python基于K-means聚类算法的图像分割
人气:01 K-means算法
实际上,无论是从算法思想,还是具体实现上,K-means算法是一种很简单的算法。它属于无监督分类,通过按照一定的方式度量样本之间的相似度,通过迭代更新聚类中心,当聚类中心不再移动或移动差值小于阈值时,则就样本分为不同的类别。
1.1 算法思路
- 随机选取聚类中心
- 根据当前聚类中心,利用选定的度量方式,分类所有样本点
- 计算当前每一类的样本点的均值,作为下一次迭代的聚类中心
- 计算下一次迭代的聚类中心与当前聚类中心的差距
- 如4中的差距小于给定迭代阈值时,迭代结束。反之,至2继续下一次迭代
1.2 度量方式
根据聚类中心,将所有样本点分为最相似的类别。这需要一个有效的盘踞,平方差是最常用的度量方式,如下

2 应用于图像分割
我们知道:无论是灰度图还是RGB彩色图,实际上都是存有灰度值的矩阵,所以,图像的数据格式决定了在图像分割方向上,使用K-means聚类算法是十分容易也十分具体的。
2.1 Code
导入必要的包
import numpy as np import random
损失函数
def loss_function(present_center, pre_center): ''' 损失函数,计算上一次与当前聚类中的差异(像素差的平方和) :param present_center: 当前聚类中心 :param pre_center: 上一次聚类中心 :return: 损失值 ''' present_center = np.array(present_center) pre_center = np.array(pre_center) return np.sum((present_center - pre_center)**2)
分类器
def classifer(intput_signal, center):
'''
分类器(通过当前的聚类中心,给输入图像分类)
:param intput_signal: 输入图像
:param center: 聚类中心
:return: 标签矩阵
'''
input_row, input_col= intput_signal.shape # 输入图像的尺寸
pixls_labels = np.zeros((input_row, input_col)) # 储存所有像素标签
pixl_distance_t = [] # 单个元素与所有聚类中心的距离,临时用
for i in range(input_row):
for j in range(input_col):
# 计算每个像素与所有聚类中心的差平方
for k in range(len(center)):
distance_t = np.sum(abs((intput_signal[i, j]).astype(int) - center[k].astype(int))**2)
pixl_distance_t.append(distance_t)
# 差异最小则为该类
pixls_labels[i, j] = int(pixl_distance_t.index(min(pixl_distance_t)))
# 清空该list,为下一个像素点做准备
pixl_distance_t = []
return pixls_labels
基于k-means算法的图像分割
def k_means(input_signal, center_num, threshold):
'''
基于k-means算法的图像分割(适用于灰度图)
:param input_signal: 输入图像
:param center_num: 聚类中心数目
:param threshold: 迭代阈值
:return:
'''
input_signal_cp = np.copy(input_signal) # 输入信号的副本
input_row, input_col = input_signal_cp.shape # 输入图像的尺寸
pixls_labels = np.zeros((input_row, input_col)) # 储存所有像素标签
# 随机初始聚类中心行标与列标
initial_center_row_num = [i for i in range(input_row)]
random.shuffle(initial_center_row_num)
initial_center_row_num = initial_center_row_num[:center_num]
initial_center_col_num = [i for i in range(input_col)]
random.shuffle(initial_center_col_num)
initial_center_col_num = initial_center_col_num[:center_num]
# 当前的聚类中心
present_center = []
for i in range(center_num):
present_center.append(input_signal_cp[initial_center_row_num[i], initial_center_row_num[i]])
pixls_labels = classifer(input_signal_cp, present_center)
num = 0 # 用于记录迭代次数
while True:
pre_centet = present_center.copy() # 储存前一次的聚类中心
# 计算当前聚类中心
for n in range(center_num):
temp = np.where(pixls_labels == n)
present_center[n] = sum(input_signal_cp[temp].astype(int)) / len(input_signal_cp[temp])
# 根据当前聚类中心分类
pixls_labels = classifer(input_signal_cp, present_center)
# 计算上一次聚类中心与当前聚类中心的差异
loss = loss_function(present_center, pre_centet)
num = num + 1
print("Step:"+ str(num) + " Loss:" + str(loss))
# 当损失小于迭代阈值时,结束迭代
if loss <= threshold:
break
return pixls_labels
3 分类效果

聚类中心个数=3,迭代阈值为=1
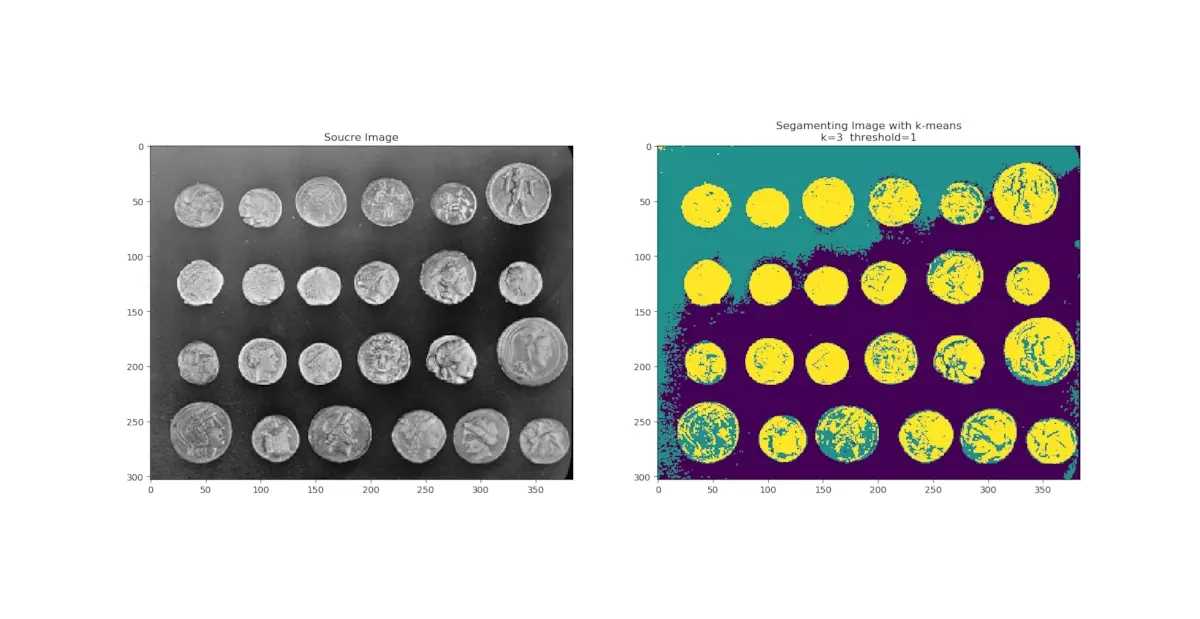
聚类中心个数=3,迭代阈值为=1
4 GitHub
您可能感兴趣的文章:
加载全部内容