python 的 openpyxl模块 读取 Excel文件的方法
人气:0Python 的 openpyxl 模块可以让我们能读取和修改 Excel 文件。

首先让我们先理解一些 Excel 基础概念。
1 Excel 基础概念
Excel 文件也称做为工作簿。每个工作簿可以包含多个工作表(Sheet)。用户当前查看的表或关闭 Excel 前最后查看的表,称为活动表。
每一张表都是由列和行构成的。列是以 A 开始的字母表示;而行是以 1 开始的数字表示的。由特定行和列所指定的方格称为单元格。每个单元格都可以包含一个数字或文本。这些单元格就构成了这张表。
2 安装 openpyxl
通过 pip 就可以安装最新版的 openpyxl。
pip install openpyxl
3 读取 Excel
假设有这样一份世界人口统计 Excel 文档,内容如下:
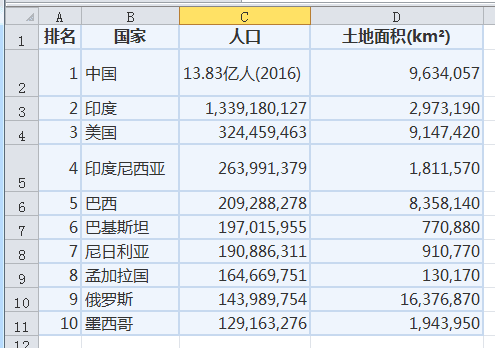
3.1 加载
wb = openpyxl.load_workbook('population.xlsx')
print('wb 类型 :')
print(type(wb), '\n')
运行结果:

wb 类型 : <class 'openpyxl.workbook.workbook.Workbook'>
导入 openpyxl 模块之后,就可以使用 openpyxl.load_workbook() 函数来加载 Excel 文档咯。这个 Excel 文件表示为 Workbook 对象。
注意:load_workbook() 函数中的文件,必须在当前工作目录。可以导入 os 模块,利用 os.getcwd() 来获悉当前工作目录。os 还提供了 chdir() 方法,可以改变当前工作目录。
import os
print('当前工作目录 :')
print(os.getcwd(), '\n')
运行结果:
3.2 读取 Excel 工作表(sheet)
...
print('取得所有工作表的表名 :')
print(wb.sheetnames, '\n')
print('取得某张工作表 :')
sheet = wb['Sheet3']
print(type(sheet))
print('表名 - ' + sheet.title, '\n')
print('取得活动工作表 :')
active_sheet = wb.active
print('表名 - ' + active_sheet.title, '\n')
运行结果:
取得所有工作表的表名 : ['Sheet1', 'Sheet2', 'Sheet3']
取得某张工作表 : <class 'openpyxl.worksheet.worksheet.Worksheet'> 表名 - Sheet3
取得活动工作表 : 表名 - Sheet1
- Workbook 对象的 sheetnames 属性可以获取所有 sheet 表的表名列表。
- Workbook 对象的 active 属性,会获取当前活动表,即打开 Excel 时出现的工作表。
- 获取 Worksheet 对象后,我们就可以通过 title 属性得到 sheet 的名称。
3.3 读取单元格 (Cell)
...
print('取得 A1 单元格 :')
cell = active_sheet['A1']
print(cell)
print(cell.value, '\n')
print('取得 B1 单元格 :')
cell = active_sheet['B1']
print(cell)
print(cell.value, '\n')
print('行号为 ' + str(cell.row) + ',列号为 ' + str(cell.column) + ' 的单元格,其值为 ' + cell.value, '\n')
print('单元格 ' + cell.coordinate + ' 其值为 ' + cell.value, '\n')
print('取得 C1 单元格的值 :')
print(active_sheet['C1'].value, '\n')
print('通过指定行与列,来获取单元格:')
print(active_sheet.cell(row=1, column=2))
print(active_sheet.cell(row=1, column=2).value)
print('迭代行与列,来获取单元格的值:')
for i in range(1, 8, 2):
print(i, active_sheet.cell(row=i, column=2).value)
print('\n')
运行结果:
取得 A1 单元格 : <Cell 'Sheet1'.A1> 排名
取得 B1 单元格 : <Cell 'Sheet1'.B1> 国家
行号为 1,列号为 2 的单元格,其值为 国家
单元格 B1 其值为 国家
取得 C1 单元格的值 : 人口
通过指定行与列,来获取单元格: <Cell 'Sheet1'.B1> 国家 迭代行与列,来获取单元格的值: 1 国家 3 印度 5 印度尼西亚 7 巴基斯坦
可以通过单元格的名字(比如:A1)来获取 Cell 对象。
- Cell 对象的 value 属性,存放的是该单元格中所保存的值。
- Cell 对象的 row、 column 和 coordinate 属性,存放的是该单元格的位置信息。
- 用字母来指定列比较奇怪,因此我们也可以通过 sheet 的 cell 方法直接指定行(row)与列(column),来获取单元格 Cell 对象。
3.4 获取工作表大小
print('获取工作表的大小:')
print('总行数 -> ' + str(active_sheet.max_row))
print('总列数 -> ' + str(active_sheet.max_column))
运行结果:
获取工作表的大小: 总行数 -> 11 总列数 -> 4
Worksheet 对象的 max_row 与 max_column,可以获取工作表的总行数与总列数,即工作表的大小。
3.5 列转换函数
openpyxl 提供了两个函数,用于转换列号:
- openpyxl.utils.get_column_letter -> 会把数字转化为字母。
- openpyxl.utils.column_index_from_string -> 会把字母转化为数字。
import openpyxl
from openpyxl.utils import get_column_letter, column_index_from_string
...
print('列转换函数:')
print('[数字转换为字母]')
print('第 1 列 -> ' + get_column_letter(1))
print('第 2 列 -> ' + get_column_letter(2))
print('第 37 列 -> ' + get_column_letter(37))
print('第 818 列 -> ' + get_column_letter(818))
print('[字母转换为数字]')
print('第 A 列 -> ' + str(column_index_from_string('A')))
print('第 CC 列 -> ' + str(column_index_from_string('CC')))
运行结果:
[数字转换为字母] 第 1 列 -> A 第 2 列 -> B 第 37 列 -> AK 第 818 列 -> AEL [字母转换为数字] 第 A 列 -> 1 第 CC 列 -> 81
3.6 切片
我们可以对 Worksheet 对象切片,取得表格中的一个矩形区域,迭代遍历这个区域中的所有 Cell 对象。
print(tuple(active_sheet['A2':'D4']))
for row_objects in active_sheet['A2':'D4']:
for cell_object in row_objects:
print(cell_object.coordinate, cell_object.value)
print('-- 当前行获取结束 --')
运行结果:
((<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>, <Cell 'Sheet1'.D2>), (<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>, <Cell 'Sheet1'.D3>), (<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>, <Cell 'Sheet1'.D4>)) A2 1 B2 中国 C2 13.83亿人(2016) D2 9634057 -- 当前行获取结束 -- A3 2 B3 印度 C3 1339180127 D3 2973190 -- 当前行获取结束 -- A4 3 B4 美国 C4 324459463 D4 9147420 -- 当前行获取结束 --
- 这里首先通过 tuple() 方法,展示出了切片后的所有 Cell 对象。
- 然后使用了两个 for 循环,外层 for 循环会遍历这个切片中的每一行;而内层 for 循环会遍历该行中的每个单元格。
3.7 获取指定行或指定列
我们可以使用 Worksheet 对象的 rows 和 columns 属性,来获取指定行或者列:
print('获取特定行:')
print(list(active_sheet.rows)[2])
for cell_object in list(active_sheet.rows)[2]:
print(cell_object.value)
print('获取特定列:')
print(list(active_sheet.columns)[2])
for cell_object in list(active_sheet.columns)[2]:
print(cell_object.value)
运行结果:
获取特定行: (<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>, <Cell 'Sheet1'.D3>) 2 印度 1339180127 2973190 获取特定列: (<Cell 'Sheet1'.C1>, <Cell 'Sheet1'.C2>, <Cell 'Sheet1'.C3>, <Cell 'Sheet1'.C4>, <Cell 'Sheet1'.C5>, <Cell 'Sheet1'.C6>, <Cell 'Sheet1'.C7>, <Cell 'Sheet1'.C8>, <Cell 'Sheet1'.C9>, <Cell 'Sheet1'.C10>, <Cell 'Sheet1'.C11>) 人口 13.83亿人(2016) 1339180127 324459463 263991379 209288278 197015955 190886311 164669751 143989754 129163276
- Worksheet 对象的 rows 或者 columns 属性,都会返回一个由 “行元组” 构成的元组。每个行元组都拥有该行中的所有 Cell 对象。
- 可以通过行元组的下标,来访问具体的 Cell 对象。
读取 Excel 步骤,总结如下:
- 导入 openpyxl 模块。调用 openpyxl.load_workbook() 函数,加载 excel 文档,获取 Workbook 对象。
- 调用 workbook#active 或 workbook[${sheet_name}],获取 sheet 工作簿。
- 传入 row 和 column 关键字参数并调用索引或工作表的 cell() 方法,获取 Cell 对象。
- 有了 Cell 对象,就可以执行具体的业务逻辑咯。
总结
以上所述是小编给大家介绍的python 的 openpyxl模块 读取 Excel文件的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
您可能感兴趣的文章:
加载全部内容