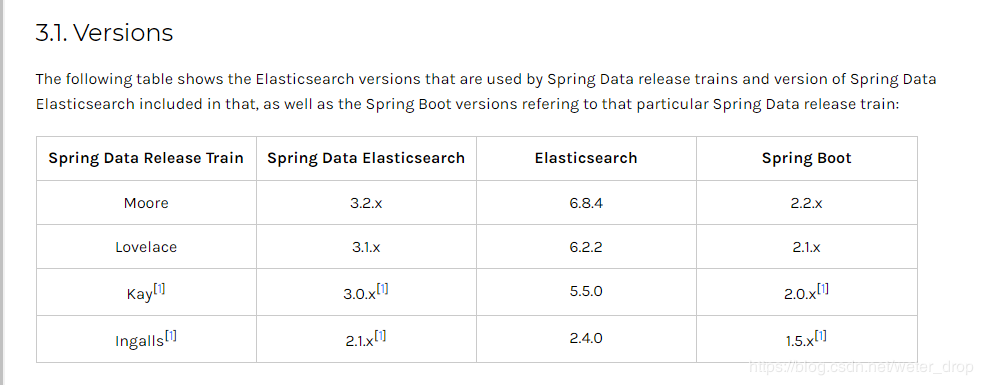
各版本的文档说明:https://docs.spring.io/spring-data/elasticsearch/docs/
1、在application.yml中添加配置
spring:
data:
elasticsearch:
repositories:
enabled: true
#多实例集群扩展时需要配置以下两个参数
#cluster-name: datab-search
#cluster-nodes: 127.0.0.1:9300,127.0.0.1:9301
2、添加 Maven 依赖
<!---开箱即用,版本默认和springboot版本对应-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3、建立实体entity
注解说明:
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
- @Document 作用在类,标记实体类为文档对象,一般有两个属性
- indexName:对应索引库名称
- type:对应在索引库中的类型
- shards:分片数量,默认5
- replicas:副本数量,默认1
- @Id 作用在成员变量,标记一个字段作为id主键
- @Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
- type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
- text:存储数据时候,会自动分词,并生成索引
- keyword:存储数据时候,不会分词建立索引
- Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
- Date:日期类型
- elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称,这里的ik_max_word即使用ik分词器
示例:
@Document(indexName = "cp_doc", type = "doc", shards = 10, replicas = 0)
public class CpDocument extends BaseEntity {
@Id//作用在成员变量,标记一个字段作为id主键
private long id ;
@Field(type = FieldType.Text)
private String name ;
@Field(type = FieldType.Text)
private String address ;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
4、编写 Repository 访问层
/**
* 基本操作repository-curd
* @author 滚动的蛋
*
*/
public interface CpRepository extends ElasticsearchRepository<CpDocument, Integer> {
}
5、创建索引+查询示例
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticSearchTest {
@Autowired
CpRepository cpRepository;
@Autowired
ElasticsearchTemplate elsTemplate;//ElasticsearchTemplate中提供了创建索引的API<br data-filtered="filtered"><br data-filtered="filtered">
@Test
public void addIndexTest() {
//创建索引
boolean indexRes = elsTemplate.createIndex(CpDocument.class);
System.out.println("======创建索引结果:"+indexRes+"=========");
//添加索引
CpDocument cpTest = new CpDocument();
cpTest.setId(1);
cpTest.setName("阿里巴巴");
cpTest.setAddress("北京路12号");
cpRepository.save(cpTest);
}
@Test
public void srarchTest() {
//这个只做一个多字段的匹配查询示例,其它的可以查看API文档使用
//"name","address" 为匹配的字段
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("阿里巴巴","address","name");//多字段匹配QueryBuilder
SearchQuery searchQuery = new NativeSearchQueryBuilder()//构建查询对象
.withQuery(multiMatchQuery)
.withIndices("cp_doc")//索引名
.withPageable(PageRequest.of(0, 10))//分页
.build();
Iterable<CpDocument> productDtos = cpRepository.search(searchQuery);
ArrayList<CpDocument> CpDocuments = Lists.newArrayList(productDtos);
for (CpDocument cpDocument : CpDocuments) {
System.out.printf("企业名称:%s,企业地址:%s\n",cpDocument.getName(),cpDocument.getAddress());
}
}
加载全部内容