对python打乱数据集中X,y标签对的方法详解
人气:0今天踩过的两个小坑:
一.用random的shuffle打乱数据集中的数据-标签对
index=[i for i in range(len(X_batch))] # print(type(index)) index=random.shuffle(index)
结果shuffle完以后index变成None了,看了下api,这样说明的:

这个函数如果返回值,就返回None,所以用index=balabala就把index的内容改变了。去掉index=random.shuffle(index)等号前面的值,这样利用shuffle函数就可以直接将index的内容打乱,并且不返回任何值。
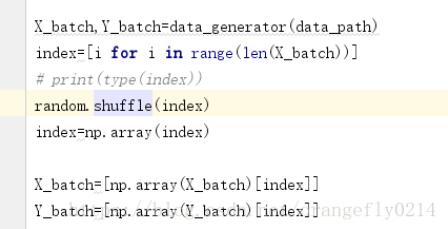
因此以上方式就可以打乱index的顺序,并以新顺序输出batch中的数据。
二.整体引用index这个list中的数据
因为index是一个list,所以代码这样写:
X_batch=X_batch[index] Y_batch=Y_batch[index]
是有问题的,报错是:TypeError: list indices must be integers or slices, not list.
这是因为我的X_batch,Y_batch都是list,直接引用index是错误的。而可以直接引用的方法是如果X_batch,Y_batch是数组,index是数组,就可以。
所以代码改成了:
X_batch,Y_batch=data_generator(data_path) index=[i for i in range(len(X_batch))] # print(type(index)) random.shuffle(index) index=np.array(index) X_batch=[np.array(X_batch)[index]] Y_batch=[np.array(Y_batch)[index]]
参考代码:
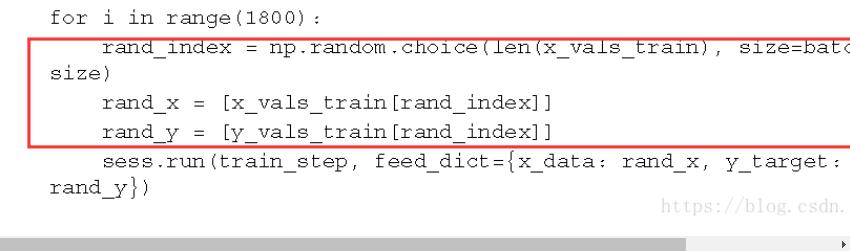
以上这篇对python打乱数据集中X,y标签对的方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
您可能感兴趣的文章:
加载全部内容