Python识别快递条形码及Tesseract-OCR使用详解
人气:0识别快递单号
这次跟老师做项目,这项目大概是流水线上识别快递上的快递单号。首先我尝试了解条形码的基本知识
百度百科:条形码
条形码(barcode)是将宽度不等的多个黑条和空白,按照一定的编码规则排列,用以表达一组信息的图形标识符。常见的条形码是由反射率相差很大的黑条(简称条)和白条(简称空)排成的平行线图案。条形码可以标出物品的生产国、制造厂家、商品名称、生产日期、图书分类号、邮件起止地点、类别、日期等许多信息,因而在商品流通、图书管理、邮政管理、银行系统等许多领域都得到广泛的应用。
条形码有多种,在我国广泛流传的是EAN13条形码(以下简称条形码),所以主要研究该种条形码的识别。
条形码位数说明:
- 条形码一共有13位
- 前2位或者前3位称为前缀,表示国家、地区或者某种特定的商品类型
- 中国区条形码开头:690~699
- 图书类条形码开头:978~979
- 前缀后的4位或者5位称为厂商代码,表示产品制造商
- 厂商代码后5位称为商品代码,表示具体的商品项目
- 最后1位是校验码,根据前12位计算而出,可以用来防伪以及识别校验
条形码编码说明
条形码一共有8个区域:左侧空白区->起始符->左侧数据符->中间分隔符->右侧数据符->校验符->终止符->右侧空白区
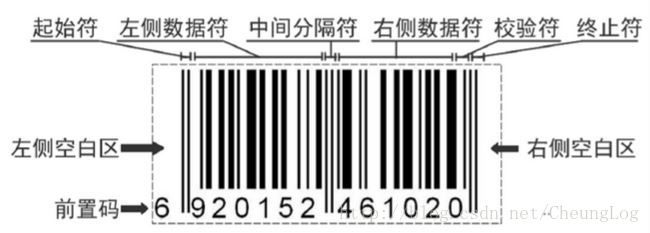
- 字符为0~9
- 除空白区外的区域和字符都采用二进制编码表示,1表示bar(黑条),0表示space(白条)
- 起始符,终止符编码为101,分隔符编码为01010
- 0~9每种字符有3种编码方式,AB为左侧数据奇偶编码,C为右侧数据偶编码
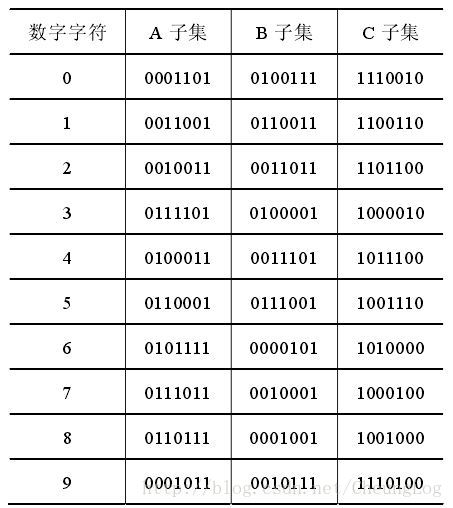
- 左侧数据的奇偶性由前置符决定(就是说,第一个支付是几就按下面的排列开始)
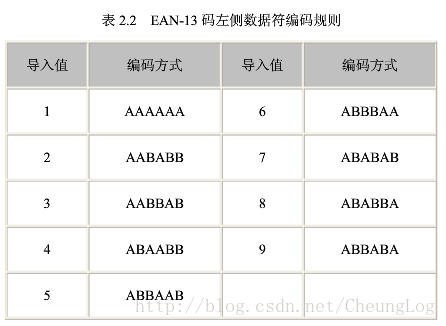
还有这么一种理解编码方法
以宽度为编码,去掉起始码,终止码,中间分隔码,不管白条还是黑条都算一个编码,最窄一节为1(最窄的为单位宽度),两个单位宽度就是2,三单位长度为3,四单位宽度为4
四条(不管黑条还是白条都算条)代表一个数字
| 四条长度 | 数字 |
|---|---|
| 3211 | 0 |
| 2221 | 1 |
| 2122 | 2 |
| 1411 | 3 |
| 1132 | 4 |
| 1231 | 5 |
| 1114 | 6 |
| 1312 | 7 |
| 1213 | 8 |
| 3112 | 9 |
两种编码的图示
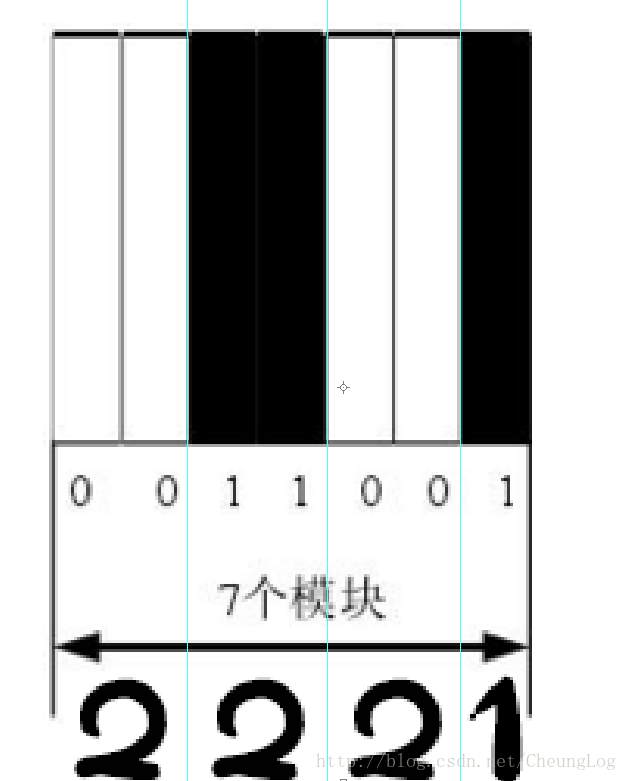
这就代表为 数字 1
校验
EAN13条形码一共有13位,最后1位是校验位,该位是通过前12位按照一定的步骤计算出来的。
如果按照一定的步骤处理识别出的前12位数据,如果计算结果和识别出的结果相等,识别正确;
如果不相等,则重新识别或纠错再校验或提示识别失败。
校验码计算方法
以下图所示的条形码举例说明:

条形码的位数起始位为最右一位,即校验位,检验码计算方法如下:
- 偶位数数值相加乘3((0+2+0+8+1+9)*3=60)
- 不含校验位的奇位数相加(7+4+7+9+3+6=36)
- 将前两步的结果相加(60+36=96)
- 用10减去上一步结果的个位数数值(10-6=4)
- 上一步结果的个位数即为校验码(4)
源码
#创建:2016/01/26
#文件:BarCodeIdentification.py
#作者:moverzp
#功能:识别条形码
import sys
import cv2
DECODING_TABLE = {
'0001101': 0, '0100111': 0, '1110010': 0,
'0011001': 1, '0110011': 1, '1100110': 1,
'0010011': 2, '0011011': 2, '1101100': 2,
'0111101': 3, '0100001': 3, '1000010': 3,
'0100011': 4, '0011101': 4, '1011100': 4,
'0110001': 5, '0111001': 5, '1001110': 5,
'0101111': 6, '0000101': 6, '1010000': 6,
'0111011': 7, '0010001': 7, '1000100': 7,
'0110111': 8, '0001001': 8, '1001000': 8,
'0001011': 9, '0010111': 9, '1110100': 9,
}
EDGE_TABLE = {
2:{2:6,3:0,4:4,5:3},
3:{2:9,3:'33',4:'34',5:5},
4:{2:9,3:'43',4:'44',5:5},
5:{2:6,3:0,4:4,5:3},
}
INDEX_IN_WIDTH = (0, 4, 8, 12, 16, 20, 24, 33, 37, 41, 45, 49, 53)
def get_bar_space_width(img):
row = img.shape[0] *1/2
currentPix = -1
lastPix = -1
pos = 0
width = []
for i in range(img.shape[1]):#遍历一整行
currentPix = img[row][i]
if currentPix != lastPix:
if lastPix == -1:
lastPix = currentPix
pos = i
else:
width.append( i - pos )
pos = i
lastPix = currentPix
return width
def divide(t, l):
if float(t) / l < 0.357:
return 2
elif float(t) / l < 0.500:
return 3
elif float(t) / l < 0.643:
return 4
else:
return 5
def cal_similar_edge(data):
similarEdge = []
#先判断起始符
limit = float(data[1] + data[2] + data[3] ) / 3 * 1.5
if data[1] >= limit or data[2] >= limit or data[3] >= limit:
return -1#宽度提取失败
index = 4
while index < 54:
#跳过分隔符区间
if index==28 or index==29 or index==30 or index==31 or index==32:
index +=1
continue
#字符检测
T1 = data[index] + data[index+1]
T2 = data[index+1] + data[index+2]
L = data[index] + data[index+1] + data[index+2] + data[index+3]
similarEdge.append( divide(T1, L) )
similarEdge.append( divide(T2, L) )
index += 4
return similarEdge
def decode_similar_edge(edge):
barCode = [6]#第一个字符一定是6,中国区
for i in range (0, 24, 2):#每个字符两个相似边,共12个字符
barCode.append( EDGE_TABLE[edge[i]][edge[i+1]] )
return barCode
def decode_sharp(barCode, barSpaceWidth):
for i in range(0, 13):
if barCode[i] == '44':
index = INDEX_IN_WIDTH[i]
c3 = barSpaceWidth[index+2]
c4 = barSpaceWidth[index+3]
if c3 > c4:
barCode[i] = 1
else:
barCode[i] = 7
elif barCode[i] == '33':
index = INDEX_IN_WIDTH[i]
c1 = barSpaceWidth[index]
c2 = barSpaceWidth[index+1]
if c1 > c2:
barCode[i] = 2
else:
barCode[i] = 8
elif barCode[i] == '34':
index = INDEX_IN_WIDTH[i]
c1 = barSpaceWidth[index]
c2 = barSpaceWidth[index+1]
if c1 > c2:
barCode[i] = 7
else:
barCode[i] = 1
elif barCode[i] == '43':
index = INDEX_IN_WIDTH[i]
c2 = barSpaceWidth[index+1]
c3 = barSpaceWidth[index+2]
if c2 > c3:
barCode[i] = 2
else:
barCode[i] = 8
def check_bar_code(barCode):
evens = barCode[11]+barCode[9]+barCode[7]+barCode[5]+barCode[3]+barCode[1]
odds = barCode[10]+barCode[8]+barCode[6]+barCode[4]+barCode[2]+barCode[0]
sum = evens * 3 + odds
if barCode[12] == (10 - sum % 10) % 10:
return True
else:
return False
#载入图像
img = cv2.imread('res\google6.jpg')
grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#转换成单通道图像
ret, grayImg = cv2.threshold(grayImg, 200, 255, cv2.THRESH_BINARY)#二值化
grayImg = cv2.medianBlur(grayImg, 3)#中值滤波
#提取条空宽度
barSpaceWidth = get_bar_space_width(grayImg)
print 'bar & space\'s numbers:', len(barSpaceWidth)#只有60是正确的
print barSpaceWidth
#计算相似边数值
similarEdge = cal_similar_edge(barSpaceWidth)
if similarEdge == -1:
print 'barSpaceWidth error!'
sys.exit()
print 'similarEdge\'s numbers:', len(similarEdge)
print similarEdge
#相似边译码
barCode = decode_similar_edge(similarEdge)
#针对‘#'译码
decode_sharp(barCode, barSpaceWidth)
#校验
valid = check_bar_code(barCode)
valid = 1
print 'barcode:\n', barCode if valid else 'Check barcode error!'
height = img.shape[0]
width = img.shape[1]
cv2.line(grayImg, (0, height/2), (width, height/2),(0, 255, 0), 2)#画出扫描的行
#显示图像
cv2.imshow("origin", img)
cv2.imshow("result", grayImg)
key = cv2.waitKey(0)
if key == 27:
cv2.destroyAllWindows()
第二种编码的程序
#-*- coding:utf-8 -*-
from PIL import Image
def clean(img):
A = img.load()
print A
ss = ''
for x in xrange(img.size[0]):
ss += str(A[x, img.size[1]/2])
print ss
ls = []
while len(ss) > 0:
start = ss[0]
j = 1
while j < len(ss) and ss[j] == start :
j += 1
ls.append(j)
ss = ss[j:]
print ls
return ls
#print ls
def GetUPC_A(t):
#print t
t = t[4:-4]
print len(t)
for i in xrange(len(t)):
t[i] = (t[i] + 1) / 4
t = t[:24] + t[29:]
s = ''
for i in xrange(len(t)):
s += str(t[i])
upca = ''
for i in range(0, len(s) / 4):
n = i * 4
upca += dic[s[n:n + 4]]
print upca
dic = {'3211':'0', '2221':'1', '2122':'2', '1411':'3', '1132':'4', '1231':'5', '1114':'6', '1312':'7', '1213':'8', '3112':'9'}
img = Image.open('7.png')
GetUPC_A(clean(img))
可惜这次遇到的是快递单上的条形码,非标准的EAN13条形码,暂时还不清楚这条形码的编码方式,所以换一个思路来识别快递单号,直接识别快递单上的数字快递单号
这里我用OCR引擎来识别,用的是Tesseract-OCR引擎
Tesseract-OCR引擎简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
(由Google管理,所以下载地址“被墙”了,这里就不贴了)
还有一个模块就是 pytesseract 这包是对Google Tesseract的一层python封装需要配合 PIL 模块使用
所以此次识别快递单号,用到三个
- Tesseract-OCR ——(直接下载一个exe文件一路”next”即可安装完成)
- pytesseract模块——(直接 pip install pytesseract 安装即可)
- PIL模块——(由于我的是win7_64bit的系统,原PIL不支持,所以用pillow模块,直接pip install pillow即可)
源代码
#-*- coding:utf-8 -*-
from PIL import Image
import pytesseract
import time
start = time.clock()#开始计时
#---------主要代码------------
im = Image.open('66.png')
code = pytesseract.image_to_string(im)
print u'验证码:' + str(code)
#---------------------------------
end = time.clock()#结束计时
print u'运行时间:' + str(end-start)
有坑
在有 Git Bash调试时遇到了
Traceback (most recent call last): File "111.py", line 10, in <module> print u'验证码:' + str(code) UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
这一看就有事编码的坑了,我用的是python2.7 估计生3就没没坑了
但目前还是要解决这问题,对于这编码的问题有两种解决方法:
1.一个解决的方案在程序中加入以下代码:
import sys
reload(sys)
sys.setdefaultencoding('utf8')
2.是在python的Lib\site-packages文件夹下新建一个sitecustomize.py,内容为:
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
此时重启python解释器,执行sys.getdefaultencoding(),发现编码已经被设置为utf8的了,多次重启之后,效果相同,这是因为系统在python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动的加上解决代码,属于一劳永逸的解决方法。
您可能感兴趣的文章:
加载全部内容