python线性回归 python机器学习之线性回归详解
佩瑞 人气:0想了解python机器学习之线性回归详解的相关内容吗,佩瑞在本文为您仔细讲解python线性回归的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:python线性回归,python机器学习,下面大家一起来学习吧。
一、python机器学习–线性回归
线性回归是最简单的机器学习模型,其形式简单,易于实现,同时也是很多机器学习模型的基础。
对于一个给定的训练集数据,线性回归的目的就是找到一个与这些数据最吻合的线性函数。
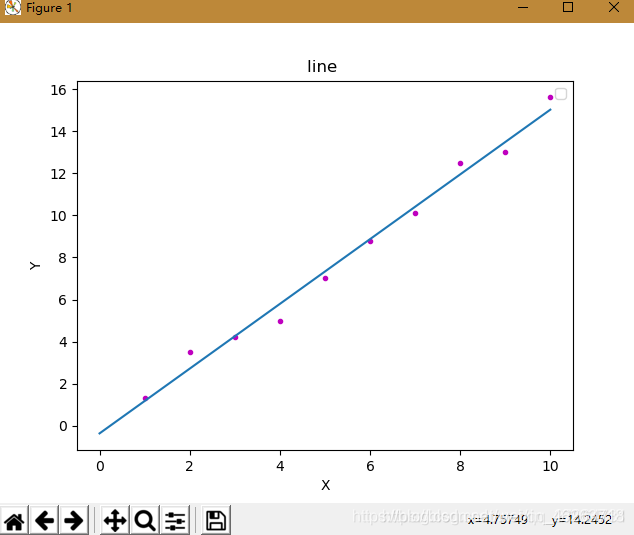
二、OLS线性回归
2.1 Ordinary Least Squares 最小二乘法
一般情况下,线性回归假设模型为下,其中w为模型参数
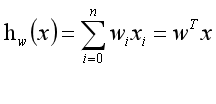
线性回归模型通常使用MSE(均方误差)作为损失函数,假设有m个样本,均方损失函数为:(所有实例预测值与实际值误差平方的均值)
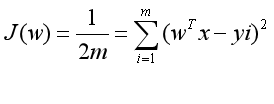
由于模型的训练目标为找到使得损失函数最小化的w,经过一系列变换解得使损失函数达到最小值的w为:
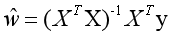
此时求得的w即为最优模型参数
2.2 OLS线性回归的代码实现
#OLS线性回归
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
%matplotlib inline
data = pd.DataFrame(pd.read_excel(r'C:/Users/15643/Desktop/附件1.xlsx'))
feature_data = data.drop(['企业信誉评估'],axis=1)
target_data = data['企业信誉评估']
X_train,X_test,y_train, y_test = train_test_split(feature_data, target_data, test_size=0.3)
from statsmodels.formula.api import ols
from statsmodels.sandbox.regression.predstd import wls_prediction_std
df_train = pd.concat([X_train,y_train],axis=1)
lr_model = ols("企业信誉评估~销项季度均值+有效发票比例+是否违约+企业供求关系+行业信誉度+销项季度标准差",data=df_train).fit()
print(lr_model.summary())
# 预测测试集
lr_model.predict(X_test)
三、梯度下降算法
很多机器学习算法的最优参数不能通过像最小二乘法那样的“闭式”方程直接计算,此时需要使用迭代优化方法。
梯度学习算法可被描述为:
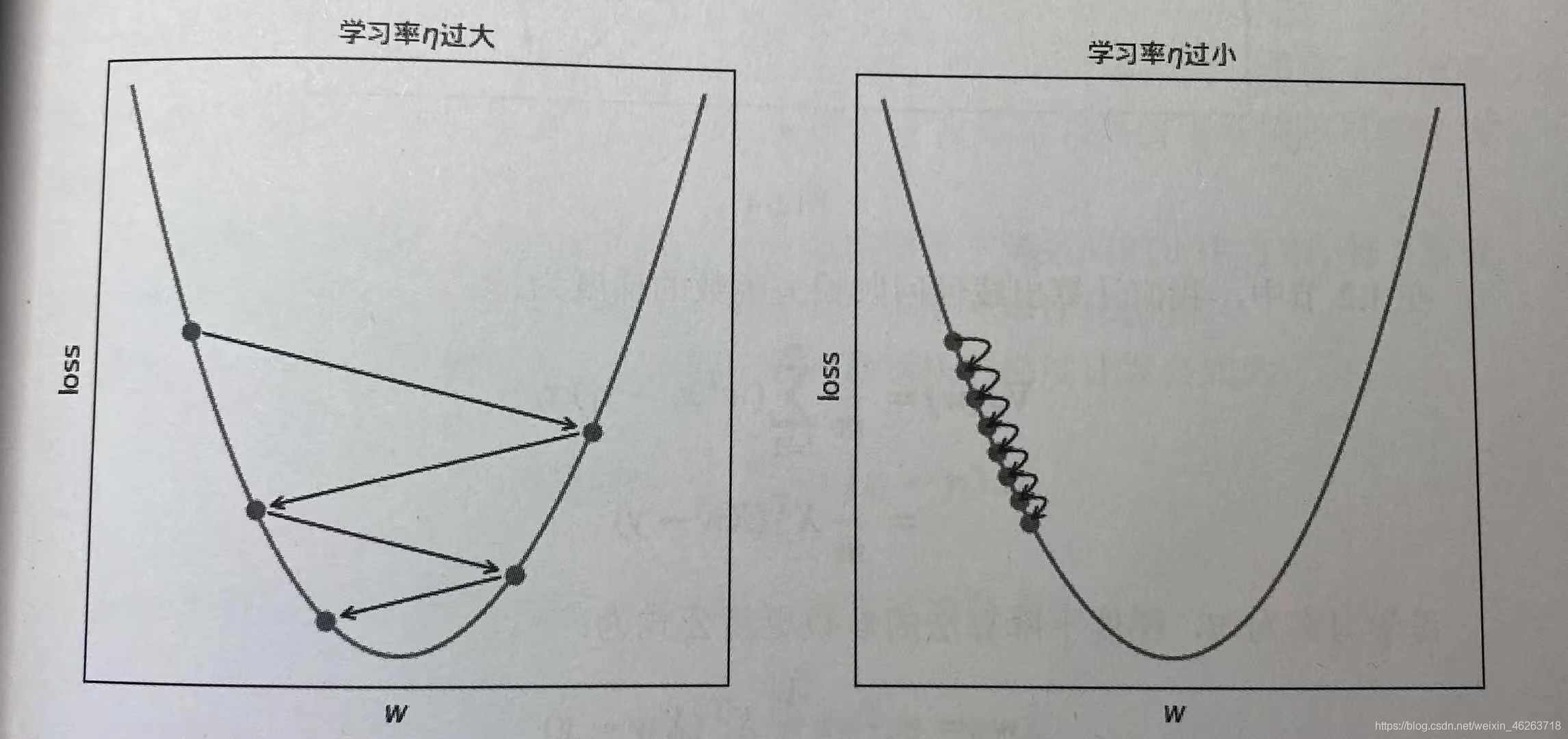
(1)根据当前参数w计算损失函数梯度∇J( w )
(2)沿着梯度反方向−∇J( w )调整w,调整的大小称之为步长,由学习率η控制w:= w−η∇J( w )
(3)反复执行该过程,直到梯度为0或损失函数降低小于阈值,此时称算法收敛。
3.1 GDLinearRegression代码实现
from linear_regression import GDLinearRegression gd_lr = GDLinearRegression(n_iter=3000,eta=0.001,tol=0.00001) #梯度下降最大迭代次数n_iter #学习率eta #损失降低阈值tol
四、多项式回归分析
多项式回归是研究一个因变量与一个或者多个自变量间多项式的回归分析方法。
多项式回归模型方程式如下:
hθ(x)=θ0+θ1x+θ2x2+...+θmxm
简单来说就是在阶数=k的情况下将每一个特征转换为一个k阶的多项式,这些多项式共同构成了一个矩阵,将这个矩阵看作一个特征,由此多项式回归模型就转变成了简单的线性回归。以下为特征x的多项式转变:
x−>[1,x,x2,x3...xk]
4.1 多项式回归的代码实现
python的多项式回归需要导入PolynomialFeatures类实现
#scikit-learn 多项式拟合(多元多项式回归) #PolynomialFeatures和linear_model的组合 (线性拟合非线性) #[x1,x2,x3]==[[1,x1,x1**2],[1,x2,x2**2],[1,x3,x3**2]] import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression,Perceptron from sklearn.metrics import mean_squared_error,r2_score from sklearn.model_selection import train_test_split target = std_df_female['总分'] data_complete_ = std_df_female.loc[:,['1000/800','50m','立定跳远','引仰']] x_train, x_test, y_train, y_test = train_test_split(data_complete_,target, test_size=0.3) # 多项式拟合 poly_reg =PolynomialFeatures(degree=2) x_train_poly = poly_reg.fit_transform(x_train) model = LinearRegression() model.fit(x_train_poly, y_train) #print(poly_reg.coef_,poly_reg.intercept_) #系数及常数 # 测试集比较 x_test_poly = poly_reg.fit_transform(x_test) y_test_pred = model.predict(x_test_poly) #mean_squared_error(y_true, y_pred) #均方误差回归损失,越小越好。 mse = np.sqrt(mean_squared_error(y_test, y_test_pred)) # r2 范围[0,1],R2越接近1拟合越好。 r2 = r2_score(y_test, y_test_pred) print(r2)
加载全部内容