浅谈PySpark SQL 相关知识介绍
人气:11 大数据简介
大数据是这个时代最热门的话题之一。但是什么是大数据呢?它描述了一个庞大的数据集,并且正在以惊人的速度增长。大数据除了体积(Volume)和速度(velocity)外,数据的多样性(variety)和准确性(veracity)也是大数据的一大特点。让我们详细讨论体积、速度、多样性和准确性。这些也被称为大数据的4V特征。
1.1 Volume
数据体积(Volume)指定要处理的数据量。对于大量数据,我们需要大型机器或分布式系统。计算时间随数据量的增加而增加。所以如果我们能并行化计算,最好使用分布式系统。数据可以是结构化数据、非结构化数据或介于两者之间的数据。如果我们有非结构化数据,那么情况就会变得更加复杂和计算密集型。你可能会想,大数据到底有多大?这是一个有争议的问题。但一般来说,我们可以说,我们无法使用传统系统处理的数据量被定义为大数据。现在让我们讨论一下数据的速度。
1.2 Velocity
越来越多的组织机构开始重视数据。每时每刻都在收集大量的数据。这意味着数据的速度在增加。一个系统如何处理这个速度?当必须实时分析大量流入的数据时,问题就变得复杂了。许多系统正在开发,以处理这种巨大的数据流入。将传统数据与大数据区别开来的另一个因素是数据的多样性。
1.3 Variety
数据的多样性使得它非常复杂,传统的数据分析系统无法正确地分析它。我们说的是哪一种?数据不就是数据吗?图像数据不同于表格数据,因为它的组织和保存方式不同。可以使用无限数量的文件系统。每个文件系统都需要一种不同的方法来处理它。读取和写入JSON文件与处理CSV文件的方式不同。现在,数据科学家必须处理数据类型的组合。您将要处理的数据可能是图片、视频、文本等的组合。大数据的多样性使得分析变得更加复杂。
1.4 Veracity
你能想象一个逻辑错误的计算机程序产生正确的输出吗?同样,不准确的数据将提供误导的结果。准确性,或数据正确性,是一个重要的问题。对于大数据,我们必须考虑数据的异常。
2 Hadoop 介绍
Hadoop是一个解决大数据问题的分布式、可伸缩的框架。Hadoop是由Doug Cutting和Mark Cafarella开发的。Hadoop是用Java编写的。它可以安装在一组商用硬件上,并且可以在分布式系统上水平扩展。
在商品硬件上工作使它非常高效。如果我们的工作是在商品硬件,故障是一个不可避免的问题。但是Hadoop为数据存储和计算提供了一个容错系统。这种容错能力使得Hadoop非常流行。
Hadoop有两个组件:第一个组件是HDFS(Hadoop Distributed File System),它是一个分布式文件系统。第二个组件是MapReduce。HDFS用于分布式数据存储,MapReduce用于对存储在HDFS中的数据执行计算。
2.1 HDFS介绍
HDFS用于以分布式和容错的方式存储大量数据。HDFS是用Java编写的,在普通硬件上运行。它的灵感来自于谷歌文件系统(GFS)的谷歌研究论文。它是一个写一次读多次的系统,对大量的数据是有效的。HDFS有两个组件NameNode和DataNode。
这两个组件是Java守护进程。NameNode负责维护分布在集群上的文件的元数据,它是许多datanode的主节点。HDFS将大文件分成小块,并将这些块保存在不同的datanode上。实际的文件数据块驻留在datanode上。HDFS提供了一组类unix-shell的命令。但是,我们可以使用HDFS提供的Java filesystem API在更细的级别上处理大型文件。容错是通过复制数据块来实现的。
我们可以使用并行的单线程进程访问HDFS文件。HDFS提供了一个非常有用的实用程序,称为distcp,它通常用于以并行方式将数据从一个HDFS系统传输到另一个HDFS系统。它使用并行映射任务复制数据。
2.2 MapReduce介绍
计算的MapReduce模型最早出现在谷歌的一篇研究论文中。Hadoop的MapReduce是Hadoop框架的计算引擎,它在HDFS中对分布式数据进行计算。MapReduce已被发现可以在商品硬件的分布式系统上进行水平伸缩。它也适用于大问题。在MapReduce中,问题的解决分为Map阶段和Reduce阶段。在Map阶段,处理数据块,在Reduce阶段,对Map阶段的结果运行聚合或缩减操作。Hadoop的MapReduce框架也是用Java编写的。
MapReduce是一个主从模型。在Hadoop 1中,这个MapReduce计算由两个守护进程Jobtracker和Tasktracker管理。Jobtracker是处理许多任务跟踪器的主进程。Tasktracker是Jobtracker的从节点。但在Hadoop 2中,Jobtracker和Tasktracker被YARN取代。
我们可以使用框架提供的API和Java编写MapReduce代码。Hadoop streaming体模块使具有Python和Ruby知识的程序员能够编写MapReduce程序。
MapReduce算法有很多用途。如许多机器学习算法都被Apache Mahout实现,它可以在Hadoop上通过Pig和Hive运行。
但是MapReduce并不适合迭代算法。在每个Hadoop作业结束时,MapReduce将数据保存到HDFS并为下一个作业再次读取数据。我们知道,将数据读入和写入文件是代价高昂的活动。Apache Spark通过提供内存中的数据持久性和计算,减轻了MapReduce的缺点。
更多关于Mapreduce 和 Mahout 可以查看如下网页:
https://www.usenix.org/legacy/publications/library/proceedings/osdi04/tech/full_papers/dean/dean_html/index.html
https://mahout.apache.org/users/basics/quickstart.html
3 Apache Hive 介绍
计算机科学是一个抽象的世界。每个人都知道数据是以位的形式出现的信息。像C这样的编程语言提供了对机器和汇编语言的抽象。其他高级语言提供了更多的抽象。结构化查询语言(Structured Query Language, SQL)就是这些抽象之一。世界各地的许多数据建模专家都在使用SQL。Hadoop非常适合大数据分析。那么,了解SQL的广大用户如何利用Hadoop在大数据上的计算能力呢?为了编写Hadoop的MapReduce程序,用户必须知道可以用来编写Hadoop的MapReduce程序的编程语言。
现实世界中的日常问题遵循一定的模式。一些问题在日常生活中很常见,比如数据操作、处理缺失值、数据转换和数据汇总。为这些日常问题编写MapReduce代码对于非程序员来说是一项令人头晕目眩的工作。编写代码来解决问题不是一件很聪明的事情。但是编写具有性能可伸缩性和可扩展性的高效代码是有价值的。考虑到这个问题,Apache Hive就在Facebook开发出来,它可以解决日常问题,而不需要为一般问题编写MapReduce代码。
根据Hive wiki的语言,Hive是一个基于Apache Hadoop的数据仓库基础设施。Hive有自己的SQL方言,称为Hive查询语言。它被称为HiveQL,有时也称为HQL。使用HiveQL, Hive查询HDFS中的数据。Hive不仅运行在HDFS上,还运行在Spark和其他大数据框架上,比如Apache Tez。
Hive为HDFS中的结构化数据向用户提供了类似关系数据库管理系统的抽象。您可以创建表并在其上运行类似sql的查询。Hive将表模式保存在一些RDBMS中。Apache Derby是Apache Hive发行版附带的默认RDBMS。Apache Derby完全是用Java编写的,是Apache License Version 2.0附带的开源RDBMS。
HiveQL命令被转换成Hadoop的MapReduce代码,然后在Hadoop集群上运行。
了解SQL的人可以轻松学习Apache Hive和HiveQL,并且可以在日常的大数据数据分析工作中使用Hadoop的存储和计算能力。PySpark SQL也支持HiveQL。您可以在PySpark SQL中运行HiveQL命令。除了执行HiveQL查询,您还可以直接从Hive读取数据到PySpark SQL并将结果写入Hive
相关链接:
https://cwiki.apache.org/confluence/display/Hive/Tutorial
https://db.apache.org/derby/
4 Apache Pig介绍
Apache Pig是一个数据流框架,用于对大量数据执行数据分析。它是由雅虎开发的,并向Apache软件基金会开放源代码。它现在可以在Apache许可2.0版本下使用。Pig编程语言是一种Pig拉丁脚本语言。Pig松散地连接到Hadoop,这意味着我们可以将它连接到Hadoop并执行许多分析。但是Pig可以与Apache Tez和Apache Spark等其他工具一起使用。
Apache Hive用作报告工具,其中Apache Pig用于提取、转换和加载(ETL)。我们可以使用用户定义函数(UDF)扩展Pig的功能。用户定义函数可以用多种语言编写,包括Java、Python、Ruby、JavaScript、Groovy和Jython。
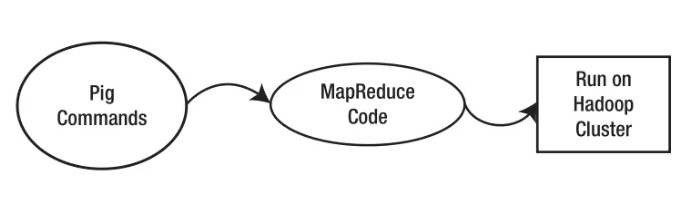
Apache Pig使用HDFS读取和存储数据,Hadoop的MapReduce执行算法。Apache Pig在使用Hadoop集群方面类似于Apache Hive。在Hadoop上,Pig命令首先转换为Hadoop的MapReduce代码。然后将它们转换为MapReduce代码,该代码运行在Hadoop集群上。
Pig最好的部分是对代码进行优化和测试,以处理日常问题。所以用户可以直接安装Pig并开始使用它。Pig提供了Grunt shell来运行交互式的Pig命令。因此,任何了解Pig Latin的人都可以享受HDFS和MapReduce的好处,而不需要了解Java或Python等高级编程语言。
相关链接
http://pig.apache.org/docs/
https://en.wikipedia.org/wiki/Pig_(programming_tool))
https://cwiki.apache.org/confluence/display/PIG/Index
5 Apache Kafka 介绍
Apache Kafka是一个发布-订阅的分布式消息传递平台。它由LinkedIn开发,并进一步开源给Apache基金会。它是容错的、可伸缩的和快速的。Kafka术语中的消息(数据的最小单位)通过Kafka服务器从生产者流向消费者,并且可以在稍后的时间被持久化和使用。
Kafka提供了一个内置的API,开发人员可以使用它来构建他们的应用程序。接下来我们讨论Apache Kafka的三个主要组件。
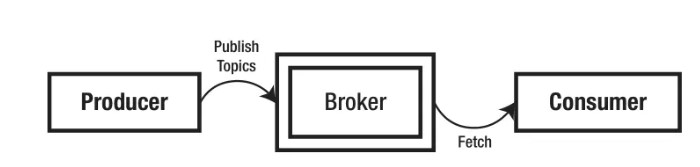
5.1 Producer
Kafka Producer 将消息生成到Kafka主题,它可以将数据发布到多个主题。
5.2 Broker
这是运行在专用机器上的Kafka服务器,消息由Producer推送到Broker。Broker将主题保存在不同的分区中,这些分区被复制到不同的Broker以处理错误。它本质上是无状态的,因此使用者必须跟踪它所消费的消息。
5.3 Consumer
Consumer从Kafka代理获取消息。记住,它获取消息。Kafka Broker不会将消息推送给Consumer;相反,Consumer从Kafka Broker中提取数据。Consumer订阅Kafka Broker上的一个或多个主题,并读取消息。Broker还跟踪它所使用的所有消息。数据将在Broker中保存指定的时间。如果使用者失败,它可以在重新启动后获取数据。
相关链接:
https://kafka.apache.org/quickstart
https://kafka.apache.org/documentation/
6 Apache Spark介绍
Apache Spark是一个通用的分布式编程框架。它被认为非常适合迭代和批处理数据。它是在AMP实验室开发的,它提供了一个内存计算框架。它是开源软件。一方面,它最适合批量处理,另一方面,它对实时或接近实时的数据非常有效。机器学习和图形算法本质上是迭代的,这就是Spark的神奇之处。根据它的研究论文,它比它的同行Hadoop快得多。数据可以缓存在内存中。在迭代算法中缓存中间数据提供了惊人的快速处理。Spark可以使用Java、Scala、Python和R进行编程。
如果您认为Spark是经过改进的Hadoop,在某种程度上,确实是可以这么认为的。因为我们可以在Spark中实现MapReduce算法,所以Spark使用了HDFS的优点。这意味着它可以从HDFS读取数据并将数据存储到HDFS,而且它可以有效地处理迭代计算,因为数据可以保存在内存中。除了内存计算外,它还适用于交互式数据分析。
还有许多其他库也位于PySpark之上,以便更容易地使用PySpark。下面我们将讨论一些:
- MLlib: MLlib是PySpark核心的一个包装器,它处理机器学习算法。MLlib库提供的机器学习api非常容易使用。MLlib支持多种机器学习算法,包括分类、聚类、文本分析等等。
- ML: ML也是一个位于PySpark核心的机器学习库。ML的机器学习api可以用于数据流。
- GraphFrames: GraphFrames库提供了一组api,可以使用PySpark core和PySpark SQL高效地进行图形分析。
7 PySpark SQL介绍
数据科学家处理的大多数数据在本质上要么是结构化的,要么是半结构化的。为了处理结构化和半结构化数据集,PySpark SQL模块是该PySpark核心之上的更高级别抽象。我们将在整本书中学习PySpark SQL。它内置在PySpark中,这意味着它不需要任何额外的安装。
使用PySpark SQL,您可以从许多源读取数据。PySpark SQL支持从许多文件格式系统读取,包括文本文件、CSV、ORC、Parquet、JSON等。您可以从关系数据库管理系统(RDBMS)读取数据,如MySQL和PostgreSQL。您还可以将分析报告保存到许多系统和文件格式。
7.1 DataFrames
DataFrames是一种抽象,类似于关系数据库系统中的表。它们由指定的列组成。DataFrames是行对象的集合,这些对象在PySpark SQL中定义。DataFrames也由指定的列对象组成。用户知道表格形式的模式,因此很容易对数据流进行操作。
DataFrame 列中的元素将具有相同的数据类型。DataFrame 中的行可能由不同数据类型的元素组成。基本数据结构称为弹性分布式数据集(RDD)。数据流是RDD上的包装器。它们是RDD或row对象。
相关链接:
https://spark.apache.org/docs/latest/sql-programming-guide.html
7.2 SparkSession
SparkSession对象是替换SQLContext和HiveContext的入口点。为了使PySpark SQL代码与以前的版本兼容,SQLContext和HiveContext将继续在PySpark中运行。在PySpark控制台中,我们获得了SparkSession对象。我们可以使用以下代码创建SparkSession对象。
为了创建SparkSession对象,我们必须导入SparkSession,如下所示。
from pyspark.sql import SparkSession
导入SparkSession后,我们可以使用SparkSession.builder进行操作:
spark = SparkSession.builder.appName("PythonSQLAPP") .getOrCreate()
appName函数将设置应用程序的名称。函数的作用是:返回一个现有的SparkSession对象。如果不存在SparkSession对象,getOrCreate()函数将创建一个新对象并返回它。
7.3 Structured Streaming
我们可以使用结构化流框架(PySpark SQL的包装器)进行流数据分析。我们可以使用结构化流以类似的方式对流数据执行分析,就像我们使用PySpark SQL对静态数据执行批处理分析一样。正如Spark流模块对小批执行流操作一样,结构化流引擎也对小批执行流操作。结构化流最好的部分是它使用了类似于PySpark SQL的API。因此,学习曲线很高。对数据流的操作进行优化,并以类似的方式在性能上下文中优化结构化流API。
7.4 Catalyst Optimizer
SQL是一种声明性语言。使用SQL,我们告诉SQL引擎要做什么。我们不告诉它如何执行任务。类似地,PySpark SQL命令不会告诉它如何执行任务。这些命令只告诉它要执行什么。因此,PySpark SQL查询在执行任务时需要优化。catalyst优化器在PySpark SQL中执行查询优化。PySpark SQL查询被转换为低级的弹性分布式数据集(RDD)操作。catalyst优化器首先将PySpark SQL查询转换为逻辑计划,然后将此逻辑计划转换为优化的逻辑计划。从这个优化的逻辑计划创建一个物理计划。创建多个物理计划。使用成本分析仪,选择最优的物理方案。最后,创建低层RDD操作代码。
8 集群管理器(Cluster Managers)
在分布式系统中,作业或应用程序被分成不同的任务,这些任务可以在集群中的不同机器上并行运行。如果机器发生故障,您必须在另一台机器上重新安排任务。
由于资源管理不善,分布式系统通常面临可伸缩性问题。考虑一个已经在集群上运行的作业。另一个人想做另一份工作。第二项工作必须等到第一项工作完成。但是这样我们并没有最优地利用资源。资源管理很容易解释,但是很难在分布式系统上实现。开发集群管理器是为了优化集群资源的管理。有三个集群管理器可用于Spark单机、Apache Mesos和YARN。这些集群管理器最好的部分是,它们在用户和集群之间提供了一个抽象层。由于集群管理器提供的抽象,用户体验就像在一台机器上工作,尽管他们在集群上工作。集群管理器将集群资源调度到正在运行的应用程序。
8.1 单机集群管理器(Standalone Cluster Manager)
Apache Spark附带一个单机集群管理器。它提供了一个主从架构来激发集群。它是一个只使用spark的集群管理器。您只能使用这个独立的集群管理器运行Spark应用程序。它的组件是主组件和工作组件。工人是主过程的奴隶,它是最简单的集群管理器。可以使用Spark的sbin目录中的脚本配置Spark独立集群管理器。
8.2 Apache Mesos集群管理器(Apache Mesos Cluster Manager)
Apache Mesos是一个通用的集群管理器。它是在加州大学伯克利分校的AMP实验室开发的。Apache Mesos帮助分布式解决方案有效地扩展。您可以使用Mesos在同一个集群上使用不同的框架运行不同的应用程序。来自不同框架的不同应用程序的含义是什么?这意味着您可以在Mesos上同时运行Hadoop应用程序和Spark应用程序。当多个应用程序在Mesos上运行时,它们共享集群的资源。Apache Mesos有两个重要组件:主组件和从组件。这种主从架构类似于Spark独立集群管理器。运行在Mesos上的应用程序称为框架。奴隶告诉主人作为资源提供的可用资源。从机定期提供资源。主服务器的分配模块决定哪个框架获取资源。
8.3 YARN 集群管理器(YARN Cluster Manager)
YARN代表着另一个资源谈判者(Resource Negotiator)。在Hadoop 2中引入了YARN来扩展Hadoop。资源管理与作业管理分离。分离这两个组件使Hadoop的伸缩性更好。YARN的主要成分是资源管理器(Resource Manager)、应用程序管理器(Application Master)和节点管理器(Node Manager)。有一个全局资源管理器,每个集群将运行许多节点管理器。节点管理器是资源管理器的奴隶。调度程序是ResourceManager的组件,它为集群上的不同应用程序分配资源。最棒的部分是,您可以在YARN管理的集群上同时运行Spark应用程序和任何其他应用程序,如Hadoop或MPI。每个应用程序有一个application master,它处理在分布式系统上并行运行的任务。另外,Hadoop和Spark有它们自己的ApplicationMaster。
相关链接:
https://spark.apache.org/docs/2.0.0/spark-standalone.html
https://spark.apache.org/docs/2.0.0/running-on-mesos.html
https://spark.apache.org/docs/2.0.0/running-on-yarn.html
9 PostgreSQL介绍
关系数据库管理系统在许多组织中仍然非常常见。这里的关系是什么意思?关系表。PostgreSQL是一个关系数据库管理系统。它可以运行在所有主要的操作系统上,比如Microsoft Windows、基于unix的操作系统、MacOS X等等。它是一个开源程序,代码在PostgreSQL许可下可用。因此,您可以自由地使用它,并根据您的需求进行修改。
PostgreSQL数据库可以通过其他编程语言(如Java、Perl、Python、C和c++)和许多其他语言(通过不同的编程接口)连接。还可以使用与PL/SQL类似的过程编程语言PL/pgSQL(过程语言/PostgreSQL)对其进行编程。您可以向该数据库添加自定义函数。您可以用C/ c++和其他编程语言编写自定义函数。您还可以使用JDBC连接器从PySpark SQL中读取PostgreSQL中的数据。
PostgreSQL遵循ACID(Atomicity, Consistency, Isolation and
Durability/原子性、一致性、隔离性和持久性)原则。它具有许多特性,其中一些是PostgreSQL独有的。它支持可更新视图、事务完整性、复杂查询、触发器等。PostgreSQL使用多版本并发控制模型进行并发管理。
PostgreSQL得到了广泛的社区支持。PostgreSQL被设计和开发为可扩展的。
相关链接:
https://wiki.postgresql.org/wiki/Main_Page
https://en.wikipedia.org/wiki/PostgreSQL
https://en.wikipedia.org/wiki/Multiversion_concurrency_control
http://postgresguide.com/
10 MongoDB介绍
MongoDB是一个基于文档的NoSQL数据库。它是一个开放源码的分布式数据库,由MongoDB公司开发。MongoDB是用c++编写的,它是水平伸缩的。许多组织将其用于后端数据库和许多其他用途。
MongoDB附带一个mongo shell,这是一个到MongoDB服务器的JavaScript接口。mongo shell可以用来运行查询以及执行管理任务。在mongo shell上,我们也可以运行JavaScript代码。
使用PySpark SQL,我们可以从MongoDB读取数据并执行分析。我们也可以写出结果。
相关链接:
https://docs.mongodb.com/
11 Cassandra介绍
Cassandra是开放源码的分布式数据库,附带Apache许可证。这是一个由Facebook开发的NoSQL数据库。它是水平可伸缩的,最适合处理结构化数据。它提供了高水平的一致性,并且具有可调的一致性。它没有一个单一的故障点。它使用对等的分布式体系结构在不同的节点上复制数据。节点使用闲话协议交换信息。
相关链接:
https://www.datastax.com/resources/tutorials
http://cassandra.apache.org/doc/latest/
您可能感兴趣的文章:
加载全部内容