通过字符串导入 Python 模块的方法详解
人气:0我们平时导入第三方模块的时候,一般使用的是 import 关键字,例如:
import scrapy from scrapy.spider import Spider
但是如果各位同学看过 Scrapy 的 settings.py 文件,就会发现里面会通过字符串的方式来指定pipeline 和 middleware,例如:
DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.ExceptionRetryMiddleware': 545,
'Test.middlewares.BOProxyMiddlewareV2': 543,
}
SPIDER_MIDDLEWARES = {
'Test.middlewares.LoggingRequestMiddleware': 543,
}
我们知道,这里的 Test.middlewares.ExceptionRetryMiddleware 实际上对应了根目录下面的 Test 文件夹里面的 middlewares.py 文件中的 ExceptionRetryMiddleware 类。那么 Scrapy 是如何根据这个字符串,导入这个类的呢?
在 Scrapy 源代码中,我们可以找到 相关的代码 :
def load_object(path):
"""Load an object given its absolute object path, and return it.
object can be a class, function, variable or an instance.
path ie: 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'
"""
try:
dot = path.rindex('.')
except ValueError:
raise ValueError("Error loading object '%s': not a full path" % path)
module, name = path[:dot], path[dot+1:]
mod = import_module(module)
try:
obj = getattr(mod, name)
except AttributeError:
raise NameError("Module '%s' doesn't define any object named '%s'" % (module, name))
return obj
根据这段代码,我们知道,它使用了 importlib 模块的 import_module 函数:
首先根据字符串路径最右侧的 . 把字符串路径分成两个部分,例如: Test.middlewares.LoggingRequestMiddleware 分成 Test.middlewares 和 LoggingRequestMiddleware
使用 import_module 导入左边的部分
从左边部分通过 getattr 获得具体的类
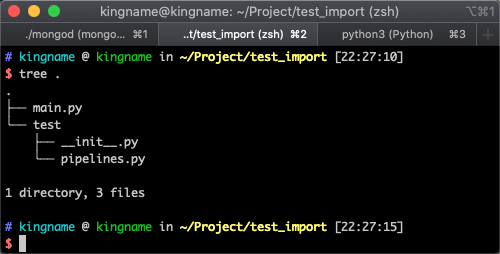
现在我们来测试一下。我们创建的测试文件结构如下图所示:
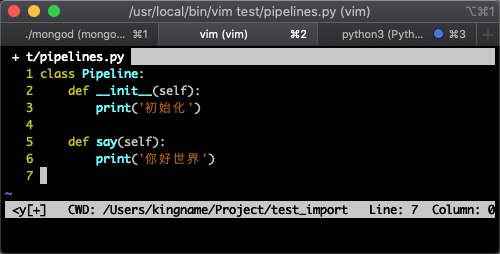
其中, pipelines.py 文件的内容如下图所示:
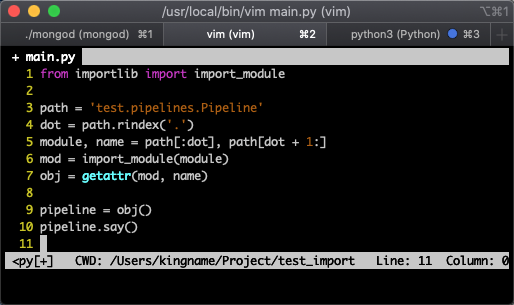
main.py 文件的内容如下图所示:
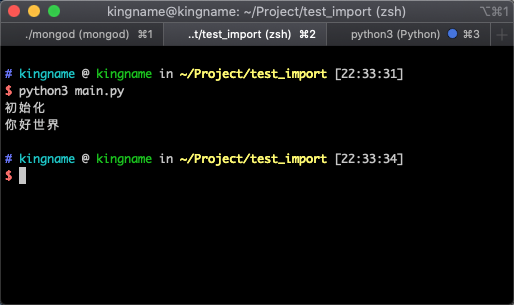
运行 main.py ,可以看到 pipelines.py 中的 Pipeline 类被成功执行了,如下图所示:
总结
以上所述是小编给大家介绍的通过字符串导入 Python 模块的方法详解,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
您可能感兴趣的文章:
加载全部内容