python写程序统计词频的方法
人气:0在李笑来所著《时间当作朋友》中有这么一段:
可问题在于,当年我在少年宫学习计算机程序语言的时候,怎么可能想象得到,在20多年后的某一天,我需要先用软件调取语料库中的数据,然后用统计方法为每个单词标注词频,再写一个批处理程序从相应的字典里复制出多达20MB的内容,重新整理……
在新书《自学是门手艺》中,他再次提及:
又过了好几年,我去新东方教书。2003 年,在写词汇书的过程中,需要统计词频,C++ 倒是用不上,用之前学过它的经验,学了一点 Python,写程序统计词频 ——《TOEFL 核心词汇 21 天突破》到今天还在销售。一个当年 10 块钱学费开始学的技能,就因为这本书,这些年给我 “变现” 了很多钱。
正在通过xue.cn 自学 python 的我顺手在 trello 中给自己添加一张卡片: 要不用 python 写个统计词频的脚本玩玩? 这是前不久的事儿了。
今日周末,我翻出这张卡片,打算实践看看。下文是我写词频统计脚本时的一些思考与实践成果。
2、如何把难题拆解为小CASE?
从需求来看,“统计词频的脚本”是一个泛泛的需求。——我并不是想要统计特定内容的词频,我希望生成的脚本可以处理各式内容。这对脚本的最终交付成果提出了高要求。
如果请你用 python 写个统计词频的脚本,你会如何写呢?当我正襟危坐,正视这道题目时,第一秒钟感知到了为难与胆怯。有个小人儿在脑袋里说:“好难,我做不到吧?”
面对新事物、新挑战,人们善于用想象力把困难放的很大。而我已经有了多次迎难而上的经验,于是我喝了一口苦咖啡,问自己:
从哪儿下手呢?不如进一步拆解来看看吧。
需求拆解如下:
“统计词频的脚本”,可以拆分为2个部分,a) 有哪些词?b) 统计这些词出现的次数。 b是简单的。 a分为2种情况:i) 给定词库;ii) 自己从内容中找词。 i是简单的,ii则可能复杂。
此时你可能问,你是如何判断简单还是复杂?简单吖,根据自己的编程能力与经验,预判自己能否写出代码。
需求经过拆解后,当前的重点聚焦于:
如何从内容中抓取词?
其中,内容是一个宽泛的概念。在程序中,它可能是:string 常量,文件,网页,api 返回的数据如此等等。关键是什么呢?关键是脚本的一线代码们处理的是 string,列表或字典。其余的文件、网页、api 返回数据等,无非是数据的载体更为复杂,我已经掌握了把从它们那里获取数据,生成 string、列表或字典的能力。而这个能力你也能很简单获得,即通过“python 如何读取文件数据”之类句式,从搜索引擎中找到答案。
一篇文章可以直接定义或读取为一个 string 常量。而 for i in stringcontent 句式能够帮我们遍历 string 统计单个字的词频。然后双字词、三字词、N字词等等,都可以由单字词拼接而成。
难点既然这么快想清楚,那么写代码实现吧!
3、从上帝视角调控成长体验
第一个版本代码如下图所示,还是非常简便的。我在同个目录下,另起一个 poem.py 文件用来把内容定义为常量,供该脚本调用。
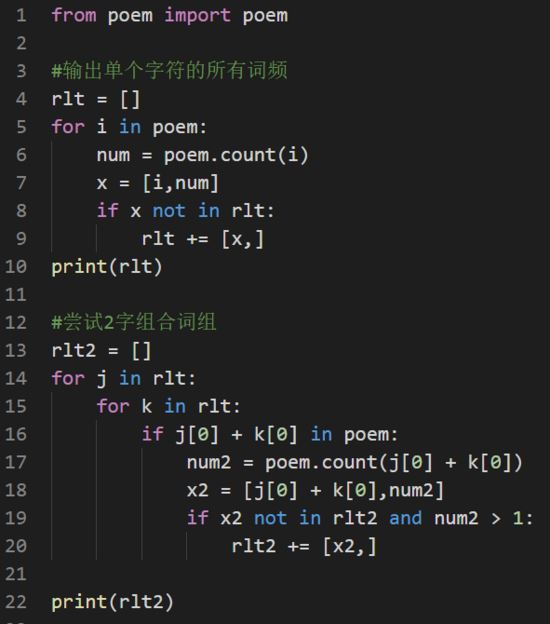
首次测试的string 常量 poem 是一首中文小诗,从常理来说,中文词汇包括汉字1、2、3、4个,超过 4 个的虽有但很少。顺着上面的思路,我继续把 3字词、4字词的代码也写出来了。运算结果正常。
我想试试复杂的。比如读取pdf文件。这涉及到一个我尚未掌握的新知识点:python如何读取pdf文件?获取答案也很容易,搜索然后尝试。
如果把“统计词频的python脚本”当作主线任务,那么“python如何读取pdf文件”就是分支任务啦。在这个分支任务上我立即遇到困难:使用 anaconda powshell prompt 安装第三方库时, pip install pdfminer 命令行执行了小段就报错。
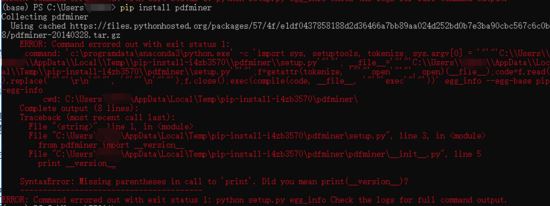
此时要么在支线任务中深究下去,要么回归主线任务。我选择回归主线任务,但顺手在 trello 上给自己建卡“python如何读取pdf文件”等以后专门来研究它。
现在,我继续专注于词频脚本。
除了内容载体的复杂,还可以有内容量的冗长。我拷贝了一篇几千字的中文文章,定义为 string 常量,然后用刚才调试通过的脚本统计词频。
在处理数百字的小诗时,脚本运行迅速,结果几乎立即被终端打印出来。而处理这篇长文时,终端打印完单字词、双字词的统计结果后,就一直没有输出,好似“卡”在那里。于是我强制结束脚本,在代码中添加了几条打印来检查程序是否正常运行中。由此发现了一个“性能”上的问题:电脑或编辑器,都没有卡住,程序运算持续在进行中,只是没有运算完成。
这篇长文,单字词几百条;按照我的上述代码逻辑,双字词运算 几百*几百 次,三字词运算 几百*几百 *几百 次,四字词运算 几百*几百 *几百 次。演算一下,具体是多少呢?
4字词运算次数:467758877041 次
四千六百多亿次!难怪迟迟没有结果输出!看来代码本身需要被修改优化,以降低计算量。第二个版本除了修改算法外,也调整了代码结构,使之更易于调试和增删。
在这个版本中,词频统计仅可用于中文,处理几千字的文章,大概需要1分钟左右。此时,一个下午已经过去了。再次久坐忘动的我,决定暂停休息一下,扭扭脖子甩甩胳膊。而且,很重要的一件事是, 把实践过程中的思考与第二个版本的脚本做一个阶段交付 。
不得不提的是, 写文章是一个提升阶段交付成就感的小策略 。这也是此文的由来。当然啦,我还要顺手在 trello 上给自己添加2张新卡片,等有精力时继续实践:
python如何统计英文文章词频? python统计中文词频的脚本处理十几万字的书籍时,性能如何?
在群里谈及我在写的词频脚本时,有位网友提出一个观点,“不是程序员,学编程没用”。我想,他肯定是没有读过李笑来的书,或者干脆读过,只是读成了另外一个版本吧!
如果你也在学习 python 或想要提高自学能力,欢迎来xue.cn 聊天室找我 @liujuanjuan1984 ~
def write_rlt(content,dic1,dic2):
rlt = {}#有该结果但并没有用上
rlts = {}
for i in dic1.keys():
for j in dic2.keys():
cix = i + j
if cix in content:
num = content.count(cix)
if cix not in rlt.keys():
rlt[cix]=num
if num > 1:
rlts[cix]=num
return rlts
def cipin_1(content):
rlt1 = {}
rlt1s = {}
for ci in content:
#r"[^\u4e00-\u9fa5^a-z^A-Z^0-9]"
atext ="""
\ \\\\n ,.,。/一()()<>《》
"""
if ci not in atext:
num = content.count(ci)
if ci not in rlt1.keys():
rlt1[ci]=num
if num > 1:
rlt1s[ci]=num
return rlt1s
def merge_dic(dic1,dic2):
rlt = dic1.copy()
rlt.update(dic2)
return rlt
def cipin_x(content,dic1,dic2):
rltsx = write_rlt(content,dic1,dic2)
rltsy = write_rlt(content,dic2,dic1)
rlts = merge_dic(rltsx,rltsy)
return rlts
def sorted_dic(dic1,txt=None):
rlt = sorted(dic1.items(),key=lambda x:x[1],reverse=True)
print("\n--------------------\n")
if txt==None:
atxt = "结果共"
else:
atxt = txt + "字词共"
print(atxt,len(rlt),"条,具体为:\n",rlt)
return rlt
def main():
from txt import zixue_x as content #加载想要统计的内容,string type
import datetime
print("---begin---",datetime.datetime.now())
rlt1s = cipin_1(content)
rlt2s = cipin_x(content,rlt1s,rlt1s)
rlt3s = cipin_x(content,rlt1s,rlt2s)
rlt4s = cipin_x(content,rlt1s,rlt3s)
rlt5s = cipin_x(content,rlt1s,rlt4s)
rlt6s = cipin_x(content,rlt1s,rlt5s)
rlt7s = cipin_x(content,rlt1s,rlt6s)
sorted_dic(rlt1s,"单")
sorted_dic(rlt2s,"双")
sorted_dic(rlt3s,"3")
sorted_dic(rlt4s,"4")
sorted_dic(rlt5s,"5")
sorted_dic(rlt6s,"6")
sorted_dic(rlt7s,"7")
print("---end---",datetime.datetime.now())
if __name__ == "__main__":
main()
这篇文章的 PRESS.one 签名: press.one/file/v?s=33…
总结
以上所述是小编给大家介绍的python写程序统计词频的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
您可能感兴趣的文章:
加载全部内容