pandas 宽表变窄表 pandas使用之宽表变窄表的实现
爾莎 人气:0我就废话不多说了,还是直接看代码吧!
import pandas as pd
# 伪造一些数据
fake_data = {'subject':['math', 'english'],
'A': [88, 90],
'B': [70, 80],
'C': [60, 78]}
# 宽表
test = pd.DataFrame(fake_data, columns=['subject', 'A', 'B', 'C'])
test
subject A B C
0 math 88 70 60
1 english 90 80 78
# 转换为窄表
pd.melt(test, id_vars=['subject'])
subject variable value
0 math A 88
1 english A 90
2 math B 70
3 english B 80
4 math C 60
5 english C 78
补充知识:pandas从单条目数据集生成宽表
需求
场景
从医院数据库中导出了大量的体检数据,但体检数据表中,每一行代表某人某次体检的某一项体检的结果。目的想将每一个人的每一次体检结果作为一行存储,每一列为体检项。
示例
| StuID | Type | Num | |
|---|---|---|---|
| 0 | 111021 | Math | 89 |
| 1 | 111021 | English | 93 |
| 2 | 312983 | English | 91 |
| 3 | 314621 | English | 82 |
| 4 | 314621 | Math | 92 |
| 5 | 112341 | Math | 82 |
目的:转换成如下表格
| StuID | English | Math | |
|---|---|---|---|
| 0 | 111021 | 93 | 89 |
| 1 | 312983 | 91 | NaN |
| 2 | 314621 | 82 | 92 |
| 3 | 112341 | NaN | 82 |
方案一
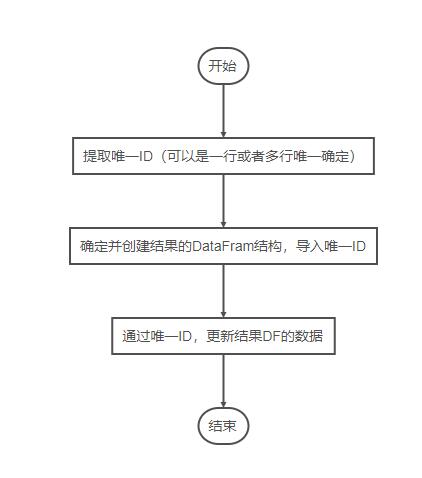
具体代码如下
#将'B'列的类别调整为行。
#1
num = df[~df.duplicated(subset=['StuID'])].loc[:,'StuID'].to_list()
#2
result_df = pd.DataFrame({'StuID': np.array(num)},columns=['StuID','English','Math'])
#3
for i in df.index:
t = df.loc[i,'Type']
num = df.loc[i,'StuID']
result_df.loc[result_df['StuID'] == num,[t]] = df.loc[i,'Num']
print(result_df)
结果

以上这篇pandas使用之宽表变窄表的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容