python实现统计文本中单词出现的频率详解
人气:0
#coding=utf-8
import os
from collections import Counter
sumsdata=[]
for fname in os.listdir(os.getcwd()):
if os.path.isfile(fname) and fname.endswith('.txt'):
with open(fname,'r') as fp:
data=fp.readlines()
sumsdata+=[line.strip().lower() for line in data]
cnt=Counter()
for word in sumsdata:
cnt[word]+=1
cnt=dict(cnt)
for key,value in cnt.items():
print(key+":"+str(value))
首先在和程序所在路径下创建几个文本文件,我建了两个,文件内容分别为hello python goodbye python 和 i like python。运行程序,得到以下结果
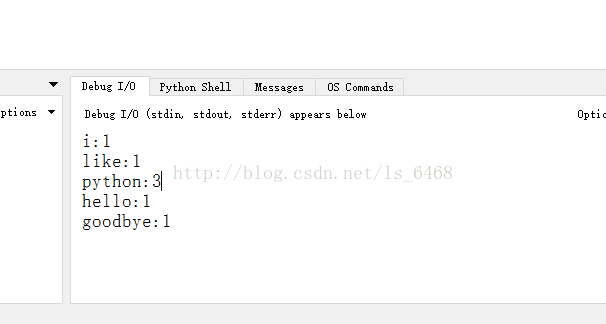
以上所述是小编给大家介绍的python统计文本中单词出现频率详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
您可能感兴趣的文章:
加载全部内容