Emoji表情在Android JNI中的兼容性问题详解
人气:0起因
最近遇到一个问题,把某个字符串计算MD5,之后把该字符串加密与MD5一起上传到服务端,服务端解密后重新计算md5发现与上传的MD5不一致,而出问题的字符串中无一例外都有Emoji表情。但我自己弄个带表情的字符串上传却没有什么问题。
最终确认这是在Android 5.1以下 jstring -> char数组 时出的问题。下面通过一个示例来还原这个过程。
事件还原
假设有一个字符串s,String s = "\uD83D\uDC8B"; ,对应表情💋。通过调用getBytes()方法,会看到对应的byte数组为[-16, -97, -110, -117] ,按16进制输出为[f0, 9f, 92, 8b] 。
定义一个参数为String的native方法,public native String test(String str); ,在对应的C/C++代码中,通过env->GetStringUTFChars获取传入的String对应的char数组,把char数组的每一个元素按16进制输出。
在Android 7.1.2的测试机上,native层输出的结果为[f0, 9f, 92, 8b] ,与Java的byte数组是一样的,但是在Android 4.4.4的测试机上,输出结果为[ed, a0, bd, ed, b2, 8b] 。从而导致加密后的结果不一样。
服务端收到旧版Android的数据解密后得到[ed, a0, bd, ed, b2, 8b] ,计算MD5自然无法与[f0, 9f, 92, 8b]计算MD5一样。
Unicode、UTF-8、UTF-16
可能有人不是很清楚上面那2种byte数组是怎么来的。首先我们要知道,UTF-8和UTF-16都是Unicode的实现。\uD83D\uDC8B其实是UTF-16大端的表现形式,对于大于0xFFFF(0x10000~0x10FFFF)的Unicode,转换为UTF-16的步骤如下:
- 将Unicode减去0x10000,结果将是一个长度为20bit的值。
- 将第一步的20bit的高10bit与0xD800进行或运算,得到UTF-16的高位代理。
- 将第一步的20bit的低10bit与0xDC00进行或运算,得到UTF-16的低位代理。
- 高位代理+低位代理即Unicode对应的UTF-16的大端形式。
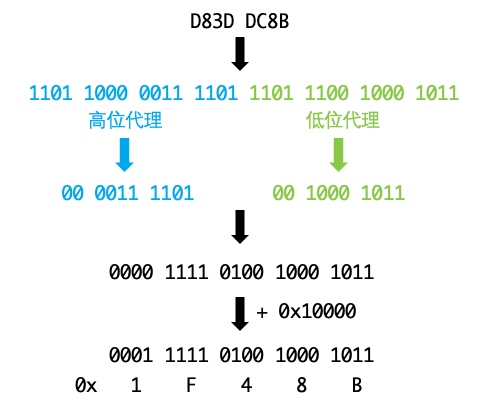
按照这个步骤反推:
- \uD83D\uDC8B的二进制位1101 1000 0011 1101 1101 1100 1000 1011,则高位代理为1101 1000 0011 1101,低位代理为1101 1100 1000 1011。
- 高位代理由高10bit与0xD800进行或运算得到,因此高10bit为00 0011 1101。
- 低位代理由低10bit与0xDC00进行或运算得到,因此低10bit为00 1000 1011。
- 所有20bit的值为0000 1111 0100 1000 1011。
- 加上0x10000,为0001 1111 0100 1000 1011,即0x1F48B。
所以,表情💋对应的Unicode为0x1F48B。
UTF-8的规则是,对于占N个字节的符号(N>1),第一个字节前N位都是1,N+1位是0,后面的字节前2位为10,然后把Unicode的二进制位填入空缺的二进制位中,空出的位置补0。因此,上面的Unicode 0x1F48B转为UTF-8需要占4个字节,为:
11110 000
10 011111
10 010010
10 001011
即0xF09F928B,这也就是[f0, 9f, 92, 8b]这个byte数组的由来。

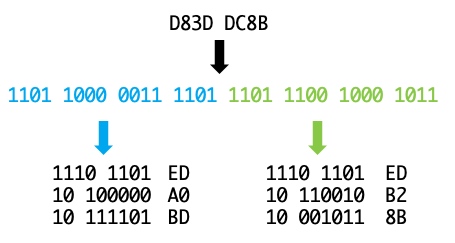
那么[ed, a0, bd, ed, b2, 8b]这个byte数组又是怎么来的呢?这是把\uD83D\uDC8B当成2个单独的字符处理了,按照上面Unicode转UTF-8的逻辑,Unicode 0xD83D转为UTF-8为1110 1101 10 100000 10 111101,即0xEDA0BD,Unicode 0xDC8B转为UTF-8为1110 1101 10 110010 10 001011,即0xEDB28B。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。
您可能感兴趣的文章:
加载全部内容