php-fpm重启导致的程序执行中断问题详解
人气:2背景和初步排查
- 订单业务对账时报警了,有笔订单在我们自己的mongo库里没有找到
- 业务接口 /3/xx/vgift/send 调用礼物系统 sendPresent 接口完成送礼, 之后写mongo,但是php error log 里却查不到任何mongo异常日志
- 写mongo没有异常,但是库里却没记录,推断只有2个可能
1是error log 丢日志了
2是程序执行过程中操作完sendPresent后down掉了,导致没写入mongo
-第一个情况工作多年的经验来看应该不至于,那就先根据第二种情况继续查吧
- 那就去看下php-fpm 的日志,看对应的时间点有没有什么异常
[wu.daolin@web001.m6~]$ grep "2017 05:28" /var/log/php-fpm.log [25-Jun-2017 05:28:01] NOTICE: Terminating ...
跟订单时间刚好吻合,那肯定有必要研究下了
熟悉下 php-fpm 的管理
php-fpm 是通过 php-fpm这个命令进行管理的,我们先看下这个命令
man php-fpm
这里有提到,php-fpm then responds to several POSIX signals php-fpm 会对下面几个信号作(自己的)处理
- SIGINT, SIGTERM: immediate termination
- SIGQUIT: graceful stop
- SIGUSR1: re-open log file
- SIGUSR2: graceful reload of all workers + reload of fpm conf/binary
动手验证下
sudo kill -QUIT {php-fpm-pid}
[26-Jun-2017 13:58:22] NOTICE: Finishing ... [26-Jun-2017 13:58:22] NOTICE: exiting, bye-bye!
sudo kill -TERM {php-fpm-pid}
[26-Jun-2017 13:59:21] NOTICE: Terminating ... [26-Jun-2017 13:59:21] NOTICE: exiting, bye-bye!
sudo kill -USR2 12583
[26-Jun-2017 14:00:48] NOTICE: Reloading in progress ...
[26-Jun-2017 14:00:48] NOTICE: reloading: execvp("/usr/sbin/php-fpm", {"/usr/sbin/php-fpm", "--daemonize"})
[26-Jun-2017 14:00:48] NOTICE: using inherited socket fd=8, "10.30.60.87:9000"
[26-Jun-2017 14:00:48] NOTICE: using inherited socket fd=8, "10.30.60.87:9000"
[26-Jun-2017 14:00:48] NOTICE: fpm is running, pid 12696
[26-Jun-2017 14:00:48] NOTICE: ready to handle connections
从验证结果推断
在 05:28:01这个时间有人给php-fpm 发送了SIGTERM信号,在这个点发生很可能是个定时任务, 确认果然是这样 28 5 * * * root /etc/init.d/php-fpm restart> /dev/null
我们的 php-fpm 管理
- init script 是 /etc/init.d/php-fpm
- 其中stop 是
killproc -p ${pidfile} php-fpm, 显然从日志结果来个是kill -TERM . 文档里也说了默认信号就是TERMkillproc sends signals to all processes that use the specified executable. If no signal name is specified, the signal SIGTERM is sent.
看下这个情况下nginx的反应
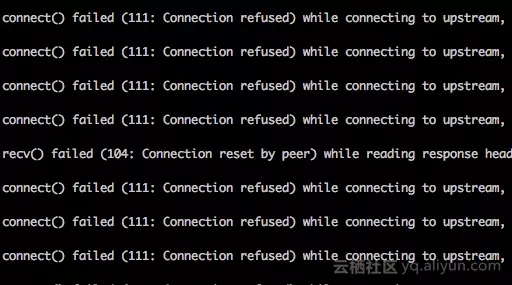
总结原因
- 业务请求时执行完 sendPresent这个动作后 , 还没来得及写mongo库, php-fpm就刚好被 terminate 了,.... 刚好赶上了
替代方案
- 虽然php-fpm 没有解释 terminate 跟 graceful stop 的具体含义, 但猜的话前者是直接就终止程序的执行了,后者可能是温柔点,把处理中的请求里的所有操作都执行完再杀死。。。
- 总之 SIGTERM terminate 调php 工作进程太粗暴了,应该要改一下比较好
- 改成 SIGUSER2 reload 方式
- 改成 SIGQUIT方式 ,把
killproc -p ${pidfile} php-fpm这句 改成killproc -p ${pidfile} php-fpm -QUIT - php-fpm 的worker 是计数n次后就会杀掉重新拉一个,如果用reload感觉功能重复了,根本没必要定时重启了, 我还是选 graceful stop(SIGQUIT) 吧
- 当然还有个问题时,为啥要配置个定时重启,将上面的内容发给sa看了
与sa 的问答
sa 说了3点意见
- 建议看下 -QUIT 时,Nginx的状态码是否正常?另外在某种情况下,可能会造成 PHP-FPM 进程退出时间比较长,会影响部署吗?
- 用 reload(SIGUSER2) 而不是用SIGTERM停掉再启动.
我们之前的测试结果看 reload 之后,nginx会报 502,并不 graceful stop。建议做好测试确认,包括部署php代码时是不是 reload?Bug #60961 Graceful Restart (USR2) isn't very graceful - php-fpm每天定时重启脚本 这个定时脚本大概是在2012年部署的,当时是担心 PHP-FPM 存在内存泄漏的情况而添加的。到现在是不是还适用?建议找一台机器关掉定时脚本观察一段较长时间看看。
我回复
- SIGQUIT 是否正常还不清楚,但现在的默认 SIGTERM 是立即停掉php 进程是肯定不正常的 -- 从nginx error log 看,对于nginx 和 php-fpm已经建立好的连接,错误是 “104: Connection reset by peer”; 准备去连的是“111: Connection refused”;
- “111: Connection refused” 是还可以接受的,连不上而已,用户稍后重试就可以;“104: Connection reset by peer” 这个就很难接受,这个错我理解的意思是连接已经建好了,php突然terminate了,然后发了个RST分节给nginx;背后就表示当前请求可能只执行了一半动作,还有动作没执行完,这可能就造成丢数据了。。。比如文章开头说的这个问题
- reload 那个其实就是 -USR2信号,这个bug看起来还没解决。。。不过-USR2 应该说是偶现terminate,但 -TERM 肯定是必现terminate
- 现在代码部署逻辑是同步代码+清理opcache和yac缓存, 不对php-fpm进程做操作
- php-fpm 会自己对worker进程处理的请求数计数,达到一定数量就干掉再重新拉一个; 所以worker进程应该没有什么内存泄露的问题; manager 进程就不清楚了,但我想概率应该是极其低的。这个适不适用感觉很难去证伪啊。。。
- 所以要不找3台机器, 一台用 -QUIT, 一台用 -USR2, 一台去掉这个定时任务;先观察下
- sa 回复可以,我们自己看着办
尾声
改成 SIGQUIT 信号nginx里还是有 104: Connection reset by peer, 看来手册里说SIGQUIT: graceful stop 也不能保证一次请求里的所有动作都执行完啊
最终结果 去掉这个定时重启php-fpm 的任务, 已经3个多月了,没发现问题,oh yeah~
参考文档
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。
您可能感兴趣的文章:
加载全部内容